

I used to think data ownership was a simple phrase until AI made it slippery. A photo has an owner. A sentence has an author.
A dataset does not stay simple for long. After it is cleaned, labeled, mixed, and used by AI, its original source becomes blurry. When the final answer appears, it may not look like any single contribution anymore. That is where old ideas of ownership stop being enough.It asks, who owns the file? AI asks something stranger: who shaped the behavior?
That is the tension OpenLedger seems to be walking into with Datanets and attribution. It is not only trying to say that people should own data in a private-property sense. It is trying to make ownership more open by making contribution visible after the data leaves someone’s hands.
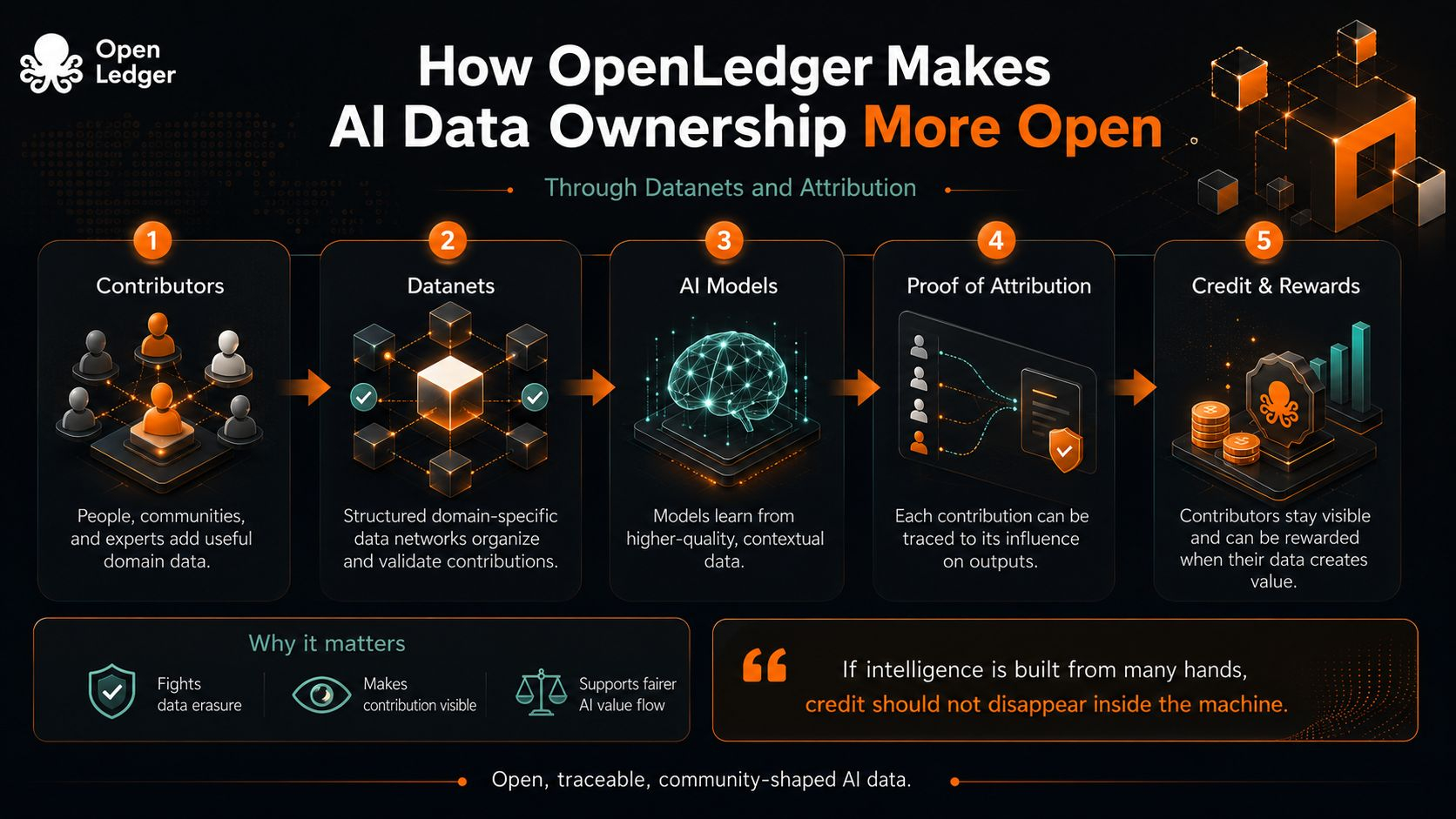
I find that distinction important. In most AI systems, data enters like a crowd entering a stadium. Once inside, the faces disappear. The final model performs, the app receives attention, and the people who supplied the useful examples become background noise. Sometimes they were researchers. Sometimes communities. Sometimes ordinary users whose knowledge had structure before a company turned it into fuel. The uncomfortable default is not just extraction. It is erasure.
Datanets, at least as an idea, push against that erasure by giving data a place to gather with context. Instead of treating all information as one giant pile, they organize contributions around specific domains, purposes, and communities. That sounds small, almost administrative, but it changes the moral shape of the system. A contribution is no longer just swallowed by a model. It enters a network where its origin, use, and value can be argued over.
