Lúc đầu mình đọc tin OpenLedger hợp tác với Story Protocol khá bình thường.
Một partnership nữa. Một dòng nữa trong ecosystem map. Story Protocol lo IP. OpenLedger lo attribution và payment. Ghép lại nghe hợp lý, nhất là khi câu chuyện bản quyền AI ngày càng căng.
Nhưng càng nghĩ, mình càng thấy nếu chỉ đọc đây là “tính năng compliance” thì hơi thấp.
Vấn đề của AI không chỉ là thiếu một bản ghi bản quyền đẹp. Một tác phẩm được cấp phép nhưng không ai dùng để train model thì vẫn chỉ nằm yên. Một dataset hợp pháp nhưng không có demand từ model builder thì cũng không tạo ra thị trường.
Điểm quan trọng nằm ở thanh khoản tri thức.
OpenLedger x Story Protocol chỉ thật sự đáng giá nếu biến dữ liệu hợp pháp thành thứ có thể được dùng, định giá và trả tiền liên tục. Không phải một file tĩnh. Không phải một dòng log để phòng khi bị audit. Mà là một loại tài sản IP sinh lời.
Đây là chỗ hai dự án khớp với nhau khá tự nhiên.
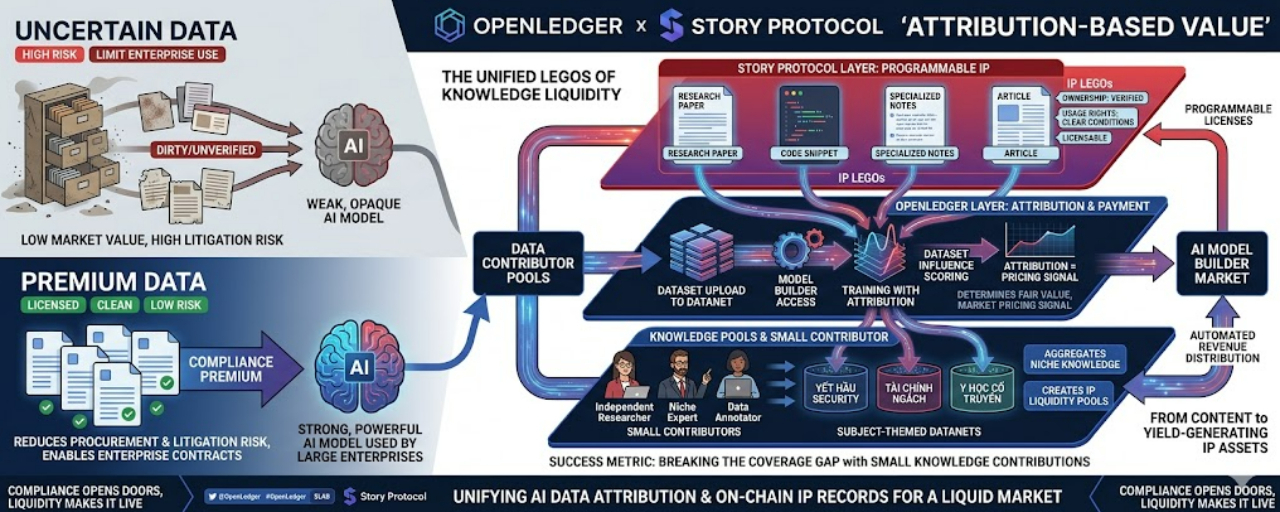
Story Protocol có lớp IP có thể lập trình: ai sở hữu gì, quyền sử dụng ra sao, điều kiện license thế nào. OpenLedger có lớp attribution: dữ liệu nào được dùng, đóng góp nào tạo ảnh hưởng, dòng value nên quay về đâu.
Khi ráp hai thứ đó lại, một bài viết, một đoạn code, một ảnh, một bộ ghi chú chuyên ngành không còn chỉ là “nội dung”. Nó có thể trở thành một IP Lego: một mảnh tri thức có điều kiện sử dụng rõ ràng, có thể được model builder thuê để train, và có thể tạo dòng tiền ngược về người sở hữu mỗi khi model tạo ra value.
Đây là điểm khác biệt lớn.
Model builder không nhất thiết phải mua đứt dữ liệu. Họ có thể dùng dữ liệu theo license đã được lập trình sẵn. Rights holder cũng không cần ngồi chờ một hợp đồng thủ công. Nếu dữ liệu của họ thật sự ảnh hưởng đến model output, payment có thể quay về theo attribution.
Lúc đó attribution không còn là log.
Nó trở thành pricing signal.
Một nguồn IP được dùng nhiều trong inference phải có giá khác với một nguồn gần như không tạo ảnh hưởng. Một dataset giúp model tốt hơn thật không nên chỉ là một dòng trong hồ sơ. Nó phải được thị trường trả giá cao hơn.
Đây cũng là nơi xuất hiện thứ mình nghĩ sẽ rất quan trọng: compliance premium.
