
Setelah beberapa hari ngebaca tentang@OpenLedger dan whitepapers, saya pertama kali merasakan insting yang kuat: di masa depan, yang benar-benar ‘patuh aturan’ mungkin bukan manusia, tapi sistem AI itu sendiri.
Kemarin tengah malam, saya tiduran di tempat tidur sambil scroll X, pertama-tama saya menemukan beberapa film pendek AI yang lagi booming. Kualitas gambar, bahasa sinematografi, dan detail cahaya sudah gila banget, setelah selesai nonton, saya merasa familiar, ada rasa lelah dan kosong. Lalu, saya terus scroll beberapa postingan panjang dari para influencer, judulnya satu lebih bombastis dari yang lain:
“AI Agent akan segera mendisrupsi dunia keuangan”
“Putaran kekayaan berikutnya sudah dimulai”
"99% orang sama sekali nggak ngerti layer data AI"
Pendapat, proyek, dan sentimen dari post ini beda-beda, tapi ritme dan gaya udah makin seragam: sama-sama punya hook di awal, sama-sama maju emosinya, sama-sama 'buat krisis dulu, baru lempar selling point'. Saat itu, tiba-tiba saya merasa bingung—produksi konten di seluruh internet sepertinya lagi disatukan oleh semacam 'template' yang tak terlihat.
Ini mengingatkan saya pada penanganan platform X terhadap konten 'farming mulut' dari Kaito baru-baru ini. Banyak orang mengutuk platform tersebut sebagai 'menekan kreator', bahkan bercanda 'nanti cuma bisa posting gambar kucing'. Tapi kemarin saya lihat lagi, saya tiba-tiba sadar: yang sebenarnya dikhawatirkan platform ini mungkin bukan konten yang terlalu banyak, tapi seluruh internet yang sedang benar-benar kehilangan kontrol.
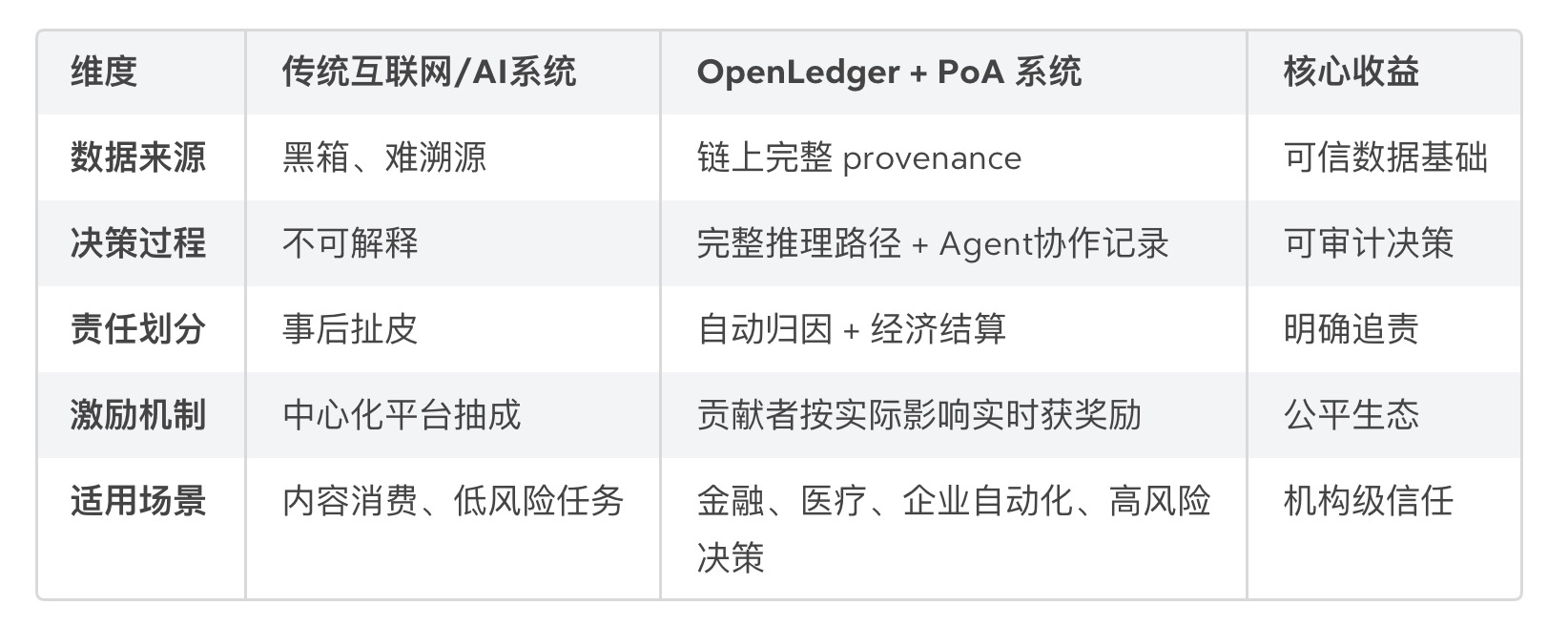
Setelah pikiran ini muncul, saya membuka kembali data dari \u003cm-258/\u003e. Semakin saya lihat, semakin saya merasa, mereka menangkap inti yang belum dijelaskan oleh orang lain: setelah AI beralih dari 'alat konsumsi informasi' ke 'sistem keputusan dan produksi otomatis', logika 'traffic prioritization' masa lalu harus diganti dengan 'responsibility chain prioritization'. Dan \u003ct-262/\u003e sedang membangun dasar aturan untuk perubahan ini.
