Saya tidak mencari sesuatu yang spesifik. Melihat $OPEN disebutkan di feed, saya klik dan mulai membaca tentang sistem Proof of Attribution — dan kemudian saya hanya… tinggal lebih lama dari yang saya harapkan.
Ini dia yang bikin saya tertarik.
Semua orang menganggap @OpenLedger sebagai cerita kepemilikan data. Unggah data Anda, miliki kontribusi Anda, dapatkan penghasilan dari AI. Itu adalah tawaran. Itu adalah narasi yang didukung seluruh komunitas #OpenLedger. Dan di permukaan, itu masuk akal — akhirnya, sebuah sistem di mana orang-orang yang benar-benar memberi makan mesin mendapatkan bagian.
Tapi semakin banyak saya membaca tentang bagaimana Proof of Attribution sebenarnya bekerja secara mekanis, semakin saya menyadari bahwa kerangka kepemilikan hanya separuh dari cerita. Bagian yang sering diabaikan orang adalah kapan imbalan sebenarnya terpicu.
Kamu tidak dapat penghasilan saat upload. Kamu dapat penghasilan saat inferensi.
Pembayaran hanya terjadi ketika model di-query — saat seseorang menjalankannya, menggunakannya, atau menanyakannya. Data kamu yang ada di Datanet, terverifikasi, teratribusi, tercatat di on-chain? Masih dormant secara ekonomi sampai model dari developer benar-benar dipanggil. Distribusi $OPEN mengalir dari biaya inferensi, dibagi di antara developer model, stakers, dan kontributor data pada saat penggunaan.
Saya pikir ini adalah detail teknis kecil pada awalnya. Tapi sebenarnya… itu mengubah seluruh gambaran.
Karena itu berarti nilai ekonomi dari kontribusimu tidak ditentukan oleh apa yang kamu masukkan. Itu ditentukan oleh seberapa sering model yang dibangun di atas kontribusimu digunakan. Kamu tidak memonetisasi data kamu. Kamu mengambil bagian pasif dalam kurva adopsi model orang lain. Itu adalah hal yang sangat berbeda.
Dan saya tidak yakin kebanyakan orang yang meng-upload ke Datanets sekarang memahami perbedaan itu.
Kontributor yang paling diuntungkan bukanlah yang memiliki data berkualitas tertinggi. Itu adalah yang datanya kebetulan mengalir ke dalam model yang dibangun developer dengan baik dan dipromosikan cukup agresif untuk menghasilkan volume inferensi yang konsisten. Itu adalah taruhan yang sangat berbeda daripada "data saya berharga, saya harus dihargai."
Tapi inilah bagian yang masih mengganggu saya.
Jika volume inferensi adalah apa yang benar-benar membuka ekonomi — dan saat ini volume inferensi tipis menurut ukuran yang jujur, jaringan baru saja meluncurkan mainnet pada November 2025 — maka cerita monetisasi yang adil sebagian besar bersifat prospektif. Ini adalah desain yang bekerja dengan indah ketika ada permintaan. Apa yang tidak bisa dilakukan adalah memproduksi permintaan itu. Mesin atribusi adalah sound. Logika pembayaran elegan. Tapi jika permintaan inferensi tidak mengalir dalam skala besar, kontributor data yang duduk di Datanets hanya… menunggu.
Saya terus kembali ke itu. Mekanismenya nyata. Layer keadilan benar-benar baru. Tapi hal yang membuatnya bermakna secara ekonomi — volume query, penggunaan model yang konsisten, developer yang memilih untuk membangun di sini daripada opsi infrastruktur AI lainnya — bagian itu tidak dijamin oleh desainnya. Itu harus diperoleh di pasar.
Yang mungkin jelas jika dilihat kembali. Tapi cara penyampaian, kamu akan berpikir meng-upload data yang baik sudah cukup. Itu tidak. Itu adalah kondisi awal, bukan yang cukup.
