Saya sudah memperhatikan @OpenLedger selama beberapa waktu — terutama karena posisi $OPEN di sekitar atribusi data AI terasa benar-benar berbeda dari pitch "kami sedang membangun infrastruktur" yang biasa. Tapi hari ini saya mulai membaca tokenomics mereka dengan lebih teliti. Bukan ringkasan. Pembagian distribusi yang sebenarnya.
Dan saya terjebak pada sesuatu yang belum bisa saya lepaskan sejak saat itu.
Kerangka standar di sekitar OpenLedger adalah bahwa mereka membangun jenis ekonomi baru — di mana model AI harus membayar untuk data yang mereka konsumsi, dan orang-orang yang menyumbangkan data tersebut sebenarnya mendapatkan kompensasi. Atribusi di on-chain. Provenance yang dapat diverifikasi. Lingkaran insentif yang bersih. Saya tertarik dengan kerangka itu. Kebanyakan orang yang meliput proyek ini sepertinya juga.
Tapi inilah di mana sesuatu bergeser bagi saya.
Saat saya melihat jadwal pembukaan, alokasi tim dan investor — sekitar sepertiga dari total $OPEN suplai — tidak mencapai sampai sekitar September 2026. Itu adalah pembukaan tebing. Bukan tetesan bertahap. Sebuah dinding. Dan waktu itu tepat di tepi saat proyek secara teoritis mulai menghasilkan pendapatan berbasis penggunaan yang nyata, dengan asumsi kurva adopsi benar-benar terjadi.
Jadi inilah yang terus saya pikirkan: keseluruhan narasi "ekonomi data AI" mengasumsikan bahwa aliran nilai berasal dari penggunaan. Model mengkonsumsi data, kontributor mendapatkan imbalan, token menangkap pertukaran itu. Tapi jika peristiwa suplai terbesar dalam sejarah $OPEN mendarat tepat ketika jaringan seharusnya membuktikan dirinya sendiri — siapa sebenarnya yang memposisikan untuk model jangka panjang, dan siapa hanya menunggu sampai jendela keluar terbuka?
Saya pikir dua hal itu terpisah. Narasi dan vesting. Tapi saya tidak yakin mereka terpisah.
Ada versi dari ini di mana itu tidak merusak sama sekali. Tim membutuhkan runway. Investor awal mengambil risiko nyata. Struktur tebing adalah standar. Saya tahu ini. Tapi ada sesuatu yang tidak nyaman tentang proyek yang tawarannya adalah "kami mengubah cara model AI membayar untuk informasi" mendarat di acara pembukaan terbesar pada saat cerita itu perlu dikonfirmasi oleh data on-chain. Itu bukan konspirasi. Itu hanya kebetulan struktural yang canggung yang saya pikir kebanyakan orang yang meliput open tidak duduk cukup lama.
