Saya sudah mengamati OpenLedger lebih lama dari yang saya perkirakan, dan bagian anehnya adalah proyek itu sendiri berhenti menjadi hal yang paling menarik sekitar pertengahan riset. Cerita yang lebih besar terus menarik perhatian saya ke arah lain. Setiap dokumen, setiap diagram arsitektur, setiap penjelasan tentang Proof of Attribution tampak mengorbit kenyataan tidak nyaman yang sama: AI modern bergantung pada kontribusi manusia yang sangat besar, namun hampir tidak ada sistem di sekitarnya yang dirancang untuk mengingat dari mana kontribusi itu berasal. Kita berbicara tanpa henti tentang model, inferensi, GPU, hukum skala, dan agen yang semakin kuat. Perhatian jauh lebih sedikit diberikan pada asal-usul ekonomi dari kecerdasan itu sendiri. Itu terasa seperti titik buta. Yang semakin tumbuh.
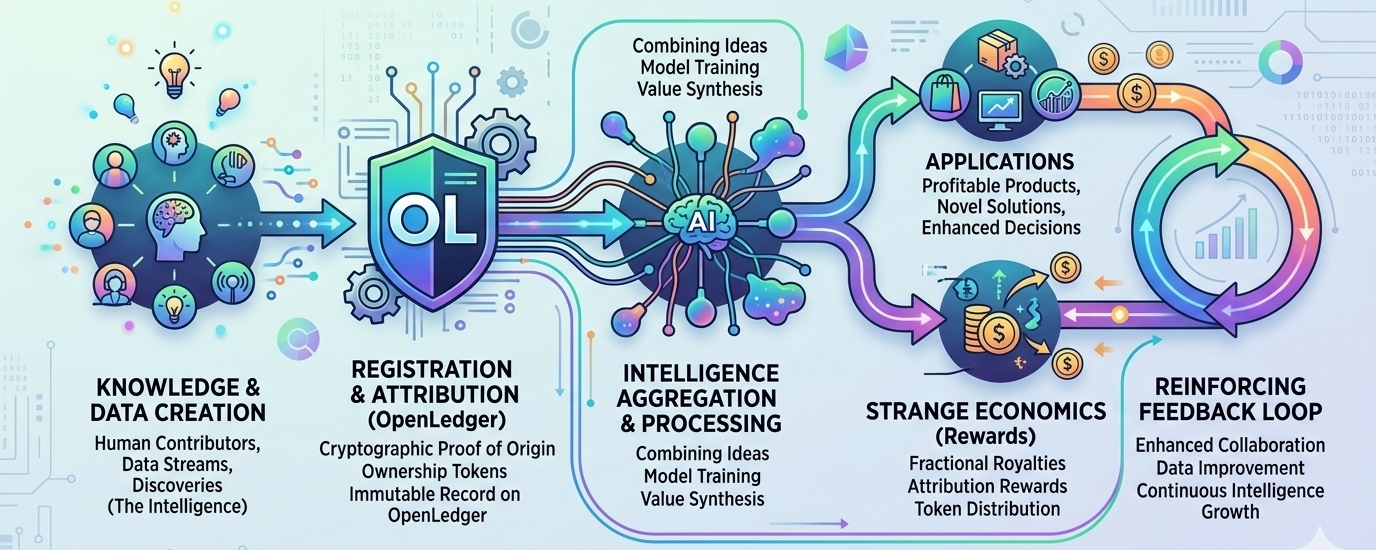
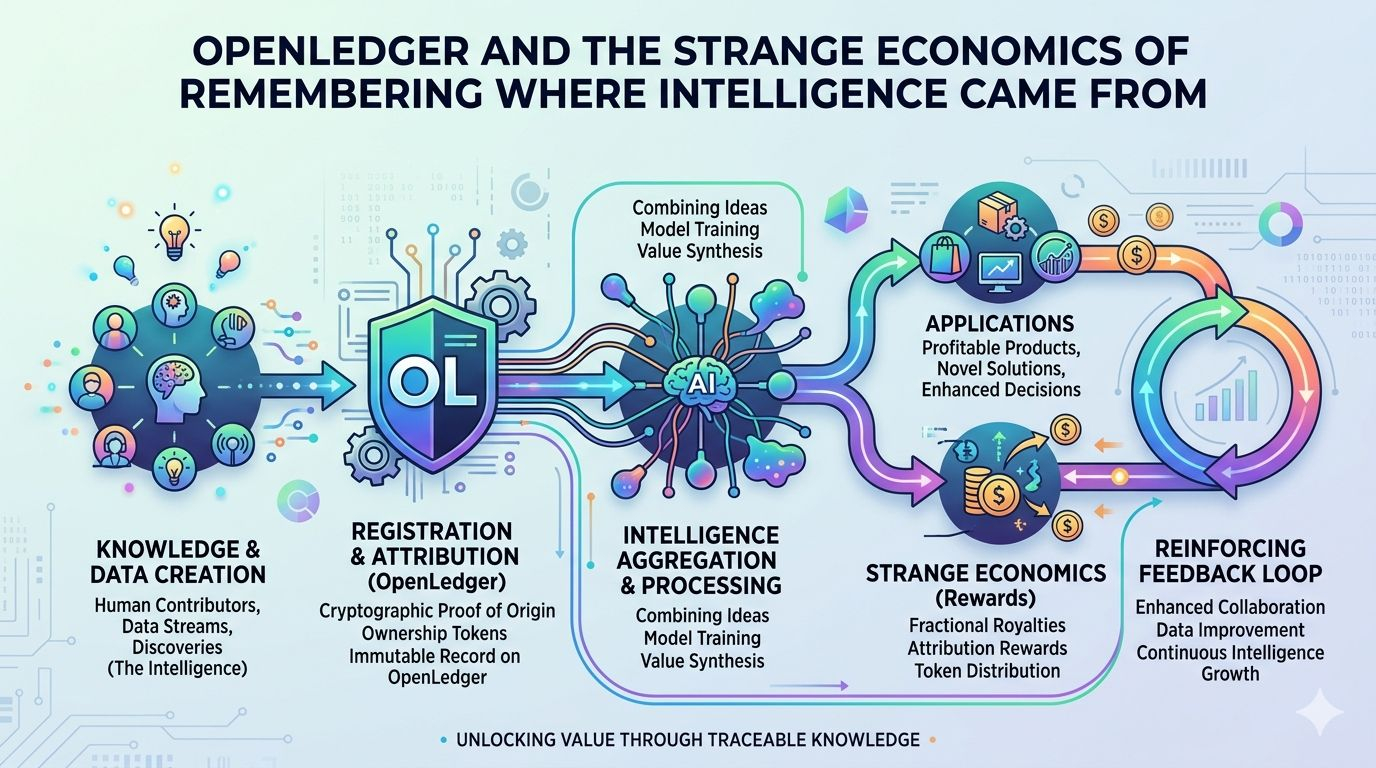
OpenLedger mencoba membangun infrastruktur di sekitar masalah itu. Proyek ini menggambarkan dirinya sebagai blockchain yang berfokus pada AI di mana dataset, model, dan agen dapat dilacak, dikaitkan, dan dimonetisasi melalui kerangka kerja on-chain yang dibangun khusus untuk alur kerja AI. Alih-alih memperlakukan data sebagai input yang bisa dibuang yang menghilang ke dalam jalur pelatihan, OpenLedger berusaha untuk menciptakan catatan permanen yang menunjukkan bagaimana kontribusi mempengaruhi perilaku dan output model. Mekanisme di balik ini disebut Bukti Attribusi, yang bertujuan untuk mengaitkan kontribusi data secara kriptografis dengan hasil model dan memberi penghargaan kepada peserta sesuai dengan dampak mereka. Di atas kertas, ini terdengar hampir jelas. Jika data menciptakan nilai, kontributor harus menerima sebagian dari nilai itu. Kesederhanaan ide ini mungkin adalah alasan mengapa ia terus terlintas di kepala saya.