Bagaimanapun. Masih mengamati bagaimana sisi inferensi berkembang selama kuartal berikutnya. Itu adalah angka sebenarnya untuk dilacak — bukan harga, bukan ukuran komunitas. Berapa banyak model yang dipanggil, dan seberapa sering.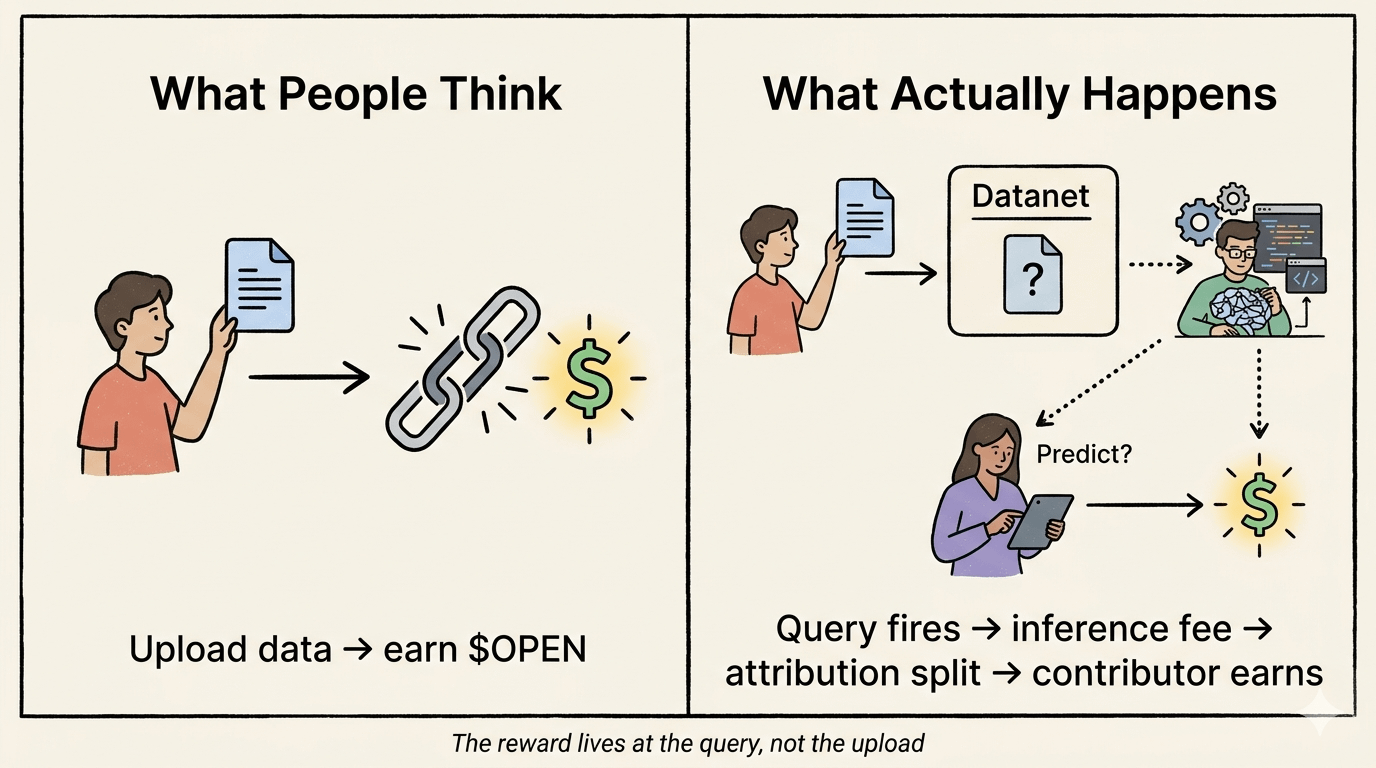
Semua yang lain hanyalah infrastruktur yang menunggu alasan untuk berjalan.