Attribution is the harder part. It is easy to record that someone uploaded something. It is much harder to prove that the thing mattered. OpenLedger’s Proof of Attribution points toward that second problem: not only tracing data, but linking it to model outputs and reward flows. This is where the idea becomes interesting to me, because it treats ownership less like a locked box and more like a living relationship. Your data matters if it helps shape the answer. Your credit should not vanish just because the model has become fluent.
Still, I do not want to pretend this solves everything. Attribution can become its own bureaucracy. Bad data can be neatly tracked. Shallow contributions can chase rewards. Communities can be reduced to leaderboards if the design is careless. The real test is not whether OpenLedger can describe a cleaner system. Many projects can do that. The test is whether the system can handle messy human contribution without flattening it into another game of points.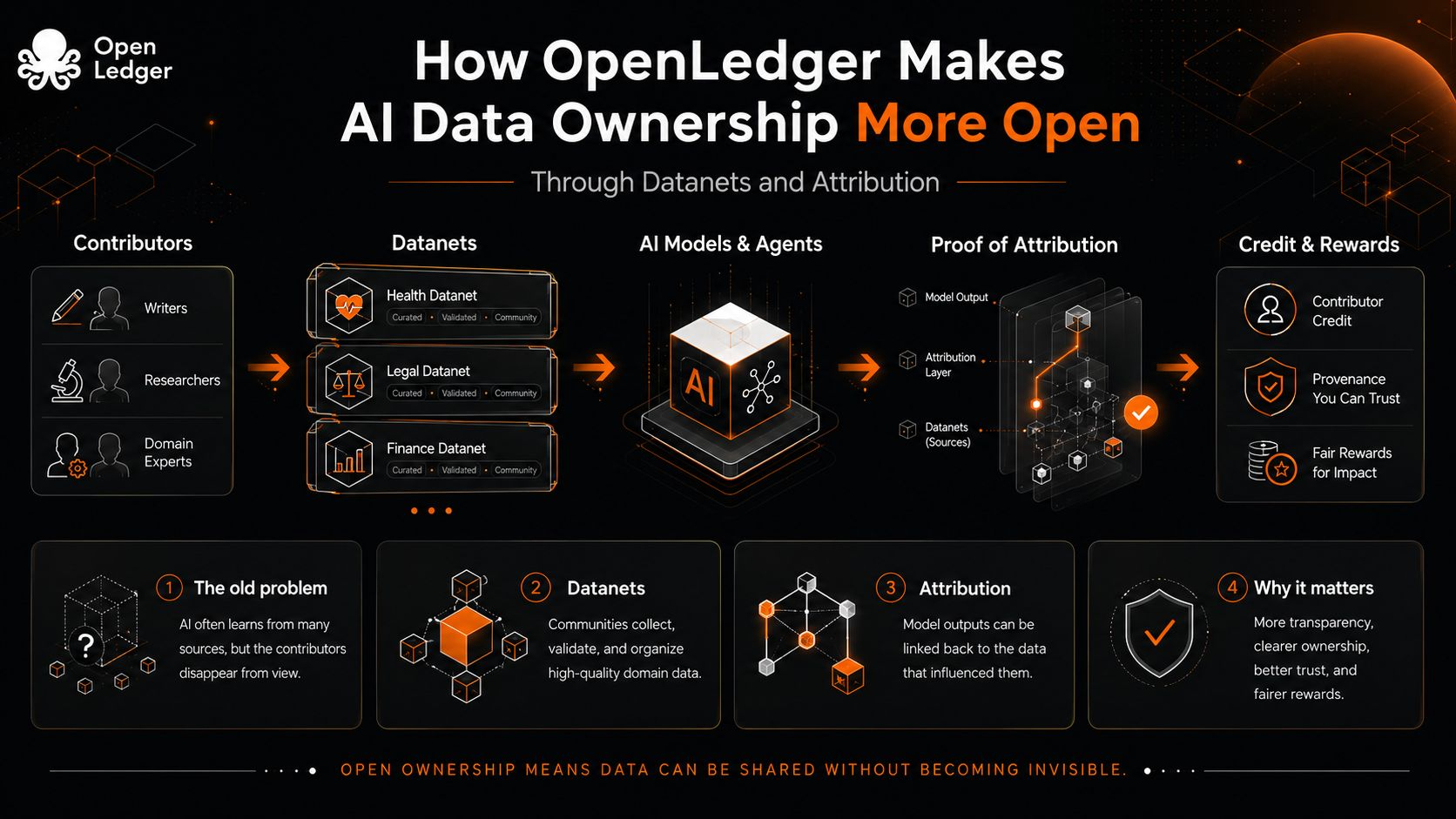
But the direction matters. AI has made ownership feel strangely closed, even when the internet looks open. Knowledge moves everywhere, yet credit often moves nowhere. Datanets and attribution suggest a different default: data can be shared without becoming ownerless, used without becoming invisible, and monetized without pretending the model created value alone.
That is why I see OpenLedger’s idea less as a finished answer and more as a pressure placed on the AI economy. It asks a simple, difficult question: if intelligence is built from many hands, why should only the final machine have a name? That question feels overdue, and maybe useful because it refuses to stay abstract.
