
Berita terkini tentang pendanaan dan data istilah AI
2026-06-15
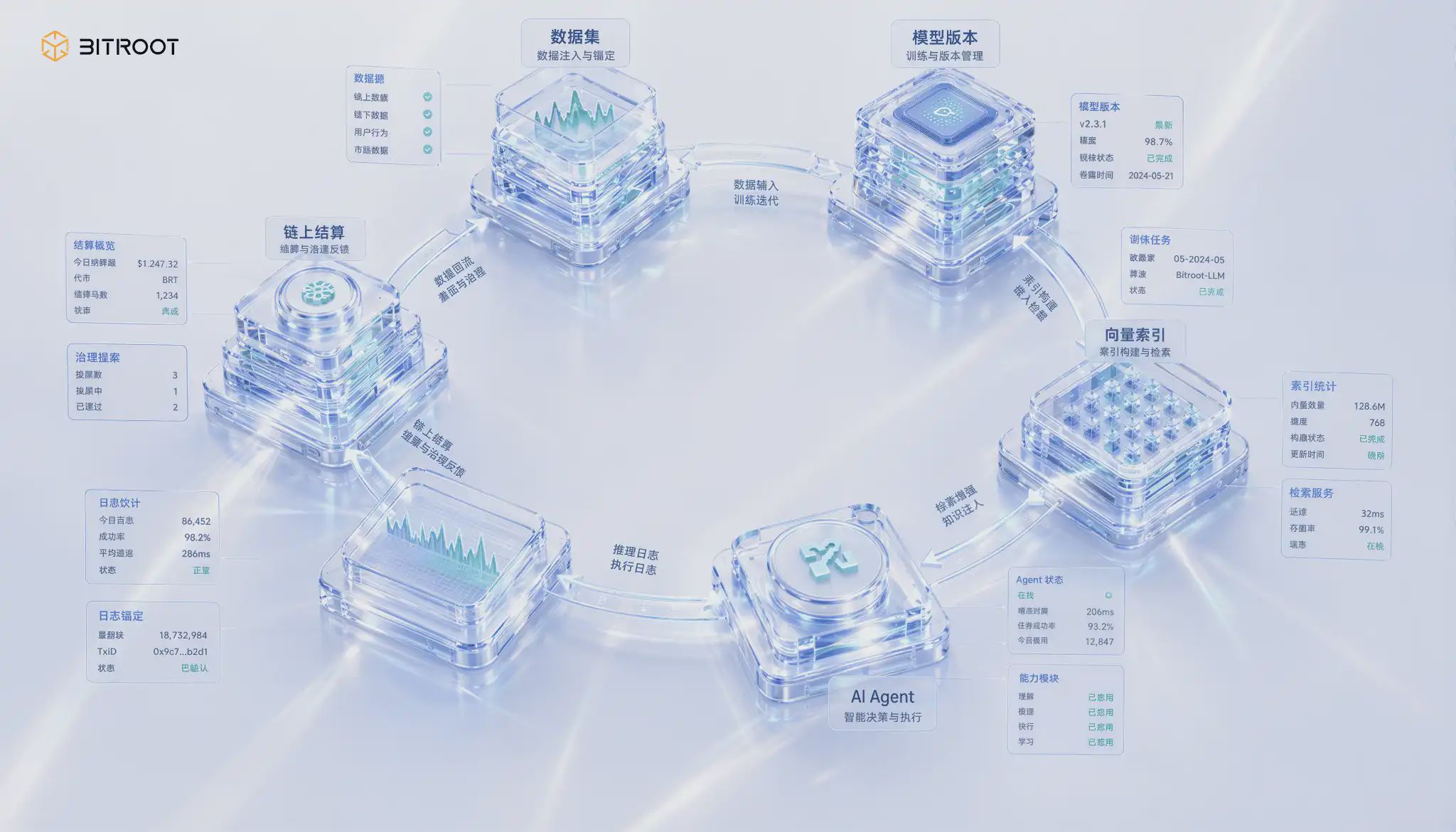
Bitroot, di satu sisi, menyediakan lingkungan eksekusi on-chain berkinerja tinggi melalui paralelisasi EVM dan Pipeline BFT. Di sisi lain, melalui pelatihan terdistribusi, jaringan inferensi, eksekusi terpercaya, dan manajemen aset AI, menghubungkan data, model, daya komputasi, dan aplikasi Agen ke dalam jaringan yang dapat diselesaikan. Dalam jaringan ini, penyimpanan bukanlah modul yang terisolasi, melainkan infrastruktur yang menentukan apakah data dapat diakui, model dapat direproduksi, daya komputasi dapat diselesaikan, dan kontributor dapat terus mendapatkan keuntungan.
