Ketika saya pertama kali melihat pada @OpenLedger 's Proof of Attribution, saya berpikir bahwa masalah utama adalah keadilan. Bayar orang-orang yang memberikan data berguna, dan sistemnya akan semakin jujur. Tapi pandangan itu terasa terlalu sederhana sekarang.
Pertanyaan yang lebih sulit bukan siapa yang berkontribusi. Pertanyaan yang lebih sulit adalah kontribusi siapa yang sebenarnya mengubah jawabannya.
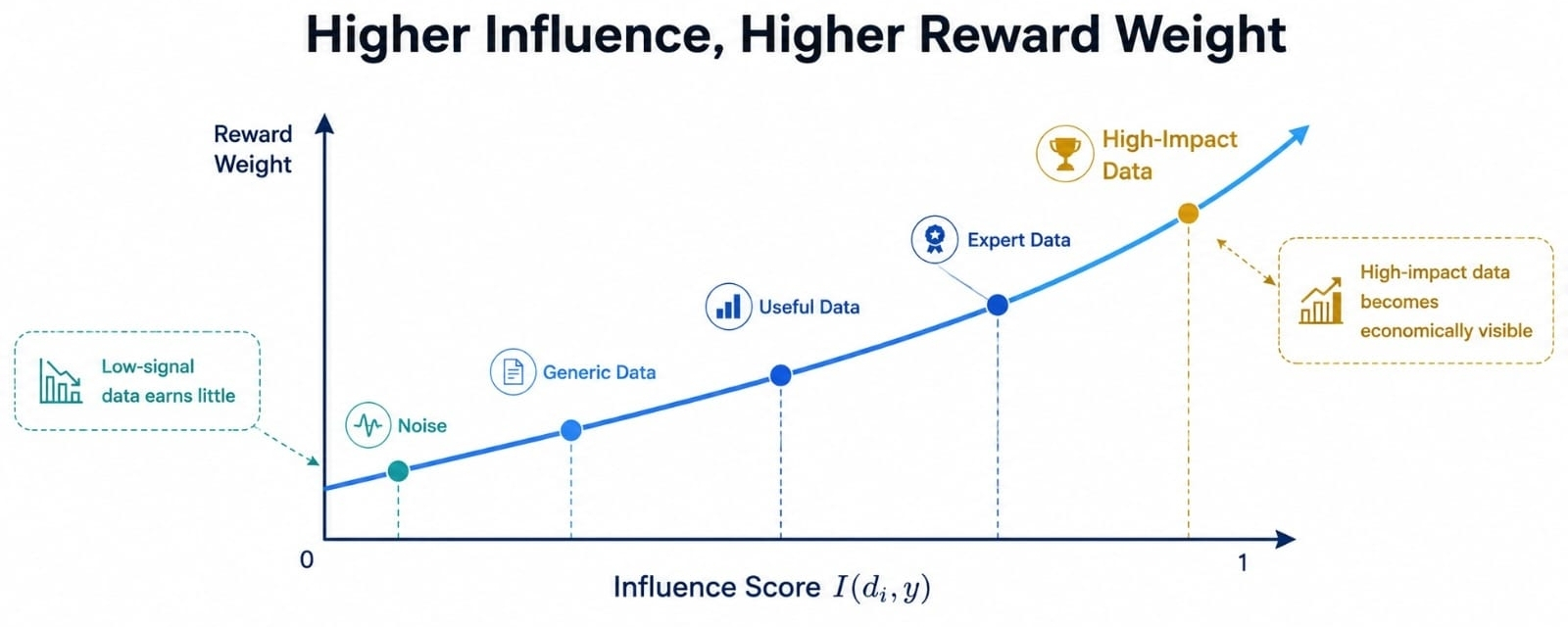
Di sinilah skor pengaruh I(di, y) menjadi penting. Dengan kata lain, di berarti satu titik data, y berarti satu output model, dan I mengukur seberapa besar titik data itu membentuk output spesifik tersebut. Ini mengubah atribusi dari klaim kepemilikan yang luas menjadi masalah pengukuran yang lebih sempit.
Di permukaan, seorang contributor mengunggah data ke dalam DataNet dan menunggu nilai kembali. Di bawahnya, sistem harus menanyakan apakah data itu hanya ada di lingkungan pelatihan atau apakah data tersebut memiliki bobot nyata ketika model menghasilkan hasil.
Perbedaan itu sunyi, tetapi mengubah logika reward sepenuhnya.
