#OpenLedger sudah ada di daftar itu cukup lama. Secara khusus, saya ingin memahami bagaimana model ekonomi ini sebenarnya memperlakukan kontributor—orang-orang yang memberi makan sistem AI dengan data, koreksi, dan anotasi. Seluruhnya dibingkai dalam "atribusi yang adil," dan saya terus mengangguk sampai sesuatu menghentikan saya di tengah bacaan.
Model ini memberi imbalan kepada kontributor berdasarkan seberapa banyak data mereka sebenarnya digunakan di hilir. Atribusi berbasis penggunaan, pada dasarnya. Jika kontribusi Anda lebih banyak dirujuk, lebih banyak divalidasi, lebih banyak dibangun — Anda akan mendapatkan lebih banyak. Di atas kertas, itu terdengar sudah benar. Lebih banyak dampak, lebih banyak imbalan. Bersih.
Tetapi saya duduk dengan itu selama beberapa menit, dan sesuatu mulai terasa tidak beres.
Ini yang saya pikirkan pada awalnya: tetapi untuk input pelatihan AI. Terukur, on-chain, tahan terhadap manipulasi.
Kemudian saya mulai berpikir tentang apa arti "digunakan lebih banyak" sebenarnya dalam konteks pelatihan AI.
Ini tidak berarti lebih baik. Ini berarti lebih kompatibel dengan apa yang sudah akan dilakukan oleh model.
Jika sebuah model memiliki arsitektur tertentu, bias pelatihan tertentu, arah tertentu yang sudah dilaluinya — maka data yang paling banyak digunakan belum tentu adalah data yang paling berharga. Itu adalah data yang paling cocok. Kontribusi yang mengonfirmasi apa yang sudah dibangun akan terangkat. Kontribusi yang menantang, memperbaiki, mengarahkan ulang — itu mungkin akan digunakan lebih sedikit, setidaknya di awal, meskipun itu lebih penting dalam jangka panjang.
Dan model ekonomi memberi imbalan pada yang pertama daripada yang kedua.
Saya tidak yakin kebanyakan orang yang berkontribusi pada sistem ini telah memikirkan tentang itu. Anda secara alami akan menganggap bahwa jika Anda menyumbangkan data berkualitas tinggi, imbalan akan mengikuti. Tetapi kualitas dan kompatibilitas bukanlah hal yang sama. Koreksi edge-case yang sangat akurat mungkin tidak digunakan selama berbulan-bulan karena tidak ada tugas model saat ini yang memerlukannya. Sementara itu, kontribusi yang mengisi pola umum — bahkan yang sedikit redundan — terus dirujuk.
Kontributor yang memahami celah dibayar lebih sedikit daripada kontributor yang memahami antrean.
Itu adalah distorsi yang halus tetapi nyata. Dan itu memiliki efek lanjutan pada jenis data yang akan disumbangkan. Jika para kontributor mengoptimalkan untuk pengembalian berbasis penggunaan — dan mereka akan, itulah cara insentif bekerja — mereka akan mulai menyumbangkan yang diperkirakan daripada yang diperlukan. Model ekonomi akhirnya membentuk pasokan data sebelum data itu bahkan diciptakan.
Ini bagian yang mengganggu saya: Saya sebenarnya tidak tahu apakah OpenLedger memiliki mekanisme untuk memperbaiki ini. Mungkin ada penimbangan validator, penyesuaian terbaru, sesuatu yang memperhitungkan nilai yang ditunda. Saya cepat-cepat membaca dokumen dan tidak menemukan jawaban yang jelas, yang berarti saya mungkin melewatkannya atau itu benar-benar tidak terdefinisi dengan baik.
Dan saya tidak sepenuhnya yakin bahwa model atribusi apa pun — on-chain atau lainnya — dapat menyelesaikan ini dengan bersih. Mengukur penggunaan lanjutan itu bisa dilakukan. Mengukur dampak counterfactual — apa yang dicegah, diarahkan ulang, diperbaiki oleh sebuah kontribusi di seluruh generasi model — adalah kelas masalah yang berbeda. Satu adalah metrik output. Yang lain mengharuskan Anda untuk memodelkan dunia counterfactual di mana kontribusi itu tidak ada.
Itu bukan kritik terhadap OpenLedger secara spesifik. Itu hanya masalah yang sulit. Tetapi itu berarti kerangka keadilan mungkin sedikit lebih maju daripada eksekusi.