Sumber: Bitroot
Penyimpanan bukanlah pusat biaya, melainkan sistem distribusi nilai dari Bitroot AI Stack
Banyak tim baru menyadari setelah enam bulan peluncuran bahwa lapisan penyimpanan seharusnya dipilih lebih hati-hati sejak awal. Data tidak hilang, layanan tidak terputus, tetapi masalah muncul dengan cara lain: pengambilan data pelatihan yang diarsipkan semakin lambat, latensi kueri vektor panas bergetar dari level milidetik hingga detik, dan ketika ingin mereview insiden online, tidak ada yang bisa menjelaskan versi data pelatihan mana yang digunakan oleh model tersebut. Pada tahap ini, yang perlu diselesaikan bukan lagi kapasitas, tetapi tiga masalah yang lebih sulit: siapa yang dapat membuktikan bahwa data selalu tersedia, siapa yang bertanggung jawab atas versi, siapa yang membayar untuk biaya jangka panjang.
Memahami penyimpanan sebagai memindahkan file dari cloud terpusat ke jaringan di bawah, masih dapat bertahan di era metadata NFT. Begitu bisnis berkembang ke korpus pelatihan AI, bobot model, dan indeks vektor, cara berpikir ini akan cepat gagal.
Kebanyakan tim hingga kini masih menganggap penyimpanan sebagai biaya logistik yang semakin dapat dihemat, ini justru adalah area yang paling diremehkan dan paling mudah salah pilih: di blockchain AI, ia sebenarnya adalah lapisan distribusi nilai yang menentukan siapa yang menguasai data, dan siapa yang menerima pendapatan. Artikel ini hanya menjawab satu pertanyaan: dalam skenario di mana AI dan blockchain menyatu, bagaimana membangun solusi penyimpanan terdistribusi yang dapat dibuktikan, dapat dikelola, dan berkelanjutan. Teks selanjutnya akan memecah batas kemampuan tiga paradigma utama, kemudian menjelaskan kesulitan khusus data AI, akhirnya sampai pada arsitektur lima lapisan yang dapat diimplementasikan dan ambang batas peluncuran yang terpisah. Dasar penilaian akan berfokus pada dokumen resmi protokol, berusaha berdasarkan pada materi yang dapat diverifikasi.
Dengan Bitroot sebagai contoh, lapisan penyimpanan lebih tepatnya merupakan basis distribusi nilai AI Stack. Di satu sisi, Bitroot menyediakan lingkungan eksekusi on-chain berkinerja tinggi melalui EVM paralel dan Pipeline BFT, di sisi lain, menghubungkan data, model, daya komputasi, dan aplikasi Agent menjadi jaringan yang dapat diselesaikan melalui pelatihan terdistribusi, jaringan inferensi, eksekusi terpercaya, dan manajemen aset AI. Dalam jaringan ini, penyimpanan bukanlah modul terpisah, tetapi infrastruktur yang menentukan apakah data dapat diakui, jika model dapat diulang, jika daya komputasi dapat diselesaikan, dan jika kontributor dapat terus mendapatkan keuntungan.
Sepenuhnya on-chain dan sepenuhnya terpusat, dalam skenario AI sudah tidak mungkin lagi.
Dalam beberapa tahun terakhir, masalah penyimpanan sering disederhanakan menjadi dua pilihan: baik sepenuhnya on-chain, atau sepenuhnya terpusat. Kedua jalan ini tidak berkelanjutan dalam konteks AI.
