Tôi từng nghĩ “fair” trong AI Web3 là một chuyện khá dễ hiểu.
Ai góp dữ liệu thì được ghi nhận. Ai tạo ra giá trị thì được trả tiền. Ai tham gia xây mạng lưới thì có phần trong mạng lưới. So với thế giới Web2, nơi dữ liệu người dùng bị hút vào black box rồi trở thành tài sản của vài công ty lớn, cách đó nghe sạch hơn rất nhiều.
Nhưng càng nhìn OpenLedger dưới góc kinh tế, tôi càng thấy chữ “fair” này không đơn giản như vậy.
OpenLedger đang cố sửa một vấn đề thật. Trong AI Web2, người dùng cung cấp hành vi, nội dung, phản hồi, dữ liệu, nhưng phần lớn giá trị cuối cùng lại chảy về công ty sở hữu model. Người đóng góp gần như vô hình. Họ là nguyên liệu, nhưng không được đối xử như supplier.
OpenLedger muốn đảo lại điều đó.
Datanet giúp dữ liệu ngách có nơi được tổ chức. Proof of Attribution giúp hệ thống biết ai đã đóng góp gì vào quá trình tạo ra giá trị. Reward giúp người đóng góp không còn chỉ là nguồn nguyên liệu miễn phí. Nhìn ở tầng nguyên tắc, đây là một nỗ lực công bằng hơn Web2.
Nhưng vấn đề nằm ở chỗ: minh bạch hơn không tự động có nghĩa là công bằng hơn.
Một thị trường mở không tự động là một thị trường phẳng.
Nó chỉ đảm bảo mọi người có thể bước vào cùng một cánh cửa. Còn mỗi người mang theo loại tài sản gì lại là câu chuyện khác.
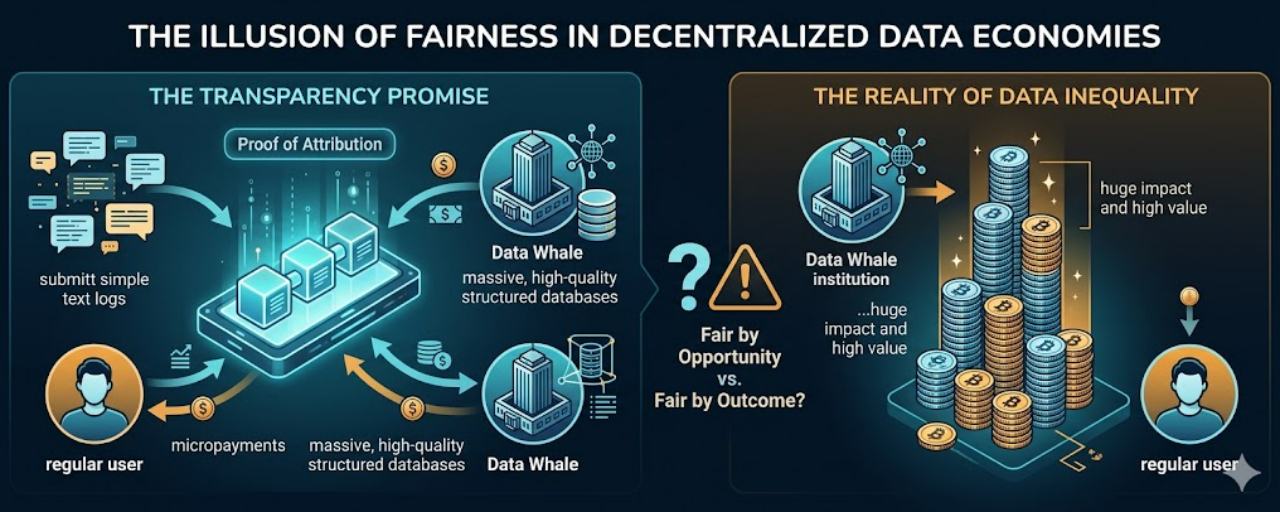
Đây là nghịch lý đầu tiên của OpenLedger.
