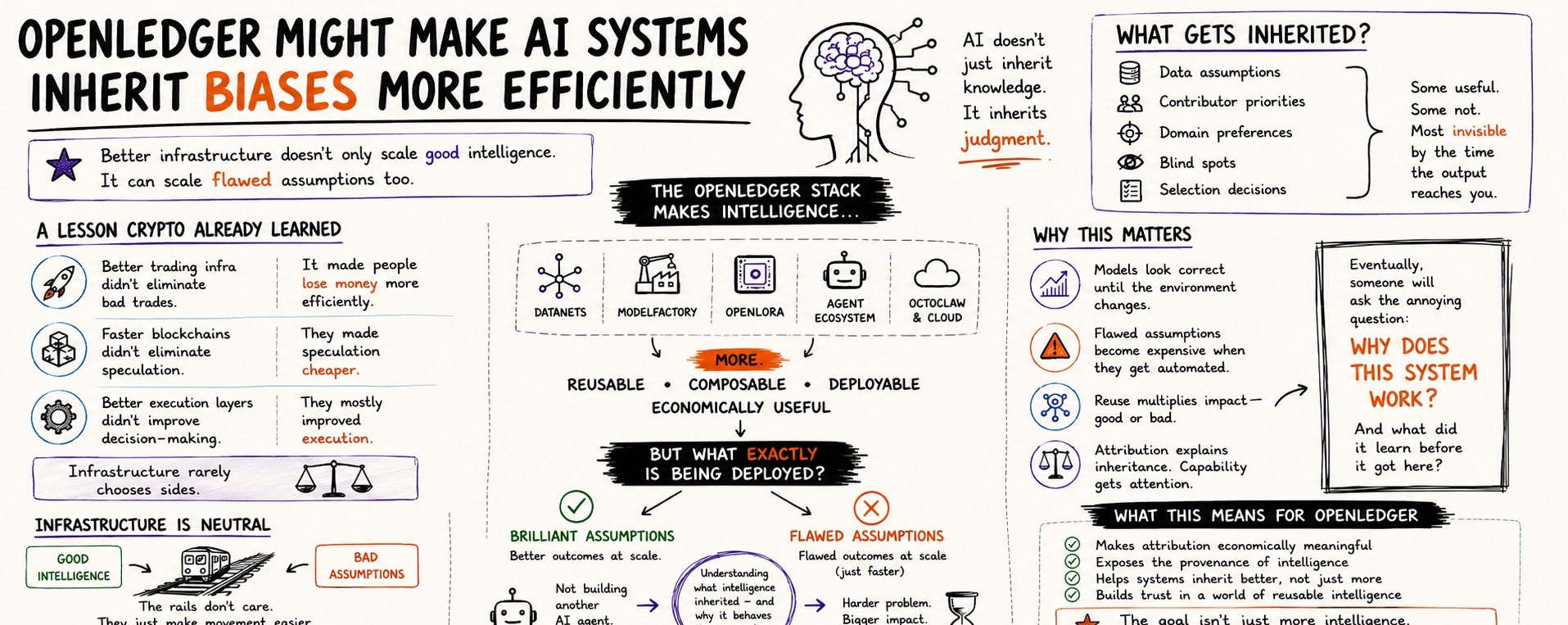
One thing I find funny about infrastructure markets is that people automatically assume better infrastructure means better outcomes.
Sometimes it does.
Sometimes it just makes existing behavior scale faster.
Crypto learned that lesson years ago. Better trading infrastructure didn’t eliminate bad trades. It just made people lose money more efficiently. Faster blockchains didn’t eliminate speculation. They made speculation cheaper. Better execution layers didn’t magically improve decision-making. They mostly improved execution.
The same thought keeps coming back to me when I look at OpenLedger.
Because a lot of the conversation focuses on what the infrastructure enables.
Datanets.
ModelFactory.
OpenLoRA.
Trading agents.
Deployment layers.
Fair enough.
The stack is becoming easier to use.
But easier deployment raises a different question.
What exactly is being deployed?
That sounds obvious until you think about how intelligence actually gets built.
No model appears out of nowhere.
It inherits things.
Data assumptions.
Contributor priorities.
Domain preferences.
Blind spots.
Selection decisions.
Some of those are useful.
Some are not.
Most are invisible by the time the final output reaches a user.
That’s why I think people sometimes oversimplify the AI conversation.
A model doesn’t only inherit knowledge.
It inherits judgment.
Or at least its version of judgment.
A trading system trained around certain market conditions may quietly inherit confidence in environments where confidence is no longer deserved.
A research model may inherit source preferences that look completely reasonable until they aren’t.
A specialized agent may inherit assumptions so deeply that nobody notices them anymore because the outputs keep looking correct.
That’s the uncomfortable part.
The better the output looks, the harder it becomes to inspect what produced it.
And OpenLedger sits directly in that tension.
Because the infrastructure is making intelligence more reusable.
More composable.
More deployable.
More economically useful.
Those are all positive things.
But infrastructure is usually neutral.
The rails don’t care whether the thing moving across them is brilliant or flawed.
They just make movement easier.
Crypto already understands this instinctively.
Liquidity can support good assets and terrible ones.
Leverage can amplify strong ideas and disastrous ones.
Distribution can spread signal and nonsense at the same time.
Infrastructure rarely chooses sides.
AI probably follows the same pattern.
That’s partly why I find attribution more interesting than capability.
Capability gets attention.
Attribution explains inheritance.
And inheritance becomes important once intelligence starts getting reused across multiple systems, contributors, agents, and economic environments.
Because eventually somebody asks the annoying question.
Not whether the system works.
But why it works.
And more importantly…
What exactly it learned before it got here.
That feels like a much harder problem than building another AI agent.
It also feels like the kind of problem that becomes visible only after the infrastructure succeeds.
Which is usually when things get interesting.
