Semakin lama saya ngamatin proyek data terdesentralisasi, semakin saya ngerasa bahwa kebanyakan diskusi fokus pada kompetisi yang salah.
Orang sering ngeliat ini sebagai perlombaan untuk pasokan data.
Siapa yang bisa ngumpulin data paling banyak. Siapa yang bisa tarik kontributor terbanyak. Siapa yang bisa bangun marketplace terbesar.
Tapi itu mungkin cuma permukaan aja.
Data itu sendiri nggak pernah jadi sumber yang bener-bener langka.
Yang lebih susah dicari adalah sistem yang bisa nge-transform data mentah jadi intel yang bisa diverifikasi, terus-menerus diperbaiki, dan berulang kali menghasilkan nilai.
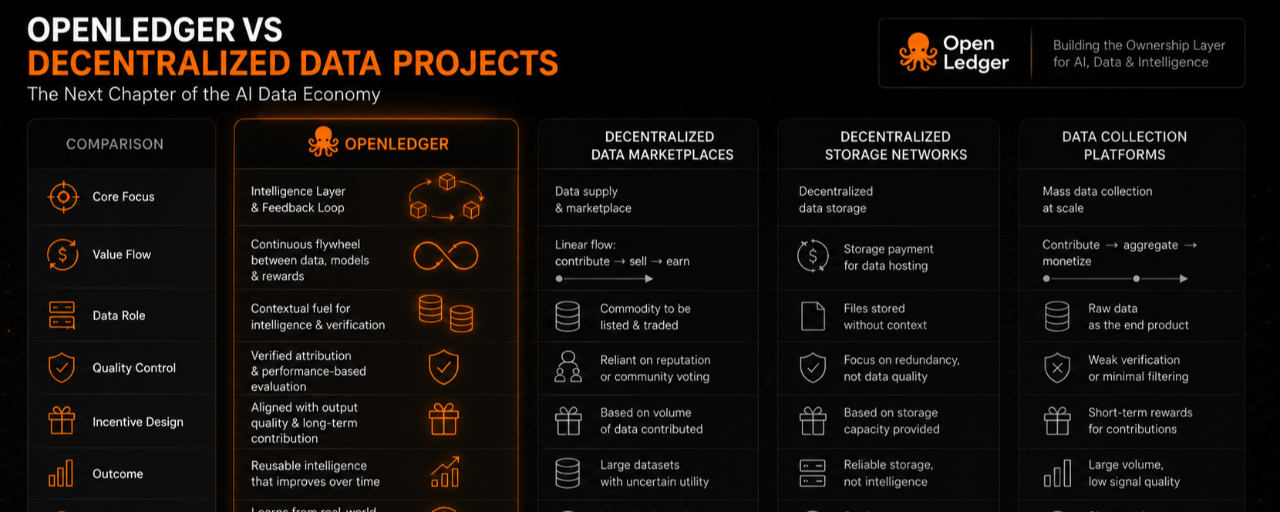
Itulah sebabnya saya menemukan OpenLedger sangat menarik dibandingkan dengan banyak inisiatif data terdesentralisasi yang muncul dalam beberapa tahun terakhir.
Kebanyakan proyek beroperasi dengan asumsi bahwa jika cukup banyak data dapat dikumpulkan, ekosistem lainnya akan secara alami berkembang di sekitarnya.
Secara teori, itu masuk akal.
Namun dalam praktiknya, data jarang menjadi bahan yang hilang.
Tantangan nyata adalah konteks, penilaian kualitas, dan memahami dataset mana yang benar-benar menghasilkan hasil yang lebih baik daripada yang lain.
Lebih penting lagi, banyak sistem masih kesulitan untuk menghubungkan kontributor dengan nilai yang dibantu oleh data mereka.
Dari sudut pandang saya, OpenLedger tampaknya mendekati tantangan ini dengan cara yang berbeda.
Alih-alih fokus hanya pada membangun repositori informasi yang besar, tujuannya tampaknya menciptakan umpan balik di mana data, model AI, dan insentif ekonomi saling memperkuat.
Sekilas, itu mungkin terdengar seperti perbedaan desain kecil.
Pada kenyataannya, itu menciptakan insentif perilaku yang sama sekali berbeda.
Karena orang tidak merespons teknologi saja.
Mereka merespons insentif.
Banyak proyek data terdesentralisasi mendorong pengguna untuk berkontribusi data terlebih dahulu dan kemudian mencoba menemukan cara untuk mengekstrak nilai darinya setelahnya.
Beberapa pendekatan baru, termasuk OpenLedger, tampaknya membalikkan proses itu.
Nilai yang dihasilkan oleh output menjadi titik awal, sementara data berfungsi sebagai salah satu komponen dalam siklus penciptaan nilai yang lebih besar.
Apa yang terlihat seperti keputusan produk mungkin sebenarnya mencerminkan pergeseran yang lebih luas dalam cara pasar memikirkan AI.
Gelombang pertama terobsesi dengan model.
Gelombang berikutnya menjadi terobsesi dengan data.
Sekarang perhatian tampaknya beralih ke pertanyaan yang berbeda:
Bagaimana kita membangun sistem yang terus belajar dari interaksi dunia nyata daripada hanya mengumpulkan dataset yang lebih besar?
Karena data tidak statis.
Ini adalah refleksi dari perilaku manusia.
Dan perilaku manusia terus berubah.
Apa yang sangat relevan hari ini bisa menjadi usang dalam beberapa bulan saat orang berubah cara mereka mencari, berkomunikasi, dan membuat keputusan.
Model yang dilatih berdasarkan realitas kemarin mungkin tidak dioptimalkan untuk esok hari.
Mungkin itulah sebabnya saya terus memperhatikan proyek seperti OpenLedger.
Bukan karena mereka telah sepenuhnya memecahkan tantangan data terdesentralisasi.
Tapi karena mereka menjelajahi pertanyaan yang lebih mendasar.
Jika ekonomi yang didorong AI akhirnya muncul, di mana nilai sebenarnya akan berada?
Dalam memiliki data?
Dalam memiliki model?
Atau dalam memiliki umpan balik yang terus menghubungkan keduanya?
Saya rasa pasar belum mencapai jawaban yang jelas.
Tapi semakin terasa bahwa kompetisi besar berikutnya tidak akan tentang siapa yang memiliki data paling banyak.
Ini akan tentang siapa yang dapat membangun sistem yang menjaga data tetap berharga seiring dunia—dan perilaku manusia—terus berkembang.