Tekanan untuk sepenuhnya on-chain sangat konkret. Data pelatihan, bobot model, log inferensi, dan indeks vektor umumnya memiliki volume tinggi dengan pembaruan frekuensi tinggi, bahkan jika diiris dan di-chain, akan segera menghadapi batas throughput dan kurva biaya. Sepenuhnya terpusat berjalan cepat, tetapi kepercayaan yang diperlukan untuk verifikasi, keterlacakan, kedaulatan data, dan kolaborasi antar pihak sangat rapuh, sekali melibatkan pembagian multi-pihak dan pengakuan, tidak akan bertahan.
Perubahan yang lebih krusial adalah, AI mengubah penyimpanan dari item biaya menjadi faktor produksi. Versi data yang dikelola oleh siapa, menentukan siapa yang memiliki hak dalam iterasi model; kemampuan untuk membuktikan data dapat digunakan, secara langsung mempengaruhi penjadwalan daya komputasi dan prioritas penyelesaian; dan kemampuan untuk mengubah data menjadi aset, berkaitan dengan apakah tim dapat membangun insentif jangka panjang dalam ekosistem. Lapisan penyimpanan pada tahap ini tidak lagi menjadi sistem logistik, melainkan sistem distribusi nilai.
Karena itu, arsitektur penyimpanan yang memenuhi syarat harus dapat menjawab empat pertanyaan: apakah data benar-benar ada dan dapat diambil secara berkelanjutan, apakah hubungan versi antara data dan model dapat dilacak, apakah izin dan pendapatan dapat dikelola, dan apakah sistem dapat menyeimbangkan biaya dan kinerja dalam jangka panjang.

Pendekatan Bitroot: mengubah data AI dari "dapat disimpan" menjadi "dapat diselesaikan".
Inilah posisi yang perlu dilengkapi oleh Bitroot. Sebagai blockchain publik EVM paralel yang ditujukan untuk skenario AI, narasi penyimpanan Bitroot tidak seharusnya berhenti pada "di mana data disimpan", tetapi harus menjawab "bagaimana data dibuktikan, bagaimana data dipanggil, bagaimana hasil dibagi." Korpus pelatihan, bobot model, indeks vektor, dan log inferensi dapat tetap di lapisan penyimpanan terdistribusi yang lebih sesuai untuk objek besar, tetapi komitmen hash mereka, hubungan versi, kebijakan izin, catatan panggilan, dan peristiwa pendapatan perlu membentuk bukti on-chain yang bersatu di Bitroot.
Dari sudut pandang ini, throughput tinggi dan latensi rendah Bitroot bukan hanya untuk melayani transaksi DeFi, tetapi juga untuk melayani kejadian tata kelola yang lebih halus dan frekuensi tinggi dalam AI Stack: pembaruan dataset perlu diikat, versi model perlu didaftarkan, panggilan AI Agent perlu diselesaikan, sengketa hasil pencarian perlu di arbitrase, dan ketersediaan node penyimpanan perlu terus ditantang dan dihargai. Hanya jika rantai dasar dapat menangani kejadian ini, aset data AI tidak akan terjebak dalam database terpusat, dan tidak akan menjadi kotak hitam off-chain yang tidak dapat dipertanggungjawabkan.

Tiga paradigma utama, tidak ada satu pun yang dapat menembus semua skenario.
Kompetisi penyimpanan terdistribusi bukanlah siapa yang paling canggih, tetapi siapa yang paling cocok dalam struktur data Anda.
Jaringan pengalamatan konten menyelesaikan apakah ini adalah data yang sama, bukan siapa yang menjamin itu online. Menurut dokumentasi resmi IPFS, CID adalah identifikasi berbasis hash konten, tidak bergantung pada pengalamatan lokasi: konten yang sama dihasilkan CID yang sama di bawah pengaturan enkode yang sama, selama konten mengalami perubahan satu byte, CID akan berubah. Karakteristik ini membuatnya secara alami cocok untuk melakukan pemeriksaan integritas, penghapusan, dan referensi antar sistem, adalah kemampuan dasar untuk mengakui data. Namun, pengalamatan konten tidak sama dengan ketersediaan yang berkelanjutan secara ekonomi, CID menjawab masalah identitas, tetapi tidak menjawab siapa yang menjamin bahwa itu selalu online. Banyak tim yang meluncurkan produk setelahnya mengalami kesulitan pertama di sini: secara teknis mendapatkan CID, tetapi secara bisnis tidak mendapatkan komitmen ketersediaan.