Bagian yang paling mengganggu saya lebih halus daripada pembukaan itu sendiri. Ini adalah model atribusi data — asli atau tidak — hampir tidak mungkin untuk divalidasi saat ini. Anda dapat melihat aliran dompet. Anda dapat melihat partisipasi staking. Tetapi apakah operator model AI benar-benar membayar untuk asal-usulnya, atau apakah itu masih janji lapisan whitepaper yang dihias dengan estetika on-chain — saya benar-benar tidak bisa tahu dari luar. Dan saya tidak yakin kebanyakan peserta ritel juga bisa.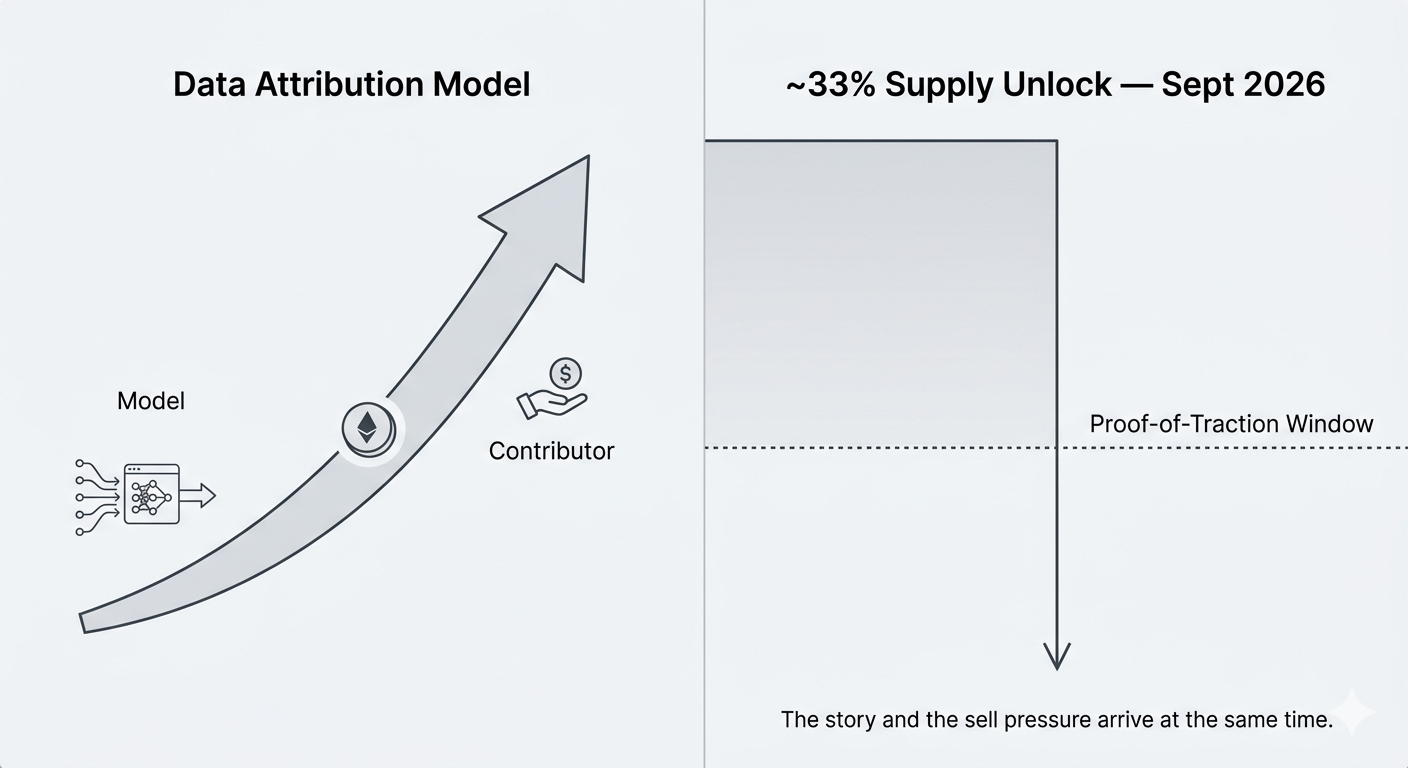
Yang berarti narasi melakukan banyak pekerjaan berat.
Itu tidak unik untuk OpenLedger. Kebanyakan proyek Web3 hidup dari narasi sampai mekanisme diuji secara stres. Tapi alasan ini duduk di sini khususnya adalah karena narasi tentang transparansi — tentang akhirnya membuat aliran data AI terlihat dan dapat dipertanggungjawabkan. Dan yet bagian yang paling penting saat ini, sinyal perilaku aktual dari konsumen data dan operator model, sebagian besar tidak transparan.
Saya tidak mengatakan model ini tidak berfungsi. Saya mengatakan saya akan merasa lebih yakin tentang $OPEN at harga $X jika pembukaan tebing tidak tepat berada di atas jendela di mana jaringan perlu membuktikan traksi. Dua hal itu bersama-sama meminta banyak dari pemegang ritel untuk menyerapnya dengan tenang.