Pertumbuhan liar internet vs kebutuhan rantai tanggung jawab AI
Dalam dua puluh tahun terakhir, logika inti internet sangat sederhana: tumbuh dulu, sisanya urus belakangan.
Jadi kita lihat:
Judul clickbait merajalela
Akun repost, content farm yang nge-copy massal
Kegiatan ilegal dan pencurian data nggak pernah berhenti
Seluruh sistem hanya peduli dengan kecepatan penyebaran dan traffic, tidak peduli apakah sumber konten legal, apakah data dapat dipercaya, dan apakah tanggung jawab jelas. Akhirnya yang memutuskan selalu adalah 'manusia', sedikit kacau sepertinya juga tidak masalah.
Tapi di era AI, terutama setelah AI Agent mulai diterapkan secara besar-besaran, situasinya benar-benar berubah.
AI bukan sekadar 'melihat konten', tapi belajar jangka panjang, memanggil secara mendalam, mengambil keputusan otomatis, dan terus menghasilkan. Saat Agent mulai mengelola uang, melakukan trading, menjadwalkan data perusahaan, dan menjalankan tugas di dunia nyata, 'tidak dapat dilacak' bukan lagi masalah kecil, tapi bencana sistemik.
Internet cuma butuh traffic, tapi sistem AI harus punya rantai tanggung jawab yang lengkap. Secara spesifik, keputusan dari AI Agent harus bisa jawab pertanyaan berikut:
Data apa yang digunakan?
Model versi apa yang dirujuk?
Kolaborasi dengan Agent mana yang terlibat?
Siapa sumber data? Di mana langkah yang mengalami penyimpangan?
Bagaimana seharusnya tanggung jawab dibagi?
Tanpa ini, perusahaan nggak bakal berani serahin proses inti mereka ke AI. Ini yang bikin OpenLedger benar-benar maju—ini bukan cuma proyek gimmick 'AI + blockchain', tapi lagi bangun infrastruktur hukum untuk dunia AI.
PoA (Proof of Attribution): dari alat hak cipta ke inti audit perilaku AI
Banyak orang awalnya melihat OpenLedger dan berpikir, 'bukankah ini cuma AI + blockchain?' tapi setelah penelitian lebih mendalam, mereka akan menemukan bahwa inovasi inti Proof of Attribution (PoA) jauh lebih dari sekadar 'hak cipta AI'.
PoA adalah mekanisme kriptografi yang bisa merekam dan melacak dengan akurat di on-chain:
Dampak kontribusi data: seberapa besar kontribusi dataset tertentu terhadap output model (misalnya 30% inspirasi berasal dari konten kreator tertentu).
Traceability pelatihan model: data set mana yang digunakan selama proses pelatihan, bagaimana versi model berevolusi.
Catatan lengkap jalur penalaran: setiap kali penalaran/generasi, jalur pemanggilan data, hubungan kolaborasi Agent, dan rantai keputusan semuanya dicatat di blockchain, membentuk bukti audit yang tidak bisa diubah.
Atribusi dan penyelesaian real-time: kontributor secara otomatis menerima penghargaan berdasarkan pengaruh nyata, sementara data berkualitas rendah atau berniat jahat akan dihukum.
Sederhananya, PoA mengubah setiap langkah AI dari 'black box' menjadi proses transparan yang bisa dijelaskan, diverifikasi, dan diresponsibelkan. Ini bukan cuma menyelesaikan masalah hak cipta, tapi juga mengatasi tantangan kepercayaan dan kepatuhan saat AI beroperasi di sektor-sektor berisiko tinggi seperti keuangan, kesehatan, otomatisasi perusahaan, dan hukum.