Jaringan pasar penyimpanan, membeli ketersediaan dalam dimensi waktu melalui mekanisme ekonomi. Menurut dokumentasi Filecoin, jaringan membangun komitmen penyimpanan dengan bukti replikasi dan bukti ruang-waktu. PoRep pada pengemasan awal membuktikan bahwa salinan unik ini memang disimpan, PoSt dalam siklus berikutnya membuktikan bahwa salinan itu masih ada. Siklus pembuktian WindowPoSt biasanya diorganisir dalam 24 jam, kemudian dibagi menjadi beberapa jendela pembuktian 30 menit, jika penyimpanan tidak mengajukan bukti yang valid dalam jendela, maka akan memicu penalti kolateral dan penurunan kemampuan penyimpanan. Dalam sistem ini, ketersediaan adalah item evaluasi berkelanjutan, bukan komitmen sekali saat penandatanganan. Model kontrak yang dapat diaudit ini cocok untuk pengarsipan jangka menengah hingga panjang, cadangan, dan pasar data, tetapi ini lebih mirip penyimpanan jangka panjang yang dapat dibuktikan, bukan layanan online latensi rendah yang alami; jika Anda menekan kueri online frekuensi tinggi secara langsung, pengalaman akan hancur karena latensi ekor.
Jaringan penyimpanan permanen mengikuti jalur lain, menggunakan pembayaran sekali untuk pertukaran sejarah yang tidak dapat diubah. Menurut protokol Arweave dan informasi dari buku kuning, sebagian dari biaya unggahan akan masuk ke kolam sumbangan penyimpanan, digunakan untuk menutupi insentif penyimpanan jangka panjang, dengan keberlanjutan jangka panjang diutamakan dalam model penagihan, bukan bergantung pada kebiasaan perpanjangan di masa mendatang. Ini cocok untuk pengarsipan sejarah, bukti kunci, dan bahan hak cipta yang merupakan catatan yang tidak dapat diubah. Kelemahan juga jelas: permanen tidak otomatis berarti latensi rendah dan permintaan tinggi, dalam praktiknya masih perlu menambahkan cache, gerbang, atau lapisan indeks near-line untuk memenuhi pengalaman real-time di sisi pengguna.
Selain ketiga paradigma dasar ini, secara teknik ada dua kombinasi umum lainnya yang perlu dipertimbangkan. Satu adalah lapisan ketersediaan data ditambah penyimpanan objek campuran, penerbitan data dan bukti ketersediaan menjadi lebih terstandarisasi, biayanya adalah kompleksitas kolaborasi antar lapisan dan biaya tata kelola tinggi. Yang lainnya adalah multi-cloud ditambah kolaborasi tepi, dengan latensi rendah dan ketahanan bencana yang lebih baik, tetapi tata kelola biaya dan manajemen konsistensi lebih sulit untuk ditangani.
Apapun pilihannya, satu protokol yang mengkonsumsi semua skenario secara teknis tidak mungkin. Metode yang efektif adalah menggabungkan berdasarkan jenis data: memisahkan ketahanan, latensi pengambilan, dan kepatuhan, masing-masing mencocokkan lapisan kemampuan, lalu menyatukan dengan pengikatan dan lapisan tata kelola on-chain.

Ruang pilihan Bitroot juga harus dibangun di atas logika kombinasi ini: bukan menggantikan IPFS, Filecoin, Arweave, atau penyimpanan objek satu sama lain, tetapi menempatkan mereka ke dalam lapisan tanggung jawab yang berbeda. Pengalamatan konten digunakan untuk identitas dan integritas data, bukti penyimpanan untuk ketersediaan jangka panjang, lapisan permanen untuk sejarah dan bukti kunci, lapisan pengambilan panas untuk pengalaman aplikasi AI, sedangkan lapisan on-chain Bitroot secara bersatu menampung pengikatan versi, kebijakan izin, penyelesaian panggilan, dan penyelesaian sengketa. Dengan kata lain, Bitroot tidak perlu menjadi gudang fisik untuk semua data, tetapi harus menjadi buku besar yang dapat dipercaya untuk aliran nilai data AI.