Về lý thuyết, ai cũng có thể đóng góp dữ liệu. Một người dùng cá nhân có thể góp hành vi, nhãn dữ liệu, phản hồi, hoặc dữ liệu từ trải nghiệm của mình. Nhưng một bệnh viện lớn có kho bệnh án sạch, một quỹ tài chính có dữ liệu giao dịch chất lượng cao, một team security có database exploit hiếm, một doanh nghiệp có log vận hành nhiều năm, họ bước vào thị trường với loại tài sản hoàn toàn khác.
Cùng là “data contributor”, nhưng không cùng vị thế.
Một bên góp vài mảnh dữ liệu nhỏ lẻ.
Một bên mang cả kho nguyên liệu cao cấp.
Nếu Proof of Attribution vận hành đúng, hệ thống sẽ trả nhiều hơn cho dữ liệu tạo ra nhiều impact hơn. Về mặt thuật toán, điều đó hợp lý. Ai đóng góp nhiều giá trị hơn thì nhận nhiều hơn.
Nhưng chính chỗ hợp lý đó lại tạo ra vấn đề.
PoA càng chính xác, sự chênh lệch giữa data nhỏ lẻ và data whale càng hiện rõ.
Không phải vì cơ chế thiên vị. Mà vì thị trường dữ liệu ban đầu đã không trung lập.
Một người dùng phổ thông có thể được “trao quyền”, nhưng phần reward lớn vẫn có khả năng chảy về những bên đã sở hữu dữ liệu hiếm, sạch, có cấu trúc và có giá trị thương mại cao từ trước.
Nói hơi thẳng: OpenLedger có thể phá thế độc quyền dữ liệu của Big Tech, nhưng điều đó không có nghĩa nó tự động phá được bất bình đẳng dữ liệu giữa các nhóm người tham gia.
Đây là chỗ chữ “fair” bắt đầu khó.
Fair với ai?
Fair theo quyền tham gia, hay fair theo kết quả nhận được?
Nếu ai cũng được tham gia, đó là một kiểu công bằng. Nhưng nếu người đã mạnh từ đầu vẫn nhận phần lớn dòng tiền vì họ có tài sản dữ liệu tốt hơn, đó lại là một thực tế khác.
Tôi không nghĩ OpenLedger sai ở đây. Một hệ thống trả thưởng theo giá trị đóng góp không thể giả vờ mọi dữ liệu ngang nhau. Dữ liệu bệnh án sạch không thể được trả giống vài dòng khảo sát hời hợt. Dữ liệu security hiếm không thể được đối xử như dữ liệu spam. Nếu làm vậy, hệ thống sẽ tự phá incentive chất lượng.
Nhưng nếu chỉ trả theo impact thị trường, hệ thống rất dễ tạo ra một lớp data whale mới.
Đó là nghịch lý: muốn fair với chất lượng, có thể phải chấp nhận bất bình đẳng phần thưởng.
Vấn đề thứ hai nằm ở cộng đồng.
OpenLedger có thể nói nhiều về community ownership, và việc dành phần lớn nguồn lực cho cộng đồng nghe rất mạnh. Nhưng trong Web3, “cộng đồng” không phải một khối thống nhất.
Cộng đồng nhỏ lẻ thường phân mảnh. Mỗi người có ít token, ít thời gian, ít thông tin, ít chuyên môn và ít động lực theo sát governance dài hạn. Trong khi đó, các nhóm lớn có vốn, dữ liệu, node, đội vận hành và khả năng phối hợp tốt hơn nhiều.
Một cộng đồng có nhiều token trên giấy nhưng không phối hợp được vẫn có thể yếu hơn một nhóm nhỏ nắm ít token hơn nhưng hành động như một khối.
Đây không phải vấn đề riêng của OpenLedger. Đây là vấn đề rất thật của governance Web3.
Fairness không chỉ nằm ở phân bổ. Nó nằm ở khả năng biến phân bổ đó thành quyền lực thực tế.
Nếu người dùng nhỏ lẻ có phần trong hệ thống nhưng không đủ khả năng ảnh hưởng luật chơi, họ vẫn có thể ở vị trí yếu. Họ được tham gia, nhưng không chắc được quyết định. Họ được reward, nhưng không chắc định hình được cách reward vận hành.
