I once noticed something while using a few crypto applications during a period of high network activity.
A Basic transac tion that normally Completes in seconds stayed pending for longer than expected. There was no error and noclear sign of failure. It just did not move. At first I treated it as a small delay, But then I saw a similar pattern in another app around the same time. That made me think it was not just random. It felt more like something in the system was under strain.
What stood out to me is how often crypto systems behave this way. They rarely fail in a clear or visible way. Instead, they become uneven. Some actions go through instantly while others slow down without any obvious reason from the user side. the system is still working, but the experience becomes inconsistent.
from a system perspective, this usually comes down to coordination between layers rather than raw speed. Execution, scheduling, verification, and data flow all depend on each other. Even if each part is functioning correctly on its own, timing differences between them can create delays that are hard t0 trace. The system does not break, but it stops feeling predictable.
I often compare it to a busy airport during peak hours.
When traffic is light, everything feels smooth. Flights are on time, baggage moves without issues, and coordination is almost invisible. But when the airport gets crowded, the main problem is no longer individual performance. It is flow. A delay in one area, even a small one, starts affecting everything else connected to it.
When I look at how @OpenLedger approaches this, what caught my attention is that it seems to focus more on system structure than just execution speed. It feels like the goal is not only to process work, but to manage how work moves through different parts of the system.
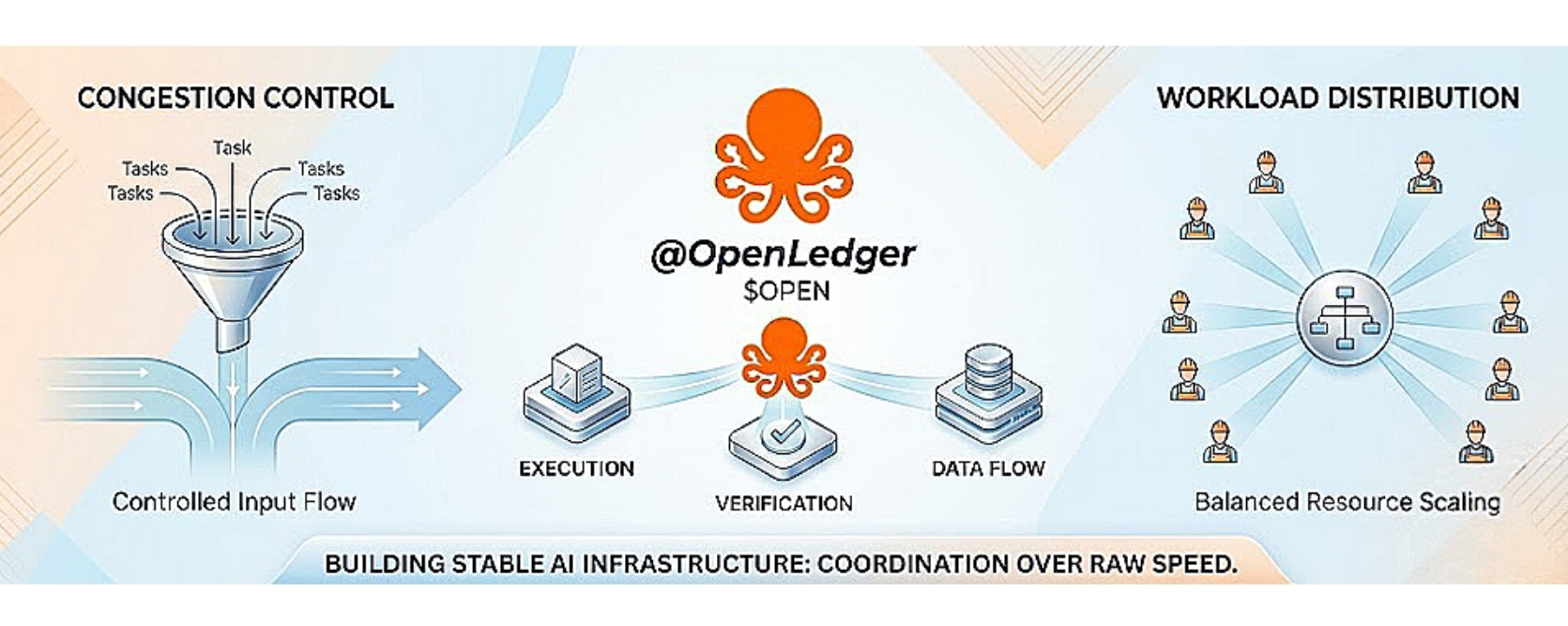
what matters in practice is how scheduling is handled. Scheduling is not just about deciding order. It shapes how pressure enters the system. If too many tasks arrive at once, even a strong system starts to struggle. A more controlled flow makes the system easier to manage under load.
Task separation is another important part. In many systems, tasks are split into parts, but they still rely on shared steps or shared data. That means they are not fully independent. What interests me more is whether those hidden dependencies are accounted for or whether they only show up as bottlenecks when demand increases.
Verification flow also plays a key role. Results are not useful if they cannot stay consistent as they move through the system. If verification is too tightly tied to execution, it can slow everything down. If it is too separate, consistency becomes harder to maintain. The balance between those two is important.
Congestion control is another area that stands out. In real systems, overload is normal, not rare. The question is how the system behaves when it happens. A stable system does not try to push through at full speed no matter what. It adjusts, slows down when needed, and prevents pressure from building up in one place.
Worker scaling and workload distribution also matter more than they first appear. Adding more capacity does not help much if the work is still funneled into the same bottleneck. What matters is whether the system can actually spread work evenly so that scaling improves balance instead of just increasing activity.
there is also a constant tradeoff between ordering and parallel execution. Ordering makes systems easier to reason about, but it limits throughput. Parallel execution improves speed, but it requires careful coordination to avoid inconsistency. Most systems end up balancing both depending on the type of workload.
what I keep coming back to is that infrastructure problems are rarely about single points of failure. They are about how multiple parts behave together when conditions are not ideal. That is where most of the real stress shows up.
In my experience watching systems evolve, the ones that hold up best are not the ones that look perfect under normal conditions. They are the ones that stay stable when demand is uneven and pressure is spread across different layers.
A good system is not the one that feels fast when everything is quiet. It is the one that stays consistent when everything is under load.
Good infrastructure usually does not draw attention to itself. It just keeps working in the background without creating confusion.