Kesulitan penyimpanan AI bukan terletak pada menyimpan file, tetapi pada mengelola jalur produksi.
Dalam skenario AI, objek penyimpanan setidaknya dibagi menjadi empat kategori: data pelatihan, bobot model, indeks vektor, dan log inferensi. Empat jenis objek ini memiliki siklus hidup, pola akses, dan kepadatan nilai yang sangat berbeda, menggunakan satu set strategi untuk mengelola, akan lebih mudah dalam jangka pendek, tetapi pasti akan kehilangan kontrol tata kelola dalam jangka panjang.
Masalah data pelatihan bukan terletak pada kapasitas, tetapi pada pergeseran versi. Banyak tim menganggap masalah data pelatihan setara dengan biaya penyimpanan tingkat TB, yang jauh lebih rumit adalah pergeseran: selama aturan pembersihan, ambang penyaringan sampel, atau kriteria pelabelan berubah, perilaku model juga akan berubah, dan tanpa pengikatan versi data dan model, evaluasi offline sulit untuk diverifikasi kembali. Berdasarkan praktik pelacakan model dan data dari MLflow, pengikatan pelaksanaan pelatihan dengan versi data adalah prasyarat untuk mereproduksi eksperimen. Prinsip ini tetap berlaku di on-chain: data mentah tidak perlu sepenuhnya di-chain, tetapi komitmen versi, ringkasan kunci, dan sidik jari sumber harus diikat ke on-chain. Di tingkat teknik setidaknya harus mengikat tiga identitas, versi data, pelaksanaan pelatihan, versi model, kehilangan satu, jejak masalah online akan berubah dari mencari bukti menjadi menebak penyebab.
Masalah bobot model biasanya bukan apakah dapat diunduh, tetapi siapa yang mengelola batas panggilan. Ketika sebuah model memasuki produksi, biasanya melalui beberapa status: abu-abu, utama, rollback, pensiun, tanpa sistem pendaftaran dan otorisasi yang terstandarisasi, pemanggilan online adalah kotak hitam yang tidak dapat diaudit. Pusat pendaftaran model yang matang akan sekaligus mencatat keturunan, alias versi, batas tanda tangan, dan label audit. Untuk sistem on-chain, versi model seharusnya bukan hanya hash file, tetapi juga harus diikat dengan kebijakan izin, pembagian pendapatan, dan batas tanggung jawab.
Kesulitan dalam indeks vektor terletak pada satu hal: konsistensi setelah pemisahan panas-dingin. Pencarian vektor memiliki kontradiksi bawaan, latensi rendah dan biaya rendah saling bertentangan: lapisan panas harus mengandalkan memori atau layanan indeks berkinerja tinggi untuk menjamin respons online, lapisan dingin harus mengandalkan penyimpanan objek untuk menekan biaya jangka panjang. Tanpa metadata yang bersatu dan strategi sinkronisasi, kedua lapisan akan dengan cepat bercabang, akhirnya menghasilkan masalah di mana kueri yang sama mengembalikan hasil semantik yang berbeda di node yang berbeda. Oleh karena itu, sistem vektor harus mendukung dua hal, proses pembentukan indeks dapat dilacak, versi indeks lapisan panas dan data utama lapisan dingin dapat diverifikasi, ini adalah apa yang akan diselesaikan oleh pencarian dapat divalidasi di bagian selanjutnya.
Log inferensi harus memastikan bahwa privasi, audit, dan kepatuhan dapat berjalan bersamaan, ini sangat sulit. Ia berfungsi sebagai bahan audit keamanan, tetapi juga sumber risiko privasi: penyimpanan data dalam bentuk jelas membawa risiko kepatuhan, sementara tidak menyimpan sama sekali menghilangkan kemampuan untuk mereview insiden. Cara yang mungkin adalah menerapkan tiga lapisan, menyimpan data setelah desensitisasi, komitmen hash on-chain, akses harus melalui otorisasi audit, memisahkan implementasi antara ketidakberubahan dan akses yang dapat dicabut.
