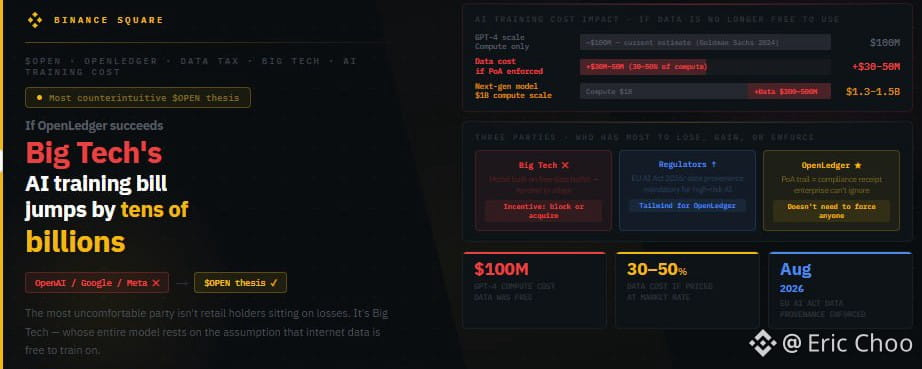
Gue mulai mikir tentang ini setelah baca angka di laporan Goldman Sachs 2024: diperkirakan biaya untuk train GPT-4 sekitar 100 juta USD. Angka itu nggak termasuk cost of data, karena data diambil secara gratis dari internet. Kalo data nggak gratis, angka itu bakal berapa? Nggak ada yang tahu pasti, tapi banyak perkiraan bilang bahwa high-quality curated data bisa nyerap 30 sampai 50% nilai training kalo dinilai sesuai market rate. Dengan GPT-4, itu berarti 30 sampai 50 juta USD cuma untuk satu training run. Untuk model berikutnya mungkin bisa keluar 1 miliar USD untuk train, biaya data-nya bakal jadi 300 sampai 500 juta USD.
Ini adalah hal yang @OpenLedger dan $OPEN sedang berusaha bangun infrastruktur untuk: sebuah dunia di mana setiap dataset memiliki tag harga, setiap inferensi memiliki jejak royalti, dan laboratorium AI tidak dapat terus menjalankan model bisnis "buffet data gratis" seperti yang mereka lakukan. Bukan dengan hukum, bukan dengan advokasi, tetapi dengan layer protokol on-chain yang jika cukup diadopsi akan menjadi standar yang tidak bisa diabaikan.
Saya ingin mengatakannya secara langsung tentang sesuatu yang kedua file riset yang saya baca keduanya hint tetapi tidak secara eksplisit mengatakan. Model Spotify adalah contoh terdekat dengan apa yang OpenLedger coba lakukan. Sebelum Spotify, musisi kecil tidak mendapatkan apa-apa dari unduhan ilegal. Setelah Spotify, mereka mendapatkan micro-royalty setiap kali lagu diputar, meskipun jumlahnya kecil. Yang lebih penting, standar itu telah mengubah seluruh cara industri musik beroperasi. Bukan karena Spotify baik hati, tetapi karena mereka membangun infrastruktur yang cukup baik untuk menegakkan royalti secara skala dengan cara yang tidak bisa diabaikan oleh industri musik.
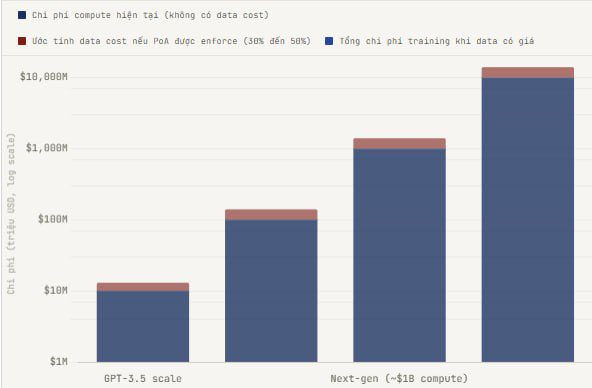
Masalahnya adalah OpenLedger tidak bisa memaksa Big Tech melakukan apa pun, setidaknya tidak dalam arti langsung. Google bisa terus melatih di Common Crawl secara gratis bahkan jika OpenLedger ada. Tidak ada yang bisa menghentikan itu dengan smart contract. Ini adalah titik lemah yang nyata dari tesis ini, dan saya pikir penting untuk mengatakannya daripada hanya menulis konten bullish sepihak.