Nah, di situlah komplikasinya mulai muncul.
Semakin saya membaca, semakin saya menyadari bahwa OpenLedger tidak benar-benar membuat argumen teknis sebanyak argumen ekonomi. Mereka mengusulkan bahwa data harus berperilaku seperti modal produktif daripada sumber daya yang diserap dan dilupakan. Sistem Datanet mereka berfungsi sebagai jaringan dataset khusus di mana kontributor menyediakan informasi khusus domain yang dapat digunakan untuk pelatihan dan penerapan AI. Dataset ini tetap dapat diatribusikan, versi, dan terhubung dengan kontributor melalui sistem catatan yang transparan. Saat membaca dokumentasi, saya terus berpikir tentang seberapa berbeda itu dari ekonomi AI saat ini, di mana informasi sering kali digabungkan pada skala besar dan kontribusi individu menjadi hampir tidak mungkin diidentifikasi setelahnya.
Yang menarik perhatian saya adalah OpenLedger tampaknya bertaruh pada masa depan di mana AI menjadi lebih spesifik daripada sekadar lebih besar. Proyek ini berulang kali menekankan model khusus domain yang dilatih pada dataset yang terfokus daripada sepenuhnya bergantung pada sistem umum raksasa. Mungkin mereka benar. Obsesi saat ini dengan model yang semakin besar kadang terasa aneh terlepas dari bagaimana bisnis sebenarnya beroperasi. Sebagian besar industri tidak membutuhkan mesin yang mampu mendiskusikan filosofi, menulis puisi, dan menghasilkan naskah film. Mereka membutuhkan sistem yang memahami klaim asuransi, laporan radiologi, proses manufaktur, dokumen hukum, atau perkiraan pertanian dengan presisi yang sangat tinggi. Masa depan mungkin akan berisi ribuan model spesialis yang diam-diam melakukan pekerjaan berguna daripada sekelompok model besar yang mencoba melakukan segalanya.
Kemungkinan itu mengubah nilai data. Tiba-tiba aset yang langka bukanlah informasi secara umum. Sudah ada terlalu banyak informasi. Aset yang langka menjadi informasi yang dapat dipercaya. Informasi yang terverifikasi. Informasi yang kaya konteks. Data yang terhubung dengan keahlian. Datanet OpenLedger tampaknya dirancang berdasarkan asumsi ini. Kontributor mengirimkan dataset teks, gambar, atau audio ke dalam repositori terstruktur di mana sistem validasi berusaha menilai kualitas dan relevansi sebelum informasi menjadi bagian dari ekosistem. Seluruh kerangka kerja tergantung pada gagasan bahwa data yang berguna pantas mendapatkan pengakuan ekonomi.
Namun, saya terus menghadapi pertanyaan yang sama saat membaca tentang mekanisme atribusi. Bisakah pengaruh di dalam jaringan saraf benar-benar diukur dengan cukup akurat agar sistem penghargaan ini berfungsi dengan adil?
Di situlah skeptisisme saya menjadi lebih sulit untuk ditekan.
Model pembelajaran mesin bukanlah sistem akuntansi. Mereka adalah sistem statistik. Pengaruh menyebar di seluruh lapisan, bobot, embedding, proses pengambilan, dan interaksi yang sering kali sulit untuk diinterpretasikan bahkan untuk peneliti yang membangunnya. OpenLedger mengakui tantangan ini dengan mengusulkan beberapa metode atribusi, termasuk pendekatan fungsi pengaruh dan sistem atribusi tingkat token tergantung pada arsitektur model. Ambisi teknisnya mengesankan. Apakah metode tersebut tetap dapat diandalkan pada skala besar jauh lebih sulit untuk dievaluasi.
