I once noticed something while using different crypto apps that stayed in my mind longer than expected.
A simple transaction that usually completes in seconds took l0nger than it should have. Nothing looked broken. No errors appeared. It just stayed pending for a while before finally going through. A few days later, I saw the same kind of delay again in a different app during a busy period. That is when it stopped feeling random and started feeling like a pattern worth paying attention to.
What I realized is that most blockchain systems do not struggle in obvious ways. They struggle in uneven ways. When usage is low, everything feels smooth and predictable. But when demand increases, the experience changes. Some requests go through immediately while others slow down without a clear reason from the user’s point of view.
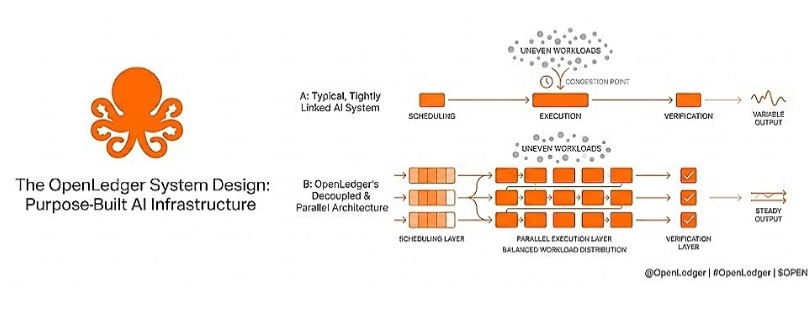
from a system perspective, this usually comes down to coordination rather than raw speed. There are multiple parts working together, such as execution, verification, and scheduling. When these parts are tightly connected, a delay in one area affects everything else. the system does n0t fail, but it becomes inconsistent, and that inconsistency is what users actually notice.
I often think of it like a busy logistics center.
On a normal day, packages move through the system without much friction. Sorting is quick, routes are clear, and everything feels organized. But when volume suddenly increases, the issue is not how fast individual workers are. It becomes about how well the system distributes work. If too many steps depend on a single queue or checkpoint, delays start to build even if every part is functioning properly.
When I look at how @OpenLedger approaches this, what stood out to me is that it feels more focused on system design than on performance claims. The idea seems to be that AI workloads need structure first, not just more computing power.
What matters in practice is how scheduling, execution, and verification are arranged. In many systems, these are tightly linked. If verification slows down, execution gets blocked. if execution slows, scheduling starts piling up. Everything becomes a single chain instead of separate parts that can move independently.
What interests me more is how separating these layers changes behavior under load. If scheduling can continue without waiting on execution, and verification can run without blocking the rest of the system, then the system becomes less fragile when demand is uneven. It does not depend on one continuous flow to keep working.
Backpressure is another part that matters in real systems. Overload does not usually show up as a sudden failure. It builds slowly. Backpressure allows the system to slow itself down before things become unstable. It is not about reducing capability. It is about keeping the system usable when demand is higher than expected.
Worker scaling also depends on how well work is distributed. If tasks are not spread evenly, adding more workers does not solve the core issue. It only moves the bottleneck somewhere else. What matters is whether the system can balance workload across different parts instead of concentrating it in one area.
There is also a constant tradeoff between ordering and parallel execution. Strict ordering is easier to reason about, but it limits throughput. Full parallelism improves performance, but it needs careful coordination to avoid conflicts. Most real systems end up balancing both depending on what the workload requires.
from what I have seen across different networks, the real test of infrastructure is not how it behaves when everything is stable. It is how it behaves when conditions are not. When demand spikes, when multiple processes overlap, when delays start to spread from one part of the system to another.
What stood out to me about OpenLedger is not a single feature, but the way it tries to handle that kind of environment. It feels designed with uneven load in mind, not just ideal conditions.
A system does not need to feel fast when everything is calm. It needs to stay steady when things are not.
Good infrastructure is usually not something you notice. It is something that quietly keeps working even when everything around it becomes busy.