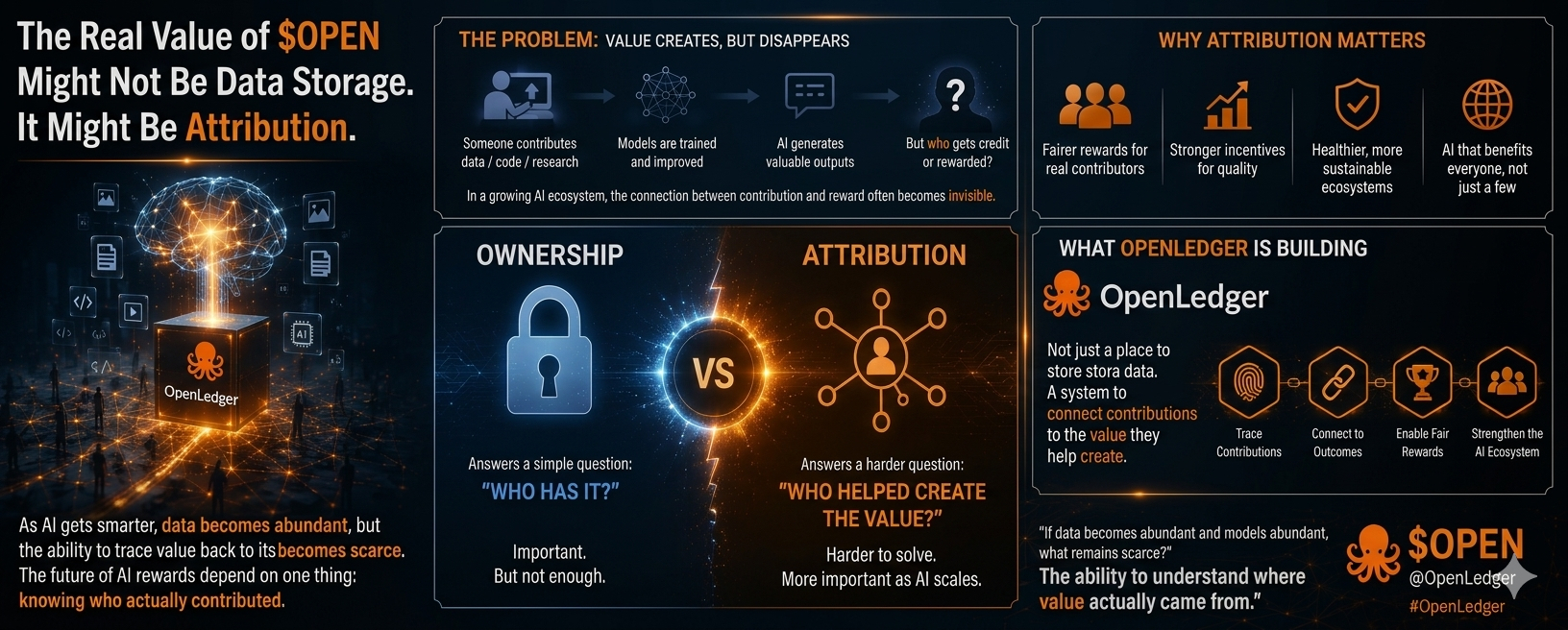
The Real Value of $OPEN Might Not Be Data Storage. It Might Be Attribution. Let me admit something that feels a little uncomfortable. The more AI improves, the less certain I become about who actually gets rewarded for creating its value. Most conversations about AI focus on scale. Bigger models. More data. More compute. Faster systems. Every project seems to be competing to prove it can process more information than the last one. But lately, I've been thinking about a different question. What happens after the data is used? More specifically, how do we know who contributed to the value an AI system creates? That's the part that keeps pulling my attention. Data is no longer rare. Every day, enormous amounts of information are generated across the internet. Storage is getting cheaper. Collection is becoming easier. New datasets appear constantly. What still feels difficult is tracing value back to its source. If an AI model produces a useful result, who helped make that possible? Was it the person who contributed the data? The researcher who improved the model? The community that spent years building knowledge around a specific topic? In theory, all of them played a role. In practice, the connection often becomes difficult to see. I've seen something similar happen in crypto. Many of the people creating value operate behind the scenes. Infrastructure providers, validators, liquidity providers, and contributors help entire ecosystems function, yet most users rarely notice them. The value exists. The visibility doesn't. AI seems to be moving in the same direction. Everyone talks about models because models are what people interact with. But behind every AI response is a long chain of contributors whose influence becomes harder to track as systems grow larger. A dataset uploaded months ago can still affect outcomes today. A model improvement made by one contributor can benefit thousands of future users. Value is being created across the network, but the path connecting contribution and reward often becomes invisible. That's why OpenLedger caught my attention. At first, I assumed the main idea was data ownership. Own your data. Control your data. Monetize your data. Those are important concepts. But the more I looked into it, the more I felt the bigger challenge might be attribution. Ownership answers a simple question: "Who has it?" Attribution tries to answer a harder one: "Who helped create the value?" That difference becomes increasingly important as AI ecosystems grow. When contributors cannot see how their work connects to outcomes, incentives start drifting away from actual value creation. And when incentives break, ecosystems eventually struggle. This is where OpenLedger's focus on attribution feels interesting. The goal isn't simply storing information. It's creating a system where contributions remain connected to the value they help generate. Of course, I don't think any attribution system is perfect. Large networks are complicated. Participants optimize for rewards. Metrics can be gamed. Real world behavior often exposes weaknesses that look invisible on paper. That's true for crypto. It's true for AI. And it will probably remain true for both. So I don't view attribution as a solved problem. I view it as an important one. A lot of people are focused on building smarter AI. Maybe we should also spend time building AI ecosystems that make value creation easier to understand. Because if AI eventually becomes a network powered by countless contributors, attribution stops being a feature. It becomes infrastructure. And infrastructure is usually most important when nobody notices it. Whether OpenLedger ultimately succeeds is something only time can answer. But I keep returning to the same question: If data becomes abundant and models become abundant, what remains scarce? From where I'm standing, the answer might not be storage. It might be the ability to understand where value actually came from. And that's a problem worth paying attention to.