Vấn đề thứ ba còn khó hơn: fair với contributor có thể không fair với consumer.
Một hệ thống muốn trả thưởng xứng đáng cho người góp dữ liệu thì chi phí đó phải đến từ đâu đó. Nếu reward cho data contributor, model maintainer, node operator và các bên trong mạng quá cao, chi phí inference có thể bị đẩy lên.
Khi đó người mua dịch vụ AI phải trả nhiều hơn.
Với người góp dữ liệu, đó là công bằng.
Với doanh nghiệp hoặc user cuối, đó có thể là bất lợi.
Trong một hệ thống kinh tế, fair với một bên gần như luôn là cost của một bên khác.
Đây là phần thường bị bỏ qua khi nói về fairness. Ta hay nói công bằng như một giá trị đạo đức tuyệt đối, nhưng trong thị trường thật, công bằng luôn đi kèm câu hỏi phân bổ chi phí.
Ai được trả thêm?
Ai trả khoản đó?
Ai bị đẩy ra ngoài vì giá cao hơn?
Nếu OpenLedger muốn cạnh tranh với dịch vụ AI tập trung, nó không thể chỉ tối đa hóa reward cho contributor. Nó còn phải giữ sản phẩm đủ rẻ, đủ nhanh, đủ tiện để người dùng cuối có lý do sử dụng.
Nếu không, hệ thống có thể rất fair với bên cung cấp dữ liệu, nhưng lại kém hấp dẫn với bên tạo demand.
Và khi demand yếu, cuối cùng contributor cũng không còn gì để được fair.
Đây là lý do tôi nghĩ chữ “fair” của OpenLedger không nên được hiểu như một trạng thái đã đạt được nhờ blockchain, tokenomics hay attribution.
Nó là một bài toán phải được cân bằng liên tục.
Fairness không nằm ở việc mọi người đều được trả tiền. Câu đó dễ quá.
Fairness nằm ở những câu hỏi khó hơn: ai có dữ liệu tốt nhất, ai có quyền định giá dữ liệu đó, ai đủ sức tham gia governance, ai chịu chi phí vận hành, ai được hưởng reward lớn nhất, và người dùng cuối có còn được phục vụ với mức giá hợp lý hay không.
Tôi thích tham vọng của OpenLedger ở chỗ nó dám chạm vào vấn đề mà Web2 thường né: dữ liệu của con người không nên bị khai thác vô hình.
Nhưng tôi cũng không nghĩ chỉ cần đưa dữ liệu lên một cơ chế attribution là công bằng tự xuất hiện.
Proof of Attribution có thể làm đóng góp minh bạch hơn.
Nhưng minh bạch không tự động làm thị trường công bằng hơn.
Đôi khi nó chỉ làm bất bình đẳng hiện rõ hơn.
Và có lẽ đó mới là bài test thật của OpenLedger.
Không phải dự án có nói về fair hay không. Dĩ nhiên là có.
Câu hỏi là khi hệ thống lớn lên, chữ fair đó sẽ nghiêng về ai.
Nghiêng về người dùng nhỏ lẻ hay data whale?
Nghiêng về cộng đồng rộng hay nhóm phối hợp tốt nhất?
Nghiêng về contributor hay consumer?
Nghiêng về người tạo dữ liệu thật hay người có khả năng đóng gói dữ liệu thành tài sản thương mại tốt hơn?
Tôi không nghĩ câu trả lời đã rõ.
Nhưng nếu OpenLedger muốn chữ fair trở thành lợi thế thật, dự án không thể chỉ dừng ở “ai đóng góp thì được reward”.
Câu hỏi khó hơn là: hệ thống có ngăn được những người đã mạnh từ trước trở thành người được trả tiền nhiều nhất hay không?
Vì OpenLedger có thể làm dữ liệu minh bạch hơn Web2.
Nhưng nếu không cẩn thận, sự minh bạch đó chỉ tạo ra một thị trường mới, nơi bất công cũ quay lại dưới hình thức sạch hơn, có ví hơn, có dashboard hơn, và trông công bằng hơn trên bề mặt.
#OpenLedger $OPEN @OpenLedger $LAB
