I once tried to verify a simple transaction status across a few crypto tools, and I remember how different each one looked.
The transaction was the same. It did go through. But one dashboard showed it as confirmed, another still had it pending, and another updated it much later than expected. Nothing was broken, yet it still felt unclear what was actually happening in real time.
That small inconsistency stayed with me.
Not because it was a major issue, but because it showed how easily trust can weaken even when systems are technically working.
After seeing this happen more than once, I started paying closer attention to how information moves across infrastructure instead 0f only focusing on how fast it moves.
In crypto, a lot of focus goes into performance. Faster finality, higher throughput, better scaling. Those improvements matter. But what I have noticed is that speed does not fully solve the problem of clarity.
As systems grow, more components start handling the same data. Different services process it in parallel, interpret it slightly differently, and then present it in their own way. Over time, it becomes harder to trace what actually happened from start to finish.
From a system perspective, it feels similar to a logistics network that is efficient at moving goods but not always consistent in tracking them.
think about a delivery system with multiple sorting centers. Each one is fast and organized on its own. Packages move quickly from one point to another. But if tracking updates are not aligned across every step, you can end up with different systems showing different locations for the same package. The movement is fine, but the visibility is not.
That is usually where trust starts to feel fragile.
what interests me more is how this connects to AI systems that are starting to interact with blockchain infrastructure and decentralized workflows. Because now it is not only about tracking transactions. It is also about understanding how AI outputs are created, verified, and shared across different participants.
A model can generate an answer quickly. That part is not the issue. The harder question is whether we can trace how that answer was produced, what data influenced it, and how reliable that process was under different conditions.
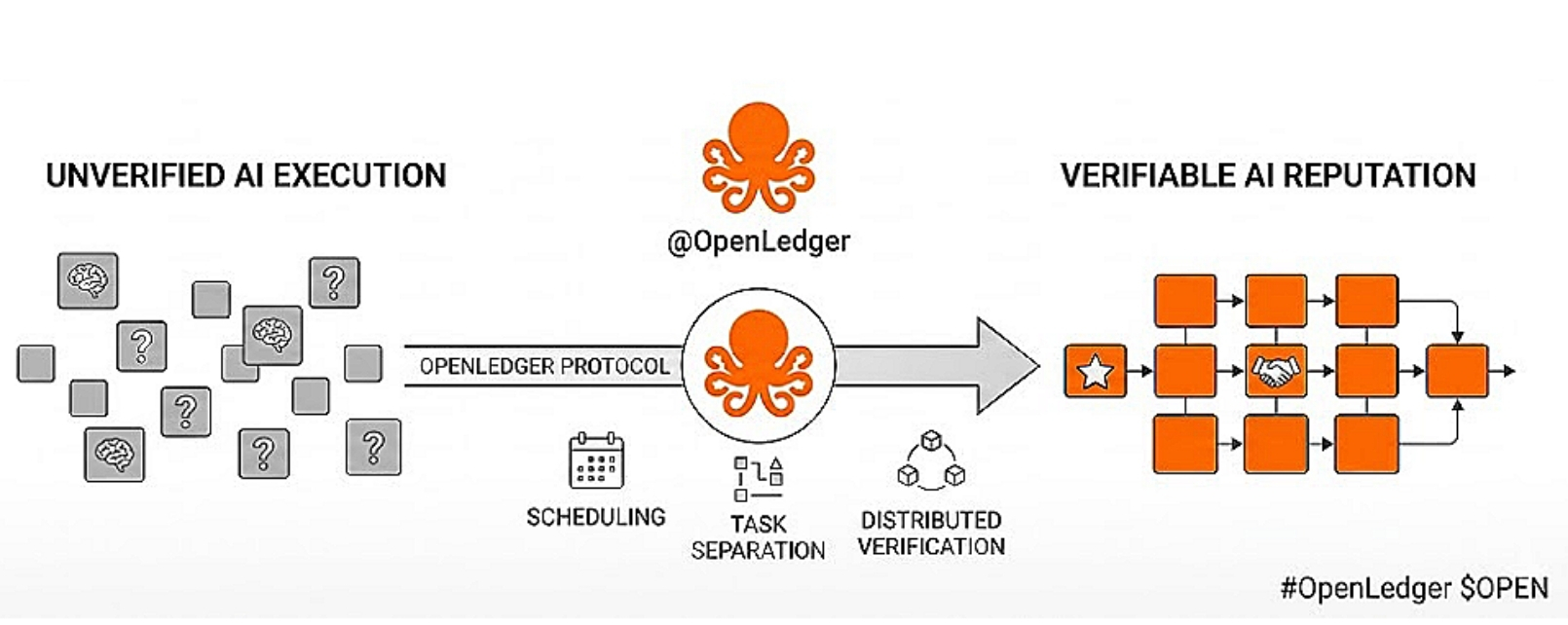
When I look at how @OpenLedger approaches this, what stood out to me is the idea that reputation is not treated as something external or optional. It is built into the system itself.
Instead of only measuring outcomes after the fact, the structure seems to focus on how those outcomes are produced in the first place, and how that process can be made more transparent across the network.
From a system perspective, there are a few things I usually pay attention to when evaluating whether something like this can work in practice.
Scheduling is one. It determines how tasks enter the system and how the network behaves when demand increases. If scheduling is not consistent, everything else becomes harder to reason about under load.
Task separation is another. When execution and verification are clearly split, it becomes easier to understand responsibility within the system. Without that separation, debugging and trust both become more difficult.
Verification flow matters as well. If verification only happens at the end, it can create delays and bottlenecks. But if it is distributed throughout the process, it becomes part 0f how the system maintains trust in real time.
Congestion control and backpressure are often overlooked, but in practice they decide how stable a system really is. When load increases suddenly, the system needs a way to slow things down in a controlled manner instead of collapsing under pressure.
Worker scaling and workload distribution also play a big role. Adding capacity alone is not enough. The system has to distribute work in a way that stays predictable even when more participants join or when demand shifts unexpectedly.
Then there is the balance between ordering and parallel execution. Some tasks need strict sequencing. Others can run in parallel. A well designed system knows when to apply each without losing consistency in the final result.
What I have noticed in more resilient systems is that these parts are not isolated. They depend on each other. If one area is weak, the rest eventually feels it.
This is why the idea of AI reputation as part of infrastructure feels important. Not because it adds something entirely new, but because it ties together these moving parts into something that can be tracked and understood over time.
in the end, a system is not really judged when everything is running smoothly. It is judged when demand spikes, when inputs become messy, and when different parts of the network start pushing against each other.
Good infrastructure does not try to look impressive in those moments. It stays consistent enough that people can still understand what is going on.
That is usually what builds trust over time.