The image that keeps returning to me is not a machine. It is a family tree.
Not the kind we draw for people, but one for intelligence itself. Every idea connected to another idea. Every conclusion tracing back to a source. Every insight carrying a history of who contributed to it and how it came into existence.
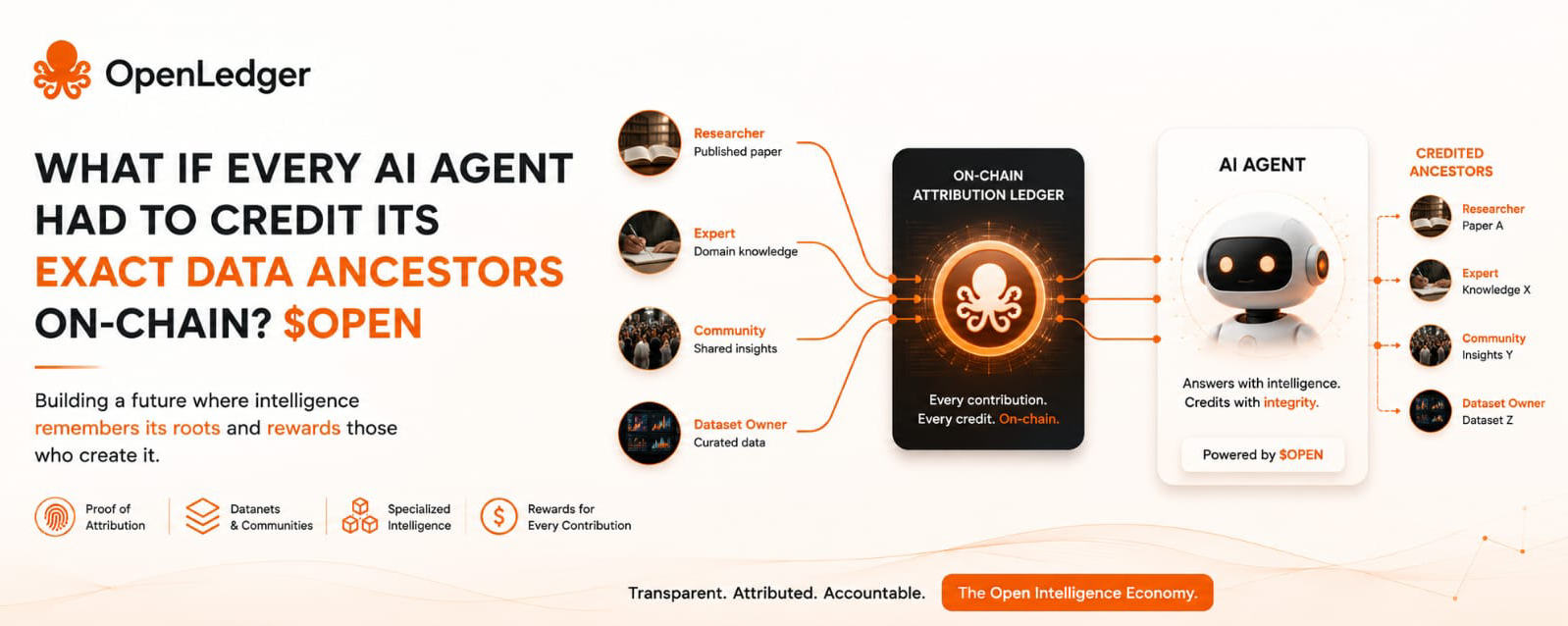
The more I think about AI agents, the more I wonder if we are missing something surprisingly fundamental. We spend enormous amounts of time discussing what these systems can do, yet very little time asking a simpler question: where did their knowledge actually come from?
An AI agent can summarize research, generate strategies, analyze markets, and answer complex questions in seconds. To most users, the output appears almost magical. But behind every response sits a hidden lineage of data, expertise, and human effort. Researchers wrote papers. Communities shared knowledge. Specialists documented years of experience. Someone, somewhere, created the information that made the answer possible.
Yet once that knowledge enters the model, the trail often disappears.
I used to think this was simply an unavoidable consequence of how AI works. Data goes in, intelligence comes out, and somewhere in between the origins become impossible to see. But the deeper I looked into the emerging infrastructure around AI, the more I started questioning that assumption.
What if intelligence could keep a memory of its own ancestry?
What if every AI agent carried a verifiable record of the data, communities, and contributors that helped shape its capabilities?
This is one of the reasons OpenLedger caught my attention.
Rather than viewing intelligence as a black box, OpenLedger appears to be exploring a future where attribution becomes part of the architecture itself. The concept of Proof of Attribution is particularly interesting because it shifts the conversation away from outputs alone and toward origins. Instead of asking only what an AI agent knows, it raises the possibility of asking where that knowledge came from.
That distinction may sound subtle, but I suspect it could become increasingly important as AI systems become more economically valuable.
One thing keeps coming back to me: every mature economy eventually develops mechanisms for tracking ownership. We know who owns assets. We know who created products. We know who contributed labor. Yet when it comes to intelligence, we often treat contribution as something that dissolves the moment a model is trained.
The result is a strange paradox. The people creating value are frequently the hardest people to see.
This made me pause and reconsider whether the future of AI is really a race toward larger models, or whether it is also a race toward better attribution. After all, intelligence is not generated in isolation. It emerges from networks of knowledge, communities of expertise, and countless individual contributions layered over time.
If those contributions remain invisible, the incentives that sustain them may weaken. But if they become visible, attributable, and economically meaningful, an entirely different ecosystem could emerge.
That possibility seems closely connected to OpenLedger's broader vision. Through ideas such as Datanets and attributed intelligence infrastructure, the project appears to be exploring how specialized knowledge can remain connected to the people and communities that create it.
I do not know whether the future will require every AI agent to credit its exact data ancestors on-chain. But the fact that the question can now be asked feels significant in itself.
For years, we have focused on teaching machines to remember more. Perhaps the next challenge is teaching intelligence to remember where it came from.
And if that becomes possible, the bigger question may not be how powerful AI becomes, but how differently we build it once memory, ownership, and contribution are no longer invisible.