Kebanyakan orang masih berbicara tentang AI seolah-olah ini adalah kontes tenaga kuda. Model yang lebih besar, lebih banyak GPU, waktu pelatihan yang lebih lama. Cerita itu tidak salah. Itu hanya... tidak lengkap dengan cara yang mulai mengganggu Anda setelah Anda benar-benar bekerja dekat dengan sistem-sistem ini.
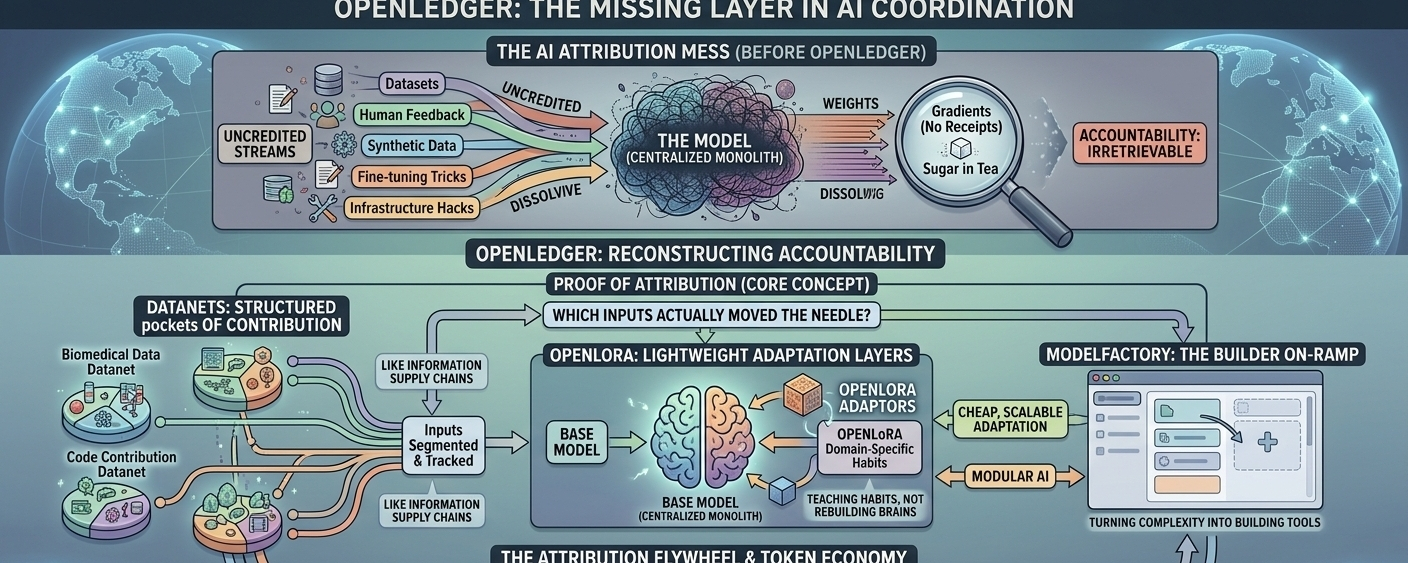
Karena kenyataan yang tidak nyaman adalah ini: AI modern sebenarnya tidak berasal dari satu tempat. Ini adalah campuran dari dataset, umpan balik manusia, data sintetis, trik penyempurnaan, hack infrastruktur, dan selusin kontributor tak terlihat yang tidak ada yang ingat untuk memberi kredit. Namun, kita masih bertindak seolah-olah semua ini dapat dikaitkan dengan 'model'.
Itu tidak.
OpenLedger pada dasarnya mulai dari kekacauan itu dan berkata: baiklah, mari berhenti berpura-pura.
Gagasan inti—Proof of Attribution—berusaha menjawab pertanyaan yang terdengar sederhana tetapi menjadi rumit dengan cepat setelah Anda menggali lebih dalam: jika sistem AI menghasilkan sesuatu yang berguna, siapa sebenarnya yang membuat hasil itu mungkin?
Bukan dalam arti samar 'dataset berkontribusi'. Lebih tepatnya: input mana yang sebenarnya menggerakkan jarum pada output itu?
Jika Anda pernah melatih atau bahkan menyesuaikan model, Anda tahu betapa licinnya ini. Semuanya bercampur. Gradien tidak membawa struk. Begitu data masuk pelatihan, itu larut menjadi bobot seperti gula dalam teh. Hilang. Tak terambil kembali dalam bentuk yang bersih.
Jadi OpenLedger berusaha untuk membangun kembali sesuatu yang kebanyakan sistem sengaja menyerah: akuntabilitas.
Dan sejujurnya… itu either ambisius atau sedikit gila, tergantung pada suasana hati Anda hari itu.
Tapi motivasinya masuk akal.
Karena AI tidak lagi hanya alat penelitian. Ini melayang ke dalam sistem keuangan, lapisan keputusan perusahaan, saluran konten, alur kerja agen yang melakukan sesuatu, bukan hanya menyarankannya. Pada titik itu, 'kami melatihnya dengan banyak data' mulai terdengar kurang seperti penjelasan dan lebih seperti mengangkat bahu.
Di situlah Datanets masuk.
Pikirkan mereka sebagai kantong terstruktur kontribusi. Bukan tumpukan data raksasa, tetapi ekosistem tersegmentasi di mana input dilacak, dikelompokkan, dan dibawa ke depan dengan beberapa pengertian tentang pengaruh yang tetap utuh.
Ini hampir seperti mencoba membangun kembali rantai pasokan… tetapi untuk informasi. Dan ya, analogi itu hancur jika Anda mendorongnya terlalu jauh, tetapi itu menyampaikan intuisi.