Contoh yang paling nyata:
Misalnya, jika seorang AI Agent keuangan membantu Anda trading otomatis dan hasilnya rugi. Anda ingin tahu tanggung jawabnya di mana—apakah karena polusi data? Bias model? Atau ada kesalahan dalam pemanggilan oleh Agent perantara? Di OpenLedger, semua ini bisa diaudit cepat melalui catatan on-chain, bukan saling menyalahkan setelah kejadian.
Mengapa sekarang melakukan ini bisa dilakukan? (waktu dan kelayakan)
Banyak orang bertanya: apakah terlalu dini untuk membahas rantai tanggung jawab yang kompleks ini?
Sebenarnya, waktunya udah pas:
Kebutuhan kepatuhan perusahaan yang meledak: seiring dengan pengawasan AI yang semakin ketat (seperti EU AI Act), lembaga keuangan dan perusahaan besar semakin membutuhkan 'AI yang dapat diaudit', jika tidak, mereka tidak berani menerapkan secara besar-besaran.
RAG dan alur kerja Agent secara alami terintegrasi: retrieval-augmented generation (RAG) sendiri membutuhkan traceability yang akurat, PoA bisa disisipkan dengan mulus, menyediakan provenance end-to-end.
Tren biaya dan standardisasi: biaya penyimpanan blockchain terus menurun, teknologi zero-knowledge membuat atribusi granular menjadi kenyataan. OpenLedger melalui DataNets dan Model Factory (alat penyempurnaan model tanpa kode) menurunkan ambang partisipasi.
Insentif ekosistem yang tertutup: kontribusi data, pelatihan model, dan penerapan Agent semuanya bisa mendapatkan imbalan ekonomi nyata melalui PoA, membentuk siklus positif.
Perbandingan inti antara masalah dan nilai yang diselesaikan oleh OpenLedger
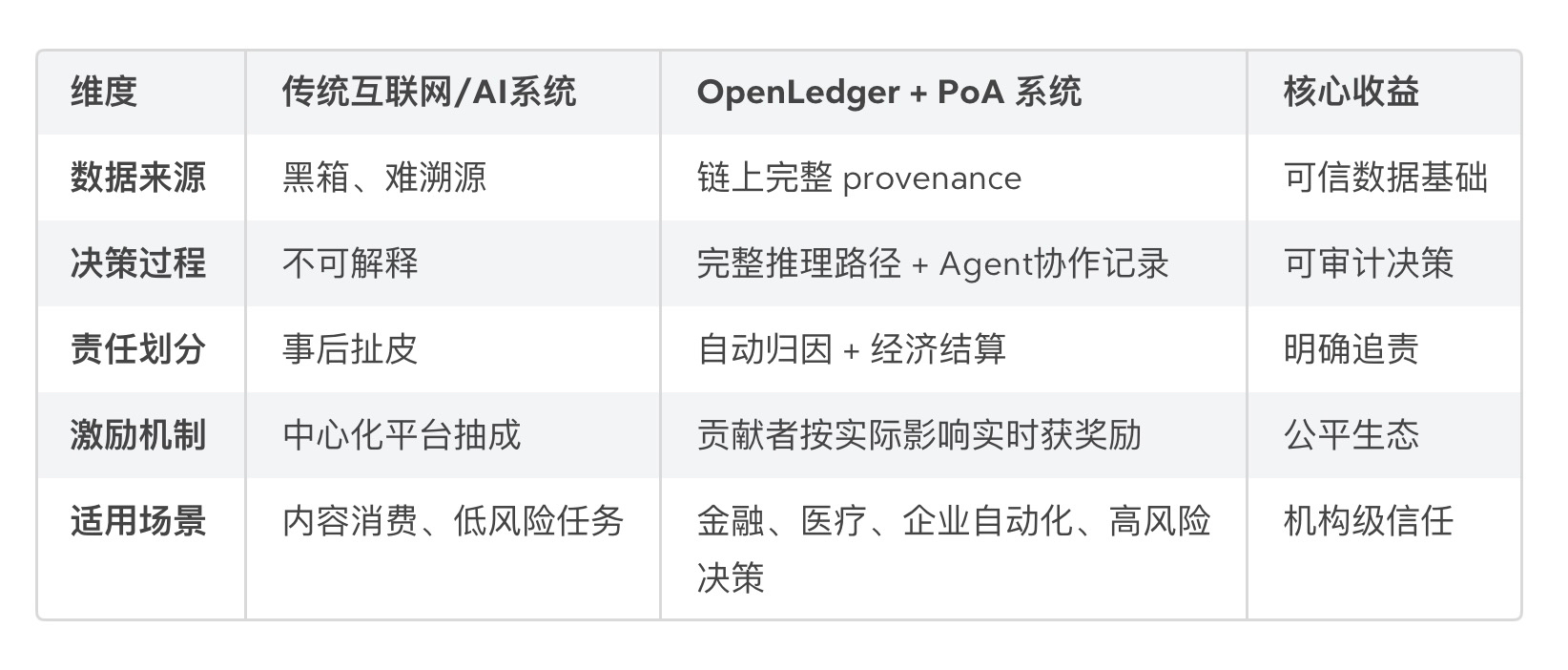
Ringkasan hasil:
Kontributor data/model: monetisasi nilai nyata
Pengembang/perusahaan: mengurangi risiko penerapan model yang sesuai
Pengguna/pengguna Agent: mendapatkan layanan AI yang dapat dijelaskan dan dipercaya
Seluruh ekosistem: dari 'pertumbuhan liar' ke 'produksi teratur'
Potensi batasan dan risiko (penjelasan objektif):
Kepatuhan privasi dan data on-chain (perlu menyeimbangkan teknologi zero-knowledge)
Tantangan ketepatan granular atribusi (terutama di skenario multi-Agent kompleks)
Risiko serangan penyihir/pemalsuan kontribusi (perlu mekanisme tata kelola yang baik)
Kurva adopsi awal cukup curam
Semua ini adalah masalah yang sedang tumbuh, tapi dibandingkan dengan risiko sistemik yang nggak diselesaikan rantai tanggung jawab, ini udah bisa dikelola.
Masa depan internet AI: dari plaza informasi ke sistem produksi otomatis