Siapa yang paling peduli dengan ini? Mungkin para kontributor yang benar-benar melakukan pekerjaan sulit, dengan gesekan tinggi. Ahli domain niche. Orang-orang yang mengidentifikasi kesalahan dalam segmen data yang kurang terwakili. Jika kontribusi mereka tidak langsung cocok dengan beban tugas saat ini dari model, mereka secara ekonomi tidak terlihat di bawah sistem berbasis penggunaan murni.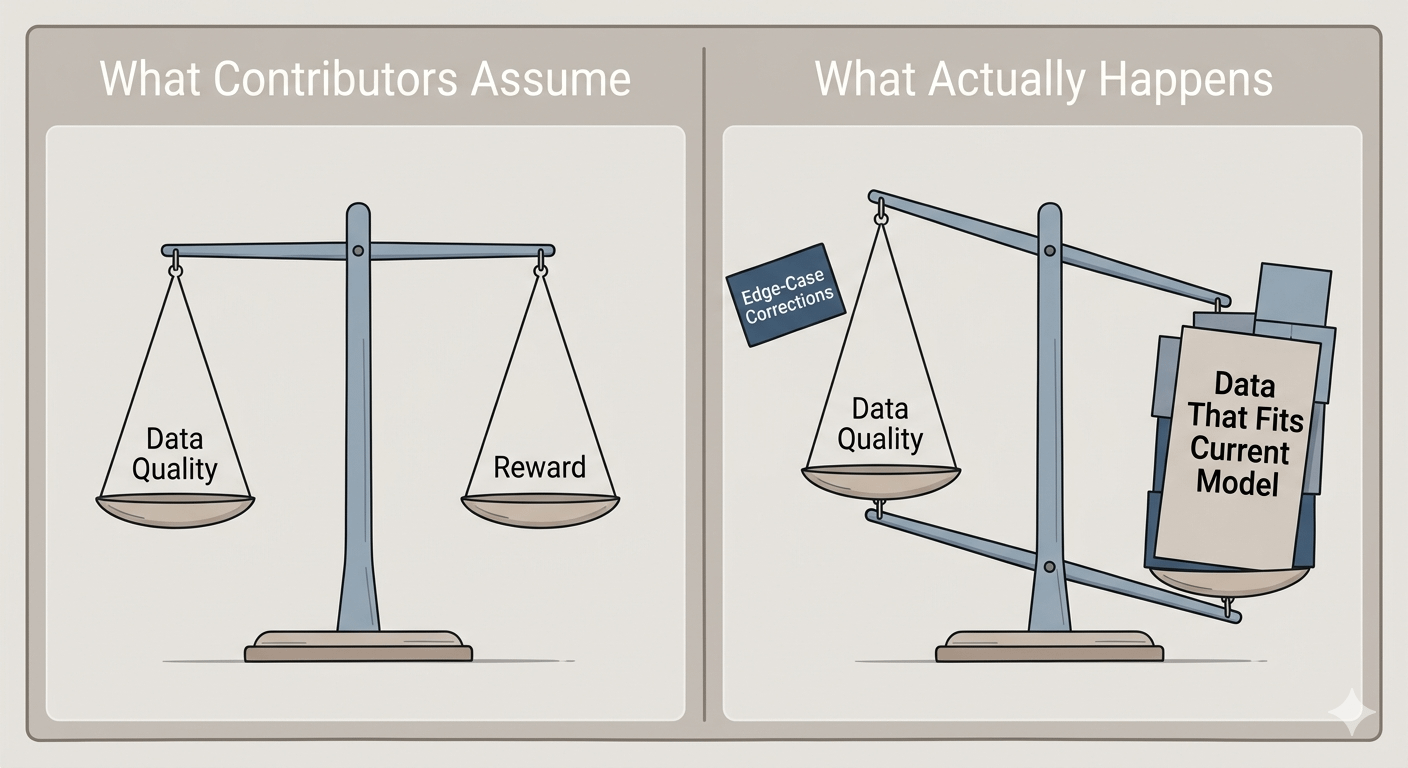
Untuk peserta ritel — orang-orang yang menyumbangkan input yang lebih sederhana dan lebih terstruktur — mungkin tidak terlalu penting. Mereka akan menemukan pola yang membayar dan berkontribusi pada itu. Itu baik-baik saja, tetapi itu juga versi yang lebih lembut dari apa yang diklaim oleh jaringan sedang dibangun.