The biggest builder problem in AI today is not model access. It is data trust.
Most builders can already access powerful models through APIs. The harder challenge starts when they need reliable data to improve those models, fine-tune specific use cases, or build specialized agents. Data comes from many sources, quality varies dramatically, ownership is often unclear, and contributors rarely have a direct reason to keep providing useful information over time.
This creates a strange situation. Builders want better intelligence, but the workflow used to produce that intelligence is fragmented. Data providers, model builders, and application developers often operate in separate layers with different incentives. The result is friction, slower iteration cycles, and uncertainty about whether the underlying data remains useful as projects scale.
What many people misunderstand about OpenLedger is that they view it primarily as another AI project competing for attention in an already crowded market.
The more interesting angle is that OpenLedger appears to be focused on the economic coordination layer behind AI development. The project is not simply asking how to create models. It is asking how contributors, datasets, models, and applications can interact in a way where value creation is measurable and participation remains sustainable.
That distinction matters.
The traditional workflow often treats data as a one-time resource. Data gets collected, processed, and absorbed into models. Once that happens, the connection between the original contributor and future value generation becomes difficult to track. Builders gain intelligence, but attribution and incentive structures become increasingly opaque.
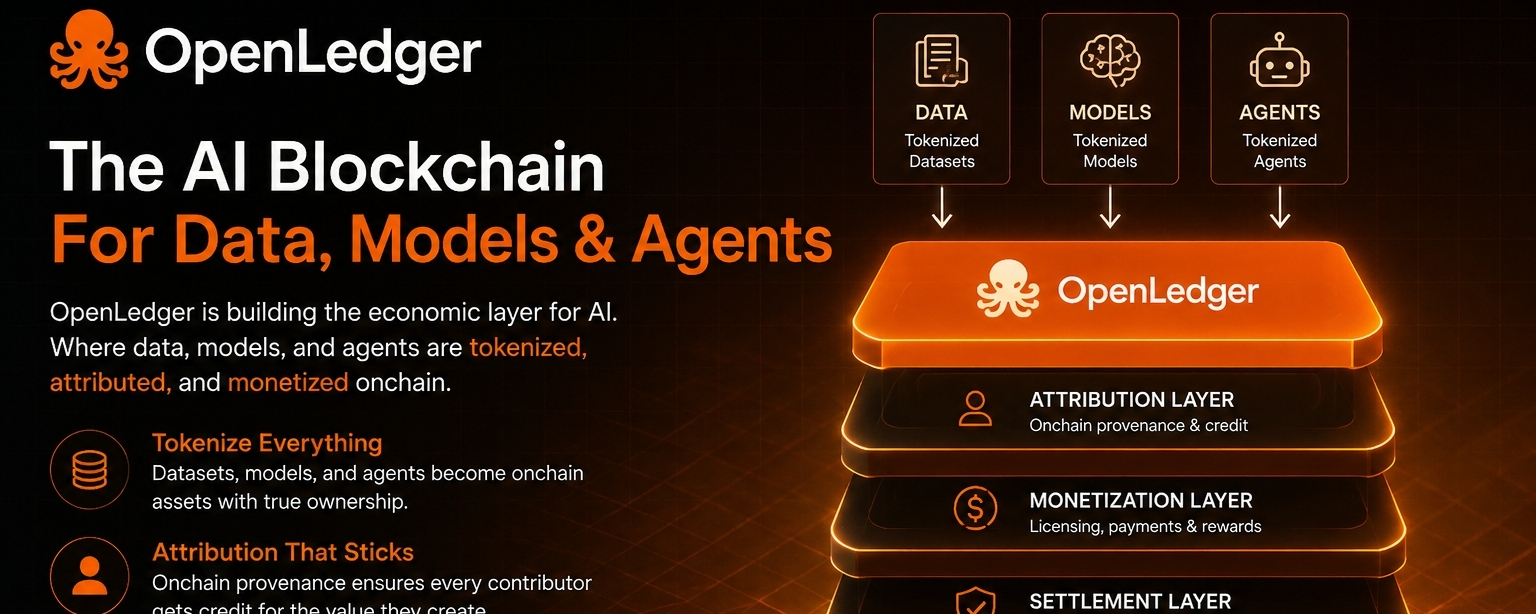
OpenLedger attempts to reduce this friction by introducing infrastructure where data, models, and AI agents can exist within a framework designed for attribution and monetization. Instead of viewing data as a disposable input, the system treats it as an asset that can continue generating value across the lifecycle of AI applications.
The part that stands out to me is that this shifts the conversation from model performance alone to contribution accountability.
Builders frequently talk about better models. They spend less time discussing how sustainable data production actually happens. Yet many AI products ultimately become constrained by data quality rather than raw model capability. If contributors have no reason to keep participating, data quality deteriorates. When data quality deteriorates, application performance eventually follows.
This is where the adoption pressure point exists.
For OpenLedger to matter, builders must decide that attribution and incentive alignment are important enough to integrate into their workflows. The technology itself is only part of the equation. The larger challenge is behavioral. Developers are accustomed to existing pipelines, centralized datasets, and established AI tooling. Any new infrastructure must reduce enough friction to justify changing those habits.
If that shift occurs, builders gain something valuable: a clearer path between contribution and reward. Data providers have stronger reasons to participate. Model creators gain access to potentially richer information sources. Application developers operate on top of a system where value flows can be tracked more transparently.
Consider a practical scenario.
A team building a specialized healthcare assistant needs domain-specific knowledge that general-purpose models cannot provide reliably. They require ongoing contributions from experts, researchers, and niche data sources. Under traditional structures, maintaining contributor engagement becomes difficult because the relationship between contribution and future value is weak.
A framework like OpenLedger attempts to create a structure where contributions remain visible and economically connected to the intelligence being produced. Instead of constantly rebuilding participation from scratch, builders can potentially operate within a system designed to encourage long-term contribution.
That does not automatically solve the problem.
An honest risk remains.
Infrastructure can create attribution mechanisms, but it cannot force meaningful participation. If high-quality contributors, model builders, and application developers do not actively use the network, the economic design becomes less relevant. Coordination systems become powerful only when enough participants agree to coordinate through them.
This is why network adoption matters more than technical architecture alone.
The strongest thesis around OpenLedger is not that it helps create AI. Many projects already pursue that goal. The stronger thesis is that it attempts to reduce one of AI’s most persistent structural inefficiencies: the disconnect between those who contribute intelligence and those who capture its value. If builders increasingly view data attribution and incentive alignment as necessary infrastructure rather than optional features, OpenLedger’s approach becomes much easier to understand.