Dalam AI Stack Bitroot, keempat jenis objek ini dapat berhubungan dengan empat tindakan tata kelola: data pelatihan melakukan pengikatan versi dan pendaftaran sumber, bobot model melakukan pendaftaran aset dan panggilan otorisasi, indeks vektor melakukan pemisahan panas-dingin dan bukti konsistensi, log inferensi melakukan penyimpanan desensitisasi dan komitmen audit. Mereka tidak perlu di-chain dengan cara yang sama, tetapi semua perlu membentuk ID aset yang bersatu, garis keturunan versi, dan peristiwa panggilan di Bitroot. Dengan cara ini, aset data, aset model, dan aplikasi Agent dapat membentuk siklus bisnis yang dapat digunakan kembali.

Dapat divalidasi adalah batas bawah, bukti ketersediaan adalah batas pemisah.
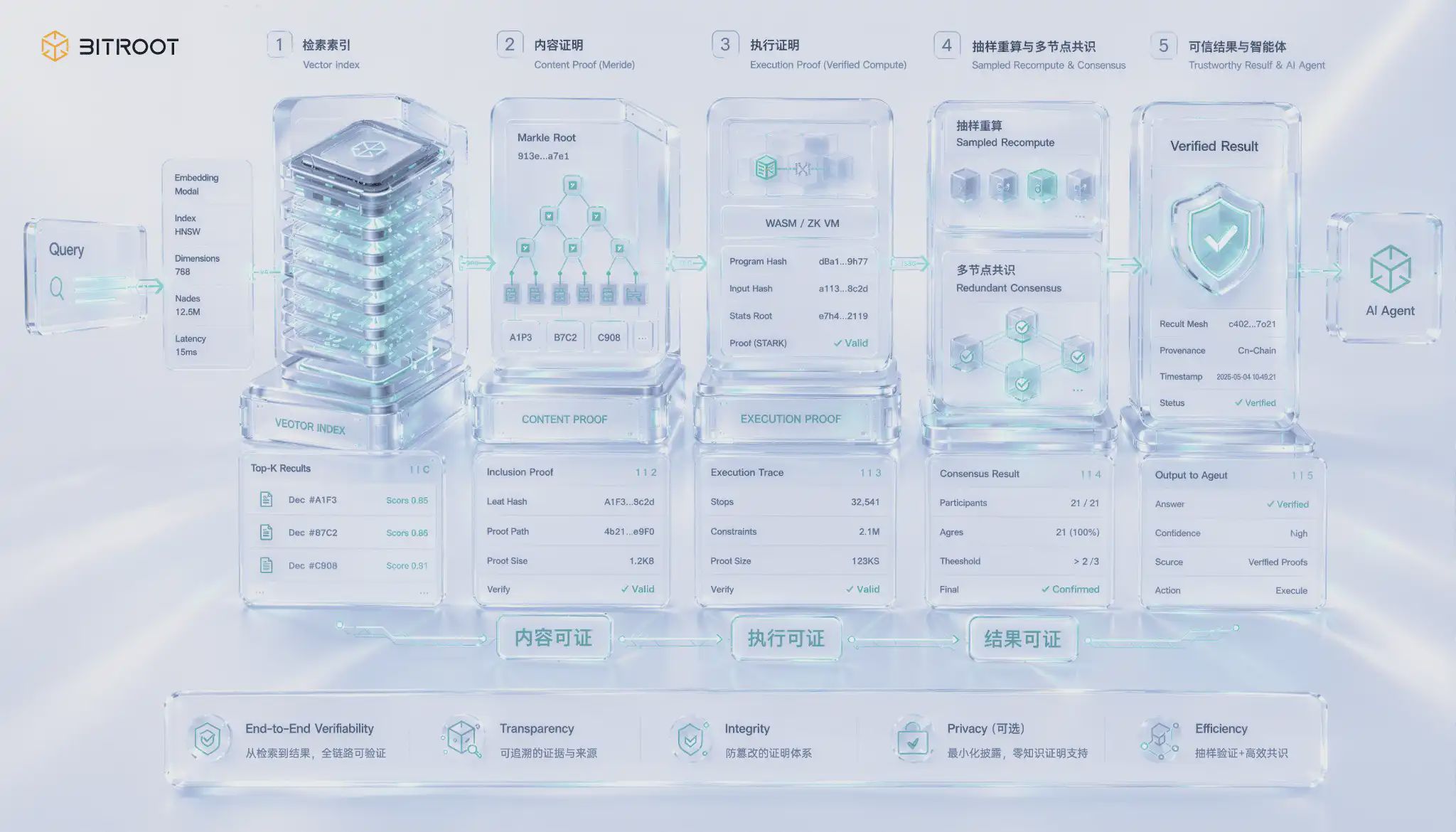
Tanpa bukti ketersediaan dari komitmen penyimpanan, di lingkungan produksi, pada dasarnya sama dengan tidak ada komitmen. Penyimpanan terdistribusi harus memasuki produksi, setidaknya harus melewati tiga tahap: integritas dapat dibuktikan, ketersediaan dapat dibuktikan, perilaku dapat diaudit; begitu memasuki skenario pencarian AI, harus ada satu tahap paling sulit lagi, yaitu pencarian dapat dibuktikan.
