I once noticed something while working with different crypto data tools that made me rethink how much we actually trust what we see on screen.
I was comparing the same onchain activity across a few platforms, and I expected them to line up perfectly. But they didn’t. The differences were small, but consistent enough to raise questions. One tool would show slightly different timing. Another would show a different interpretation of the same event. Nothing was “wrong” in isolation, but together it felt fragmented.
That is when it became clear to me that the real challenge in crypto infrastructure is not just recording data. It is keeping that data meaningful as it moves through many systems.
In practice, blockchain data does not stay in its raw form for long. It gets picked up by indexers, reshaped by APIs, interpreted by analytics layers, and increasingly consumed by AI systems. Each layer adds usefulness, but also introduces a risk. The risk is not corruption. It is separation from origin. Over time, it becomes harder to answer a simple question: where did this data actually come from, and what happened to it before I saw it?
A simple analogy I keep coming back to is a global warehouse network. Goods move efficiently across regions, but every hub has its own internal process for labeling, sorting, and tracking. The system does not fail, but tracing the full journey of a single item becomes harder the more steps it goes through. Efficiency increases, but clarity slowly weakens.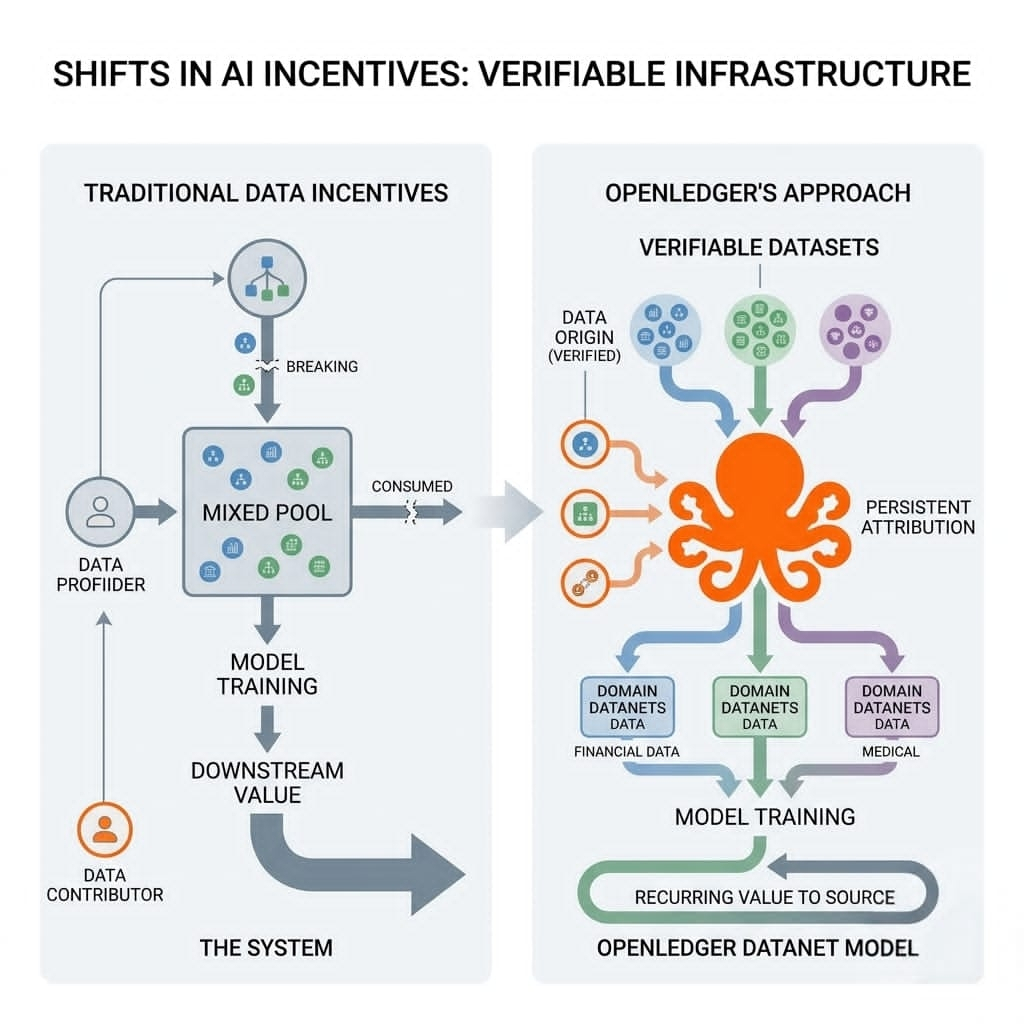
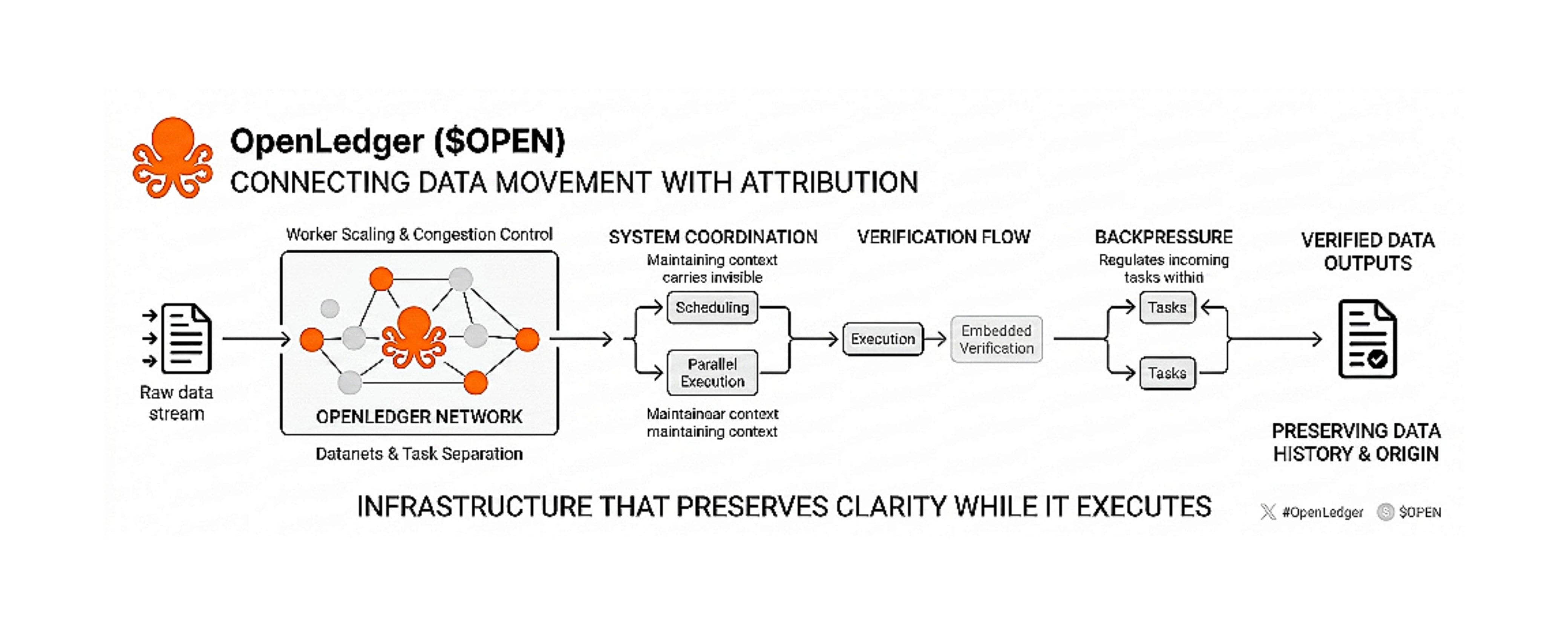
When I look at how @OpenLedger structures this problem, what stands out to me is the focus on connecting data movement with attribution at the system level, not as an afterthought.
The idea behind datanets and attribution systems, from my understanding, is to treat data as something that carries its own history as it moves. Not just storing outputs, but preserving the path that produced them. That shift changes how the entire system is designed.
From a system perspective, tokenomics is not just about distribution. It becomes part of coordination. It influences how data is created, processed, verified, and passed through the network.
What matters more is how the system behaves under real pressure.
Scheduling is not just about throughput. It is about deciding how data and tasks flow so that relationships between inputs and outputs are not lost. If scheduling is too fragmented, attribution becomes unclear. If it is too rigid, the system cannot scale efficiently.