Tempat paling sukses di internet masa lalu adalah minim peraturan—daftar langsung bisa posting, copy bisa tersebar, anonim bisa kabur. Ini bawa pertumbuhan yang meledak, tapi juga ninggalin polusi informasi dan runtuhnya kepercayaan.
Di era AI, internet sedang naik level dari 'plaza informasi' menjadi 'sistem produksi otomatis'. Sistem produksi harus teratur: pencatatan, audit, dapat diverifikasi, dapat diresponsibelkan. Jika tidak, masalah seperti kehilangan aset, risiko identitas, dan keruntuhan proses perusahaan akan berlipat ganda.
Ini memberi saya perasaan aneh: dulu internet paling mirip dengan masyarakat manusia—kacau, emosional, pertumbuhan liar; masa depan sistem AI malah mungkin lebih mirip mesin hukum—setiap langkah bisa dicatat, diverifikasi, dan diresponsibelkan, bahkan lebih 'taat aturan' daripada manusia sendiri.
Sementara itu, OpenLedger udah mulai bangun kerangka untuk hal ini. Mereka bukan fokus ke 'gimana AI jadi lebih pintar', tapi 'gimana dunia AI bisa bangun tatanan yang dipercaya'. Selain parameter, daya komputasi, dan kecepatan, mereka tawarkan keandalan sebagai sumber daya yang langka.
Siapa yang bisa membuktikan sumber data dapat dipercaya, proses penalaran dapat dipercaya, perilaku Agent dapat dipercaya, jalur tanggung jawab dapat dipercaya, dialah yang mungkin menjadi infrastruktur dasar di era AI.
Saran tindakan untuk pembaca: bagaimana cara menilai proyek 'layer aturan' seperti ini?
Lihat implementasi mekanisme: apakah ada whitepaper teknis nyata? Apakah PoA benar-benar mencatat dampak data, jalur penalaran, bukan sekadar spekulasi konsep?
Lihat keterverifikasian: bisa nggak kasih contoh audit on-chain? Apakah ada kerjasama dengan proyek data kayak Chainbase untuk meningkatkan traceability?
Lihat adopsi ekosistem: apakah ada contoh nyata integrasi perusahaan/Agent? Apakah DataNets dan Model Factory menarik kontributor?
Lihat mekanisme dan insentif: \u003cc-31/\u003e token bagaimana digunakan untuk penghargaan, Gas, dan tata kelola? Apakah terbentuk siklus tertutup dan bukan sekadar spekulasi?
Pandangan jangka panjang: prioritaskan proyek yang menyelesaikan masalah nyata (kepatuhan, kepercayaan, penerapan perusahaan), bukan sekadar narasi.
Proyek AI masa depan bukan tentang siapa yang lebih bisa membantu manusia 'mouth farm', tapi siapa yang bisa membangun kepercayaan.
\u003cm-195/\u003e\u003ct-196/\u003e\u003cc-197/\u003e