Mungkin atribusi yang sempurna adalah hal yang mustahil.
Mungkin itu adalah tolok ukur yang salah.
Pertanyaan yang lebih realistis adalah apakah atribusi yang tidak sempurna masih jauh lebih baik daripada hampir tidak adanya atribusi yang ada saat ini.
Saya curiga bahwa mungkin itulah argumen sebenarnya yang tersembunyi di balik bahasa pemasaran.
Bagian lain dari arsitektur yang menarik perhatian saya melibatkan sistem Generasi Augmented Retrieval. OpenLedger mengusulkan kerangka kerja di mana informasi yang diambil dapat tetap terhubung ke sumber aslinya selama inferensi. Jika sebuah model menghasilkan output menggunakan informasi dari dataset tertentu, peristiwa pengambilan dapat dicatat dan kontributor diberi imbalan sesuai. Dibandingkan dengan beberapa ide yang lebih abstrak yang beredar di AI dan crypto, ini terasa cukup nyata. Sebagian besar penerapan AI praktis saat ini berputar di sekitar pengambilan, manajemen pengetahuan, pencarian perusahaan, dan sistem informasi daripada skenario fiksi ilmiah tentang superintelligence otonom. OpenLedger tampaknya menyadari kenyataan itu.
Tentu saja, tidak ada jaminan bahwa ini akan diadopsi.
Proyek infrastruktur sering terdengar menarik jauh sebelum mereka menjadi berguna.
Industri AI bergerak dengan sangat cepat. Organisasi besar memiliki keuntungan besar dalam sumber daya komputasi, bakat teknik, saluran distribusi, dan modal. Sistem terbuka harus bersaing melawan perusahaan yang mampu menghabiskan miliaran dolar setiap tahun untuk penelitian dan infrastruktur. Tantangan itu sendiri bisa membanjiri bahkan ide-ide yang kuat. Ada juga risiko yang familiar bahwa insentif crypto menjadi lebih menarik daripada penggunaan produk yang sebenarnya, menciptakan ekosistem di mana spekulasi tumbuh lebih cepat daripada utilitas.
Saya melihat jejak ketegangan itu saat membaca diskusi komunitas. Beberapa kontributor tampaknya benar-benar tertarik pada kepemilikan data dan atribusi. Yang lain tampak lebih fokus pada kinerja token, listing bursa, dan narasi pasar. Pemisahan itu ada di hampir setiap proyek crypto pada akhirnya. Bagian sulitnya adalah menentukan sisi mana yang menjadi dominan seiring waktu.
Begitu saya selesai membaca putih dan dokumentasi atribusi, saya merasa memiliki ketidakpastian yang lebih sedikit daripada saat saya mulai. Anehnya, itu membuat proyek ini lebih menarik daripada kurang. OpenLedger terasa seperti upaya untuk menyelesaikan masalah yang benar-benar ada, meskipun solusinya masih belum selesai. Ekonomi AI semakin bergantung pada kontribusi dari jaringan orang-orang besar yang partisipasinya menjadi tidak terlihat setelah pelatihan dimulai. Data masuk ke mesin. Nilai muncul kemudian. Koneksi antara dua momen itu sering kali menghilang.
OpenLedger pada dasarnya berargumen bahwa koneksi harus tetap terlihat selamanya.
Apakah visi itu berhasil atau tidak tidak mungkin diketahui sekarang. Tantangan teknisnya besar. Tantangan koordinasi mungkin bahkan lebih besar. Namun pertanyaan mendasar terasa sulit untuk diabaikan: saat kecerdasan buatan menjadi semakin penting secara ekonomi, bagaimana kita memutuskan siapa yang berkontribusi pada kecerdasannya di tempat pertama?
Industri tampaknya belum memiliki jawaban yang meyakinkan.
OpenLedger, dengan segala ketidakpastiannya, setidaknya mencoba untuk mengajukan pertanyaan sebelum pasar lainnya dipaksa untuk melakukannya.