Integritas dapat dibuktikan melalui pengalamatan konten dan komitmen Merkle. Pengalamatan konten menjamin stabilitas sidik jari data, komitmen Merkle menjamin dapat diverifikasi secara lokal. Arti tekniknya adalah, Anda dapat memverifikasi subset objek dengan bukti tingkat partisi, tanpa harus membaca seluruhnya setiap kali. Untuk bobot model besar, korpus besar, dan data multimedia, hal ini langsung menentukan biaya verifikasi.
Ketersediaan dapat dibuktikan melalui mekanisme tantangan dan validasi sampling. Praktik Filecoin telah menunjukkan bahwa ketersediaan bukanlah SLA verbal, tetapi tantangan berkala ditambah bukti on-chain, diubah menjadi arsitektur umum adalah tiga set: pemeriksaan pasif, inspeksi aktif, dan hukuman kegagalan; node harus merespons tantangan dalam jendela yang ditentukan, jika tidak, penalti atau penurunan bobot akan dipicu. Pemikiran yang sama berjalan lebih jauh dalam lapisan ketersediaan data. Berdasarkan desain sampling ketersediaan data Celestia, data diperluas dari k×k menjadi matriks 2k×2k, node ringan melalui beberapa putaran sampling acak dan akumulasi probabilitas, tidak perlu mengunduh seluruh data, dapat membangun kepercayaan probabilitas tinggi terhadap ketersediaan. Ini memberikan inspirasi yang dapat dipindahkan untuk skenario AI: menghadapi objek super besar dan akses bersamaan tinggi, tidak semua ketersediaan harus diverifikasi melalui pengunduhan penuh, konfirmasi statistik lebih realistis dalam sistem berskala besar.
Perilaku dapat diaudit melalui pengikatan on-chain dan pencatatan peristiwa. Yang paling sulit dalam mengelola sistem penyimpanan adalah perilaku: siapa yang mengunggah apa, siapa yang mengubah kebijakan, siapa yang memicu migrasi, siapa yang memanggil model sensitif kapan. Jika perilaku ini tidak menyatu menjadi aliran peristiwa yang konsisten, ketika sengketa muncul, tidak ada bukti yang dapat diandalkan.
Pencarian yang dapat dibuktikan adalah yang unik dan paling sulit untuk skenario AI, masalah terletak pada celah yang mudah diabaikan: mengembalikan hasil, tidak berarti mengembalikan hasil yang benar. Node pencarian vektor sepenuhnya dapat menggunakan indeks yang kedaluwarsa, bahkan melewatkan tetangga terdekat yang benar, memberikan Anda top-k yang terlihat masuk akal, sementara Anda tidak dapat membedakan hanya dengan melihat nilai yang dikembalikan. Output pencarian semantik sendiri tidak memiliki keautentikan, kesalahan tidak akan dilaporkan, hanya akan secara diam-diam menurunkan kualitas recall dan kinerja model. Ketika hasil pencarian digunakan untuk penyelesaian, otorisasi, atau keputusan on-chain, celah ini beralih dari masalah kualitas menjadi masalah kepercayaan.