Perubahan kunci bersifat psikologis sama banyaknya dengan teknis. Kontributor tidak lagi tak terlihat. Setidaknya, itulah niatnya. Apakah itu benar-benar berfungsi dalam praktik adalah pertanyaan lain sama sekali.
Dan di sinilah saya akan blak-blakan: atribusi dalam pembelajaran mendalam itu berantakan. Hampir menyinggung. Anda selalu berurusan dengan pengaruh probabilistik, bukan kausalitas yang bersih. Jadi siapa pun yang mengharapkan pelacakan yang sempurna akan kecewa.
Tapi kesempurnaan bukanlah tujuan.
Bahkan atribusi yang tidak sempurna mengubah perilaku. Orang-orang menyusun data yang lebih baik ketika mereka tahu itu bisa dihargai. Mereka berpartisipasi lebih hati-hati ketika mereka tahu mereka bagian dari sistem yang dapat diukur. Itu mendorong insentif. Dengan tenang. Terkadang lebih dari teknologi itu sendiri.
Lalu ada OpenLoRA.
Bagian ini lebih terfokus, kurang filosofis. Ini tentang membuat adaptasi model murah dan dapat diskalakan. Alih-alih melatih model besar dari awal setiap kali Anda ingin perilaku spesifik domain, Anda menambahkan lapisan adaptasi ringan.
Dalam istilah sederhana: Anda tidak membangun kembali otak. Anda mengajarinya kebiasaan baru.
Ide sederhana. Konsekuensi besar. Tiba-tiba AI berhenti menjadi monolit terpusat ini dan mulai terlihat lebih modular. Seperti sesuatu yang benar-benar dapat Anda bentuk tanpa akses ke laboratorium penelitian atau farm GPU sebesar negara kecil.
ModelFactory duduk di atas itu.
Ini adalah bagian yang paling sering diremehkan orang. Antarmuka itu penting. Sangat penting. Mungkin lebih dari arsitektur dalam jangka panjang. ModelFactory pada dasarnya adalah upaya untuk mengubah semua kompleksitas ini menjadi sesuatu yang bisa dipegang oleh pembangun biasa tanpa merasa seperti mereka sedang debugging persamaan fisika.
Jika itu berhasil, itu bukan hanya alat. Itu menjadi jalan masuk.
Dan kemudian lapisan token muncul—OPEN dan gOPEN.
Saya akan jujur, ini adalah tempat kebanyakan orang either kehilangan minat atau terlalu terlibat. Tapi ide ini bukan hanya 'insentif token = baik.' Ini lebih spesifik: menyelaraskan penggunaan, hosting model, inferensi, dan kontribusi ke dalam loop umpan balik di mana nilai mengalir kembali ke orang dan sistem yang menciptakannya.
Setidaknya dalam teori.
Mekanisme aktual yang mereka tuju adalah imbalan berbasis atribusi. Jika data atau kontribusi Anda secara signifikan meningkatkan output, Anda akan diberi kompensasi sesuai dengan pengaruh Anda.
Terdengar bersih di atas kertas. Di dunia nyata? Jauh lebih sulit. Tapi sekali lagi—ruang ini tidak menunggu sistem yang sempurna. Ini membangun sistem yang 'cukup baik' untuk mengubah perilaku.
Dan itulah bagian yang diremehkan orang.
Anda tidak perlu atribusi yang sempurna. Anda perlu atribusi yang cukup baik untuk mengubah pilihan kontribusi orang.
Itu sendiri mengubah partisipasi.
Jika Anda melihat dari jauh, pola menariknya bukanlah komponen tunggal. Ini adalah loop. Data yang lebih baik meningkatkan model. Model yang lebih baik menarik penggunaan. Penggunaan menghasilkan sinyal. Sinyal kembali memberi umpan ke dalam imbalan. Imbalan membawa data yang lebih baik.
Sebuah flywheel. Bukan yang slogan-y juga—sebuah loop struktural nyata di mana insentif terakumulasi.
Tentu saja, flywheels terdengar hebat sampai Anda menyadari mereka juga bisa membusuk jika lapisan sinyal menjadi berisik atau dimanipulasi. Dan itu akan dimanipulasi. Setiap sistem seperti ini melakukannya. Itu hanya kenyataan.
Namun, bahkan loop yang tidak sempurna bisa mengungguli sistem statis dengan jauh.
Apa yang tertinggal dalam pikiran saya bukanlah tumpukan teknis. Ini adalah arah pemikiran.
Kita perlahan-lahan bergerak dari 'AI sebagai produk' ke 'AI sebagai ekonomi input.' Bukan satu otak. Sebuah kekacauan distribusi kontributor, model, dataset, agen—semua saling memberi makan, semua memerlukan koordinasi.
Dan koordinasi, bukan kecerdasan, mulai terasa seperti bottleneck yang sebenarnya.
Hal lucu adalah, itu tidak jelas beberapa tahun yang lalu. Saat itu, obsesi murni pada kemampuan. Bisakah itu menulis? Bisakah itu coding? Bisakah itu berpikir?
Sekarang pertanyaannya secara halus bergeser.
Siapa yang mendapatkan kredit untuk apa yang dihasilkan?
Dan setelah Anda mulai menanyakan itu dengan serius, sistem seperti OpenLedger berhenti terlihat seperti eksperimen infrastruktur dan mulai terlihat seperti upaya awal untuk menulis ulang bagaimana nilai bergerak melalui AI itu sendiri.