Thị trường AI có thể sẽ tách ra thành hai lớp. Một lớp model rẻ hơn, train bằng dữ liệu mập mờ, khó chứng minh nguồn gốc, dùng được trong môi trường thử nghiệm nhưng rất khó bán cho enterprise lớn. Và một lớp model sạch hơn, có license rõ, có attribution rõ, ít rủi ro pháp lý hơn, đủ tự tin để bước vào hợp đồng doanh nghiệp.
Lớp thứ hai có thể đắt hơn.
Nhưng enterprise có lý do để trả phần chênh lệch đó.
Không phải vì họ thích on-chain. Mà vì họ muốn giảm rủi ro kiện tụng, giảm rủi ro procurement, giảm rủi ro phải gỡ model sau khi đã tích hợp vào hệ thống thật.
Vậy nên OpenLedger x Story Protocol không chỉ tạo “dữ liệu hợp pháp”. Nếu chạy đúng, nó tạo ra một premium data market: nơi dữ liệu sạch có thể được định giá cao hơn vì nó mở được nhóm khách hàng mà dữ liệu bẩn không chạm tới.
Nhưng bài toán khó nhất không nằm ở ý tưởng này.
Nó nằm ở coverage gap.
Nếu chỉ publisher lớn, studio lớn, hoặc tổ chức có team legal mới đăng ký được IP, thị trường này sẽ rất hẹp. Nó có giá trị, nhưng không đủ sâu. Trong khi AI chuyên ngành lại cần rất nhiều tri thức ngách: researcher nhỏ, tác giả độc lập, chuyên gia domain, người ghi chú dữ liệu, cộng đồng chuyên môn.
Những người này có thể sở hữu phần tri thức rất quý, nhưng họ không thể tự đi deal license với từng model builder.
Đây là lúc Datanet có thể đóng vai trò quan trọng hơn một “kho dữ liệu”.
Nó có thể trở thành bể gom IP.
Một contributor nhỏ không cần tự xây hợp đồng bản quyền phức tạp. Họ chỉ cần đưa tri thức của mình vào một Datanet theo chủ đề, ví dụ security vulnerability, y học cổ truyền, dữ liệu tài chính ngách, hoặc một nhóm nội dung chuyên môn nào đó. Story Protocol có thể giúp lớp quyền sở hữu của pool này trở nên rõ ràng. OpenLedger dùng attribution để chia doanh thu ngược về từng người đóng góp theo mức ảnh hưởng thật.
Như vậy, tri thức nhỏ lẻ không bị mắc kẹt vì thiếu quy mô.
Nó được gom lại thành một tài sản IP đủ lớn để model builder quan tâm, nhưng dòng tiền vẫn có thể chia nhỏ về từng contributor.
Đây mới là cách coverage gap có thể được phá.
Không phải bằng việc bắt từng người nhỏ tự trở thành luật sư bản quyền. Mà bằng việc để họ tham gia vào một pool đủ đơn giản, đủ rõ quyền, đủ dễ bán cho model builder.
Vì vậy, metric mình muốn nhìn không phải là thêm bao nhiêu thông báo partnership.
Mình muốn nhìn category đầu tiên tạo được dòng tiền thật.
Một nhóm dữ liệu có giá trị cho AI training.
Nhiều rights holder nhỏ tham gia được mà không cần quá nhiều kỹ thuật.
Model builder thật sự dùng.
Payment quay lại đủ rõ để người tiếp theo có lý do đóng góp.
Khi điều đó xảy ra, OpenLedger x Story Protocol mới chuyển từ “nghe rất đúng” sang “bắt đầu có thị trường”.
Đây cũng là lý do mình không muốn gọi nó đơn giản là compliance.
Compliance chỉ mở cửa.
Thanh khoản mới làm hệ thống sống.
Regulator có thể quan tâm bản ghi. Nhưng thị trường mới định giá bản ghi đó. Enterprise muốn model sạch để dám ký hợp đồng. Model builder muốn dữ liệu an toàn để bán được sản phẩm lớn hơn. Rights holder muốn thấy nếu nội dung của họ tạo value, payment có quay về thật.
Nếu ba bên này không gặp nhau, bản ghi có đẹp đến đâu cũng chỉ là hạ tầng đứng im.
Với mình, câu hỏi lớn nhất không phải OpenLedger và Story Protocol có tạo ra chuẩn bản quyền AI tốt hơn không.
Câu hỏi là: họ có tạo được thanh khoản cho dữ liệu được cấp phép không?
Nếu có, partnership này không còn là một dòng trong ecosystem list. Nó trở thành cách OpenLedger biến tri thức hợp pháp thành một thị trường sống: có người đóng góp, có người mua, có giá, có dòng tiền quay lại.
Thành công sẽ không đo bằng câu “verified on-chain”.
Nó sẽ đo bằng việc ai đăng ký được, ai dùng thật, và content category đầu tiên nào phá được coverage gap.
@OpenLedger $OPEN #OpenLedger $LAB