Jika 100 contributor menyediakan data, model reward datar mungkin memperlakukan partisipasi sebagai nilai. Itu menciptakan insentif yang lemah. Orang dapat mengejar volume, menduplikasi materi, atau mengirimkan data sinyal rendah yang terlihat aktif tetapi tidak meningkatkan model di bawah tekanan.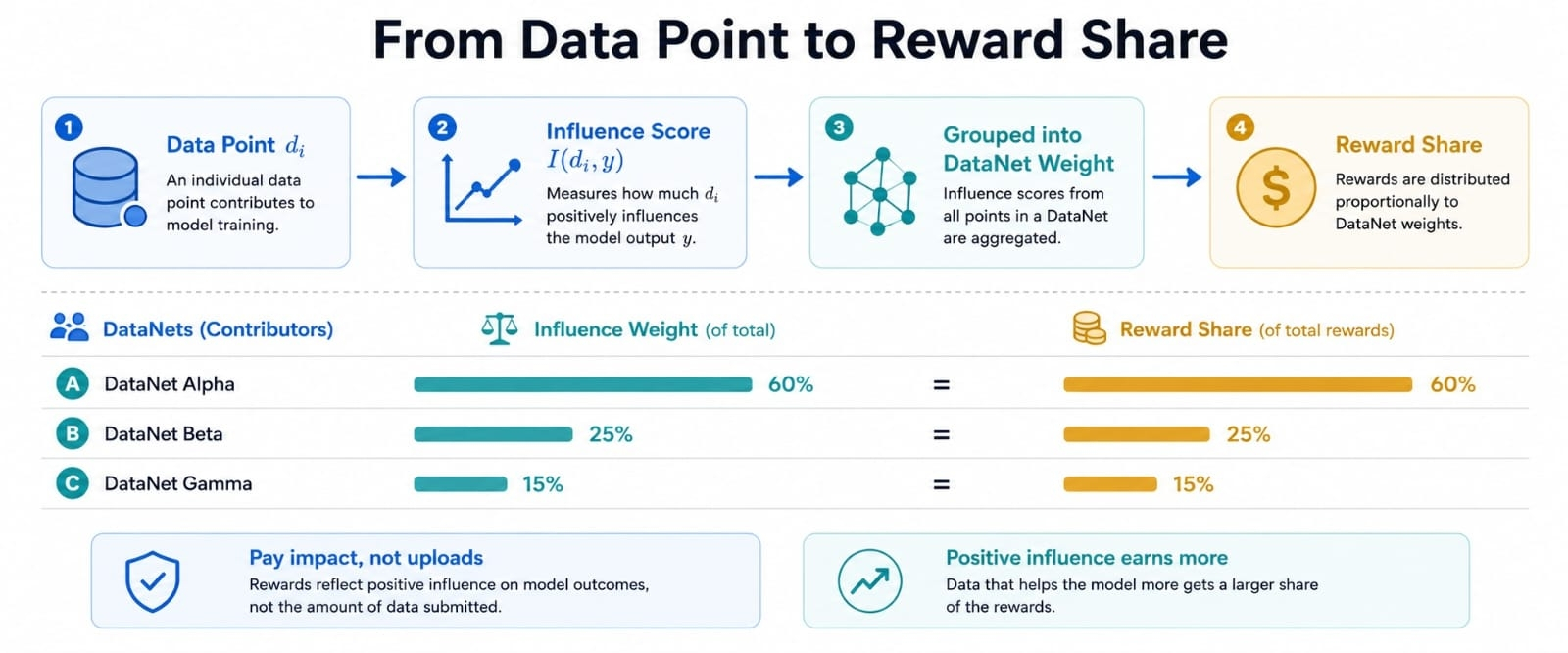
I(di, y) menantang itu. Ia meminta pengaruh, bukan kebisingan. Jika satu titik data meningkatkan kepercayaan, relevansi, atau akurasi untuk sebuah output, itu harus mendapatkan bobot lebih daripada sepuluh poin generik yang berada di dekatnya tetapi tidak terlalu berarti.
Memahami itu membantu menjelaskan mengapa matematika atribusi lebih dari sekadar alat pembayaran. Ia juga merupakan filter insentif. Seorang contributor tidak diberi reward hanya karena data mereka masuk ke sistem. Mereka diberi reward karena data mereka masih muncul dalam perilaku model.
