I once noticed something that didn’t feel important in the moment, but it stayed with me longer than expected. I was checking a simple onchain data point across a few dashboards, and I assumed the result would be identical everywhere. Instead, I kept seeing small differences. Not enough t0 call it a failure, but enough to make me stop and wonder why the same “truth” looked slightly different depending on where I was viewing it.
That experience changed how I look at crypto infrastructure.
Because in most systems, the real friction is not obvious downtime. It’s the quiet inconsistencies that appear when data moves through multiple layers. A transaction is not just a transaction anymore once it passes through indexing services, analytics pipelines, AI models, and caching layers. Each layer adds convenience, but also a subtle risk of losing context. And once context starts to fade, verification becomes something you repeat instead of something you inherit.
what I noticed over time is that scaling makes this worse, not better. When networks are small, you can still mentally reconstruct what happened. But at scale, reconstruction becomes guesswork. You stop trusting your intuition and start relying entirely on infrastructure you cannot see. From a system perspective, that shift is more important than speed or throughput.
A simple analogy that helped me understand this is a busy shipping port. Containers move quickly, ships arrive on time, everything looks efficient on the surface. But if tracking labels are inconsistently updated at each checkpoint, then locating the origin of a specific item becomes harder the further it travels. The system still “works,” but traceability becomes fragile under load.
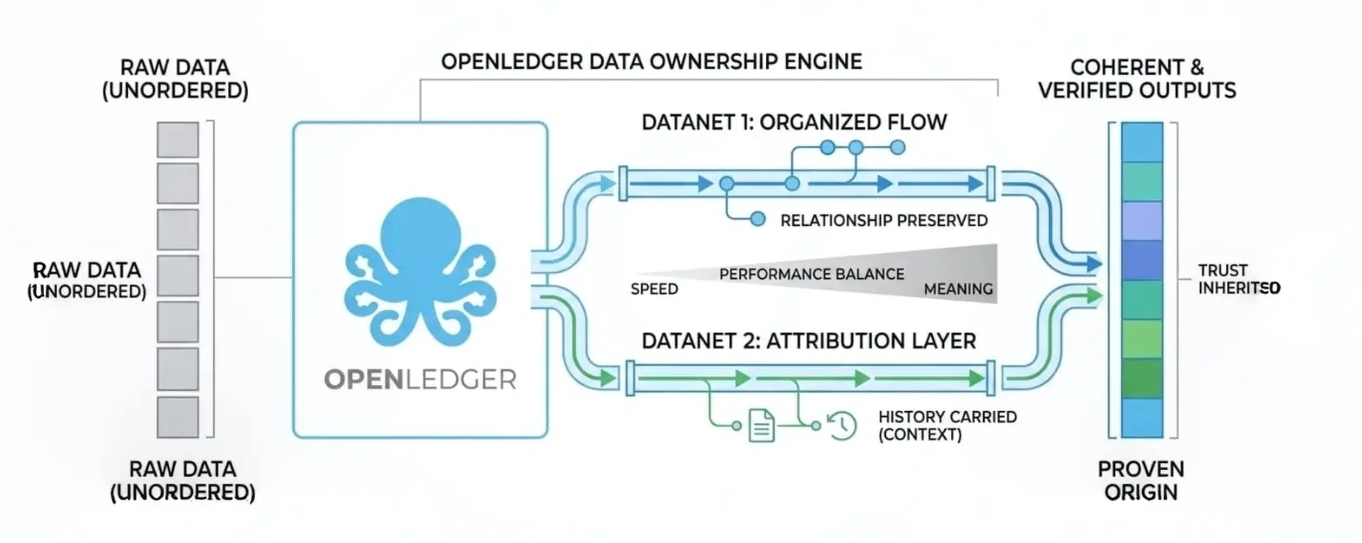
When I look at how @OpenLedger approaches this, what stands out to me is not just the idea of data processing, but how it tries to preserve data meaning as it moves. The concepts of datanets and attribution systems feel like an attempt to make data carry its own history instead of losing it between transformations.
What interests me more is how this changes the structure 0f the system itself.
datanets, as I understand them, are not just pipelines. They are organized flows where data is grouped and routed in a way that keeps relationships intact. So instead of isolated events, you get connected paths of information. Attribution then becomes a natural layer on top of that, showing how outputs were formed rather than trying to reconstruct it later.
from a system perspective, this introduces a different set of constraints.
Scheduling is no longer just about efficiency. It becomes about preserving traceability while still keeping throughput stable. Task separation helps distribute load, but it also has to ensure that context does not break across boundaries. If tasks are too fragmented, attribution becomes incomplete. If they are too tightly coupled, the system loses scalability.
Verification flow is another place where balance matters. In real systems, verification cannot be too heavy, or it slows everything down. But if it is too light, you end up with fast outputs that are difficult to trust. So the design challenge is not verification itself, but how verification is embedded without interrupting movement.
Congestion control also becomes more subtle here. It is not only about compute limits or network bandwidth. It is about how much contextual information can travel alongside data before it starts degrading performance. In other words, the system is always balancing meaning against speed.
Worker scaling adds another layer to this. When more nodes participate, consistency becomes harder. Not just in execution, but in how outputs are recorded and attributed. A system is only as strong as its weakest point of interpretation, not just its processing power.
And then there is ordering versus parallelism. Parallel execution improves efficiency, but attribution often depends on understanding sequence. What matters in practice is not choosing one, but designing a structure where parallel work does not destroy the ability to trace how results were produced.
Backpressure, in that sense, becomes less of a technical feature and more of a stabilizer. It quietly prevents the system from accepting more than it can coherently track, which is often where large infrastructures start to lose clarity without visibly failing.
Over time, I have started to think that most infrastructure problems don’t appear as breakdowns. They appear as uncertainty. Not knowing what changed. Not knowing where something came from. Not being able to reconstruct meaning without extra effort. And at scale, that uncertainty becomes the real cost.
A strong system, from what I have observed, is not the one that only performs well under ideal conditions. It is the one that stays consistent when everything is moving fast and nothing is standing still long enough to inspect manually.
Good infrastructure doesn’t draw attention to itself. It just keeps information coherent while everything else becomes complex around it.