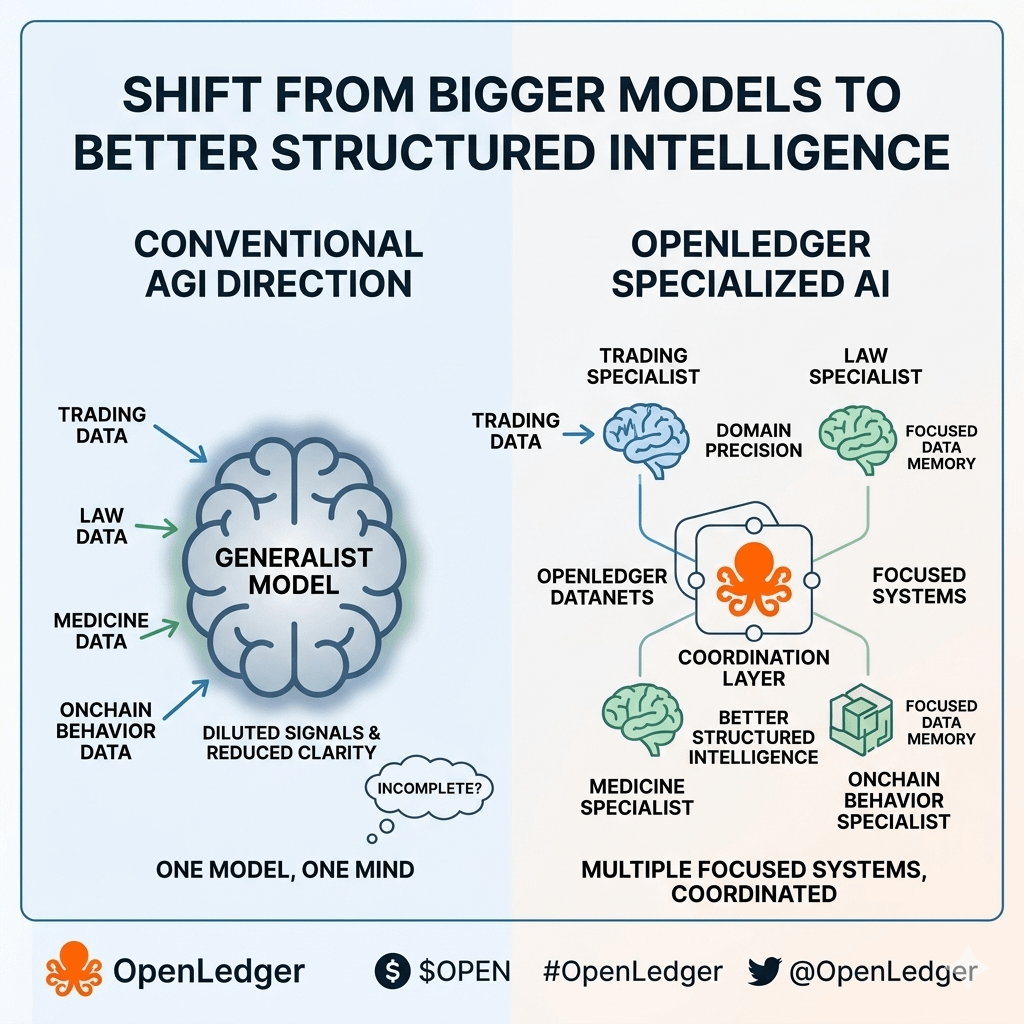
Task separation plays a similar role. Breaking work into smaller units helps distribute load, but it also increases the number of points where context can be lost. So the system has to ensure that separation does not break continuity.
Verification flow is another key layer. If verification is too heavy, it slows the system and becomes a bottleneck. If it is too light, outputs lose reliability. What matters is embedding verification in a way that stays close to execution without interrupting it.
Congestion control is not only about compute or network traffic. It is also about how much contextual information can travel with each piece of data. In OpenLedger’s direction of design, this becomes important because attribution depends on preserving context without overwhelming the system.
Worker scaling adds another challenge. As more participants join the network, consistency becomes harder to maintain. Not just in speed, but in how work is recorded and interpreted. Scaling only works if outputs remain structurally consistent across all contributors.
Then there is ordering versus parallelism. Parallel execution is necessary for scale, but attribution often depends on understanding sequence. The challenge is not choosing one over the other, but designing a system where parallel processes still preserve a traceable chain of how outputs were formed.
Backpressure is what quietly holds this together. It prevents the system from accepting more work than it can track and verify properly. It is not about slowing things down unnecessarily, but about protecting coherence when load increases.
From what I observe in OpenLedger’s direction, the deeper idea is not just handling AI or data workloads. It is making sure that as these systems scale, the origin and transformation of data do not get lost in the process.
Over time, I have started to think that the real problem in infrastructure is not performance alone. It is whether the system can still explain itself when everything is running at full speed.
A reliable system is not the one that processes the most. It is the one that still stays understandable when everything is moving at once.
Good infrastructure does not just execute. It preserves clarity while it executes.