Pemisahan reward yang sederhana menunjukkan ide ini. Jika satu DataNet membawa 60 persen dari pengaruh yang diukur untuk output yang berharga dan yang lainnya membawa 40 persen, maka reward bisa bergerak sesuai proporsi itu daripada ditebak secara manual. Angka ini bukan hanya akuntansi. Ini adalah cara untuk membuat kontribusi lebih sulit untuk dipalsukan.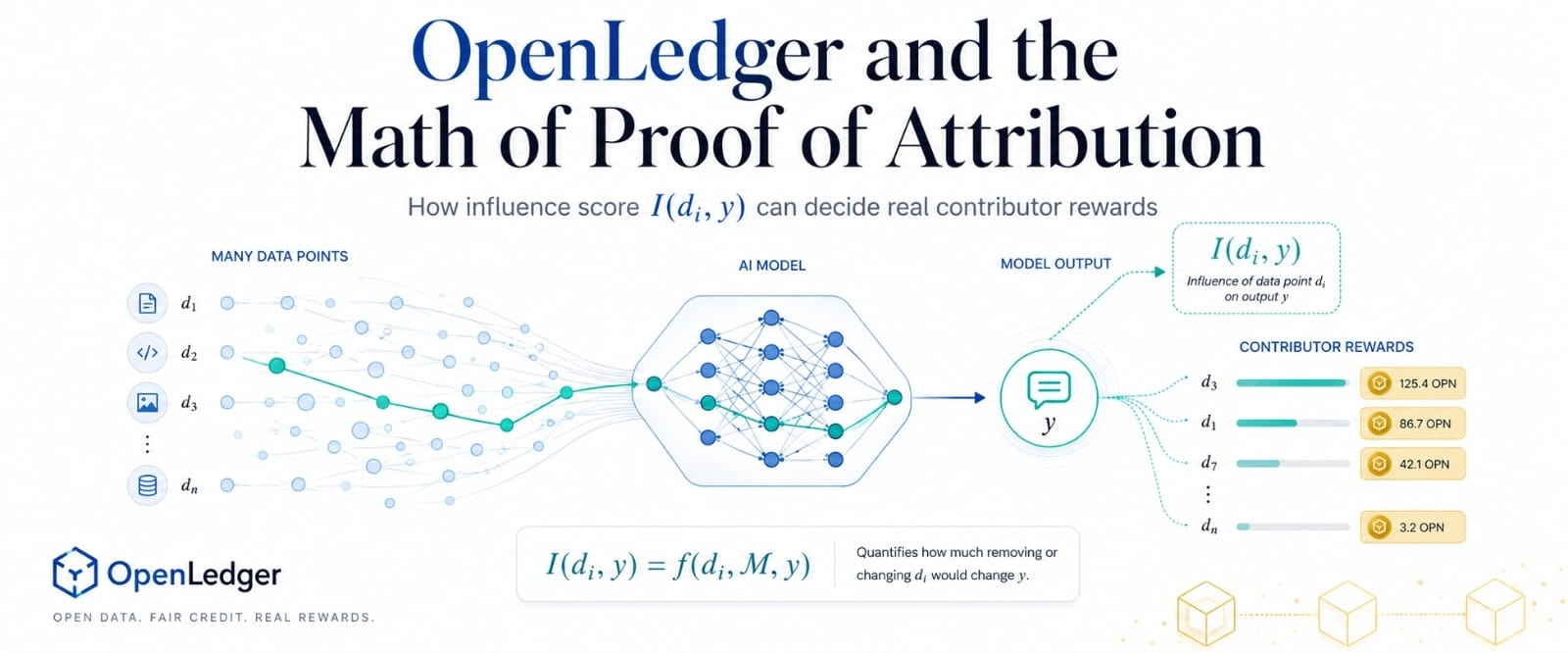
Itu menciptakan masalah lain. Skor pengaruh bisa terlihat lebih bersih daripada kenyataan. Output AI sering dibentuk oleh data yang tumpang tindih, pola yang berulang, dan sinyal yang tidak langsung. Skor tinggi mungkin mencerminkan kegunaan yang sebenarnya, tetapi juga bisa mencerminkan penghapusan, duplikasi, atau data yang dirancang untuk memicu atribusi.
Jadi versi terkuat OpenLedger tidak dapat bergantung hanya pada I(di, y). Ia membutuhkan catatan, hash, cap waktu, deduplikasi, validasi, dan tata kelola sekitar ambang batas. Rumus ini dapat mengukur tekanan, tetapi sistem tetap harus memutuskan tingkat pengaruh mana yang layak mendapatkan pembayaran.
Masalah yang lebih sunyi adalah kepercayaan. Begitu reward nyata terikat, setiap skor menjadi dasar ekonomi. Para contributor akan menguji batas. Tata kelola akan menghadapi sengketa. Pasar akan menanyakan apakah lapisan atribusi cukup dapat diprediksi untuk menilai kontribusi dengan adil.
Jika ini berlaku, #OpenLedger tidak hanya membangun sistem reward untuk data AI. Ini menguji apakah kontribusi AI dapat menjadi infrastruktur yang terukur.
Prestasi nyata bukanlah membuktikan bahwa data ada. Melainkan membuktikan bahwa data itu penting.