Tetapi ini adalah cara OpenLedger bisa menciptakan perubahan bukan dengan penegakan langsung tetapi dengan alternatif: jika model yang dilatih di OpenLedger DataNet dengan data yang terverifikasi, terkurasi, dan spesifik domain secara konsisten lebih unggul daripada model yang dilatih di data internet yang berisik di domain yang diatur seperti kesehatan atau AI hukum, maka pembeli perusahaan akan lebih memilih model dari OpenLedger. Bukan karena mereka peduli tentang keadilan tetapi karena EU AI Act dan kerangka regulasi lainnya mulai mengharuskan dokumentasi provensi. Sebuah rumah sakit yang membeli alat diagnostik AI perlu membuktikan kepada regulator bahwa data pelatihan dari alat tersebut memenuhi standar kualitas. Jejak PoA OpenLedger memberikan tepat itu. Secara alami, tanpa perlu memaksa siapa pun.
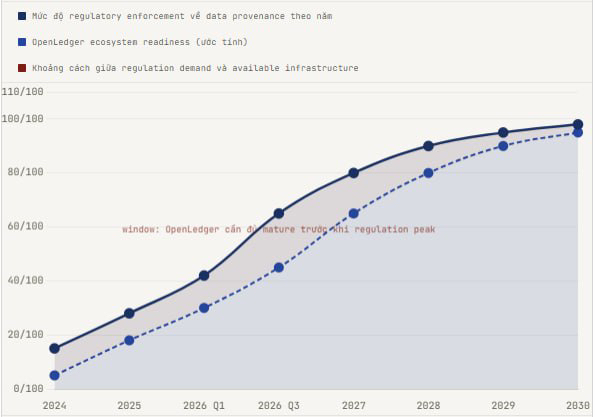
Ketika saya melihat daftar investor di OpenLedger, khususnya Balaji Srinivasan, yang telah memprediksi banyak perubahan teknologi besar sebelum pasar, itu memberi saya lebih banyak kepercayaan bukan karena Balaji selalu benar, tetapi karena dia biasanya hanya bertaruh ketika dia bisa melihat adanya angin regulatory yang jelas. EU AI Act, US AI Executive Order, dan kerangka pemerintahan AI Singapura semuanya mendorong ke arah keharusan provensi data. OpenLedger tidak perlu meyakinkan Big Tech. Mereka hanya perlu menunggu regulator melakukan itu untuk mereka.
 Hal yang membuat saya percaya pada tesis jangka panjang ini bukanlah hype atau FOMO. Itu adalah logika ekonomi yang sederhana. Dalam 20 tahun internet, segala sesuatu yang tampaknya gratis akhirnya akan dihargai. Email gratis, kemudian filter spam dan pemasaran email menjadi industri miliaran dolar. Pencarian gratis, kemudian SEO dan Google Ads menjadi bagian besar dari GDP internet. Media sosial gratis, kemudian ekonomi perhatian dan perantara data menjadi model bisnis Meta dan Twitter. Data AI gratis, lalu apa? OpenLedger bertaruh bahwa jawabannya adalah ekonomi atribusi, di mana setiap jejak data memiliki tag harga on-chain.
Hal yang membuat saya percaya pada tesis jangka panjang ini bukanlah hype atau FOMO. Itu adalah logika ekonomi yang sederhana. Dalam 20 tahun internet, segala sesuatu yang tampaknya gratis akhirnya akan dihargai. Email gratis, kemudian filter spam dan pemasaran email menjadi industri miliaran dolar. Pencarian gratis, kemudian SEO dan Google Ads menjadi bagian besar dari GDP internet. Media sosial gratis, kemudian ekonomi perhatian dan perantara data menjadi model bisnis Meta dan Twitter. Data AI gratis, lalu apa? OpenLedger bertaruh bahwa jawabannya adalah ekonomi atribusi, di mana setiap jejak data memiliki tag harga on-chain.
Saya tidak tahu garis waktu yang tepat. Mungkin 3 tahun. Mungkin 7 tahun. Tetapi ketika semua orang sedang short $OPEN karena nilainya turun 91%, saya melihat apa yang saya beli bukanlah token yang merugi. Itu adalah sebuah taruhan bahwa AI harus membayar untuk data seperti Netflix harus membayar untuk konten, dan OpenLedger sedang membangun infrastruktur untuk mengumpulkan uang tersebut.
Jika EU AI Act benar-benar menegakkan persyaratan tentang dokumentasi provensi data untuk sistem AI berisiko tinggi mulai tahun 2026, dan OpenLedger adalah infrastruktur satu-satunya yang memiliki jejak PoA on-chain yang cukup granular untuk memenuhi persyaratan itu, menurut Anda apakah Big Tech akan memilih untuk mengintegrasikan OpenLedger ke dalam alur kerja mereka atau akan membangun alternatif sendiri untuk menghindari ketergantungan pada protokol on-chain yang tidak mereka kendalikan?