Memecah pencarian yang dapat dibuktikan sebenarnya adalah tiga lapisan yang semakin sulit untuk dijamin. Lapisan pertama adalah bukti konten, membuktikan bahwa vektor yang dikembalikan memang milik versi indeks yang dijanjikan, caranya adalah membangun struktur data otentikasi untuk indeks, menggunakan komitmen Merkle untuk mengikat akar indeks ke on-chain, saat mengembalikan hasil dilampirkan bukti inklusi, memastikan node tidak dapat menciptakan atau mengganti data secara sembarangan. Lapisan kedua adalah bukti eksekusi, membuktikan bahwa kueri ini benar-benar dijalankan di versi yang dijanjikan, bukan di indeks yang dimodifikasi secara pribadi, ini memerlukan memasukkan proses kueri ke dalam kategori perhitungan yang dapat diverifikasi. Lapisan ketiga yang paling sulit adalah bukti hasil, membuktikan bahwa top-k yang dikembalikan memang beberapa yang terdekat berdasarkan metrik yang diberikan, bukan melewatkan tetangga yang lebih dekat, pada dasarnya memberikan bukti keakuratan pencarian tetangga terdekat yang mendekati.
Membuat hasil yang dapat dibuktikan untuk tetangga terdekat yang mendekati dimensi tinggi dalam skala produksi, saat ini masih merupakan topik yang paling maju, meskipun teknik kriptografi seperti bukti nol pengetahuan sedang dikembangkan, namun biaya pembuktian dari perhitungan vektor berdimensi tinggi masih jauh dari dapat digunakan secara online dalam skala besar. Solusi teknik yang pragmatis adalah menggunakan lapisan dasar daripada langkah langsung: pertama mengikat versi indeks dan parameter pembangun ke on-chain, menjamin dapat dilacak; selanjutnya melakukan penghitungan ulang sampling untuk kueri, secara proporsional mengambil kueri online untuk dijalankan ulang pada salinan yang dapat dipercaya dan membandingkan hasilnya, menggunakan tingkat kepercayaan statistik sebagai pengganti bukti per baris; sekaligus membiarkan beberapa node independen mencari redundansi, mencapai konsensus pada hasil yang dikembalikan, meningkatkan biaya kecurangan titik tunggal; hanya ketika perbedaan muncul dalam perbandingan atau konsensus, baru ditingkatkan untuk perhitungan ulang penuh pada kueri sengketa dan keputusan on-chain. Jalur ini bersinergi dengan pemikiran prioritas pengujian ketersediaan dalam bukti: dalam sistem berskala besar, konfirmasi statistik dengan peningkatan sengketa lebih sering lebih praktis daripada pembuktian ketat per baris.
Bagi Bitroot, pencarian yang dapat dibuktikan bukanlah fungsi penyimpanan yang terpisah, tetapi bagian dari eksekusi terpercaya AI Agent. Jika seorang Agent di-chain mengandalkan basis pengetahuan eksternal, bobot model, atau indeks vektor untuk mengambil keputusan, sistem setidaknya harus dapat menjawab tiga hal: versi data yang dibaca, versi model yang dipanggil, dan apakah hasil yang dikembalikan berasal dari versi indeks yang terdaftar. Bitroot dapat mengompresi bukti ini menjadi peristiwa yang dapat diverifikasi di on-chain, sehingga tindakan Agent dapat beralih dari "terlihat cerdas" menjadi "dapat dilacak, dapat diperdebatkan, dapat diselesaikan".

Masalah nyata dalam pemilihan: bukan memilih protokol, tetapi membuat kombinasi.
Banyak evaluasi solusi gagal karena pertanyaannya salah. Pertanyaan yang benar bukanlah apakah kita harus menggunakan protokol tertentu, tetapi apa kombinasi data kita, apa indikator target kita, apa kondisi batas kita. Disarankan untuk berjalan melalui empat tindakan.
Pertama, lakukan inventarisasi aset data. Setidaknya membedakan data status, data objek, data pencarian, data audit, buat template inventaris menjadi kolom tetap, minimal delapan item: jenis data, peningkatan harian, puncak konfirmasi, rasio baca/tulis, periode retensi, tingkat kepatuhan, target latensi, batas biaya. Setelah kolom disatukan, komunikasi pemilihan antar tim akan jauh lebih cepat.
Definisikan kembali target tingkat layanan. Tulis batas waktu P95/P99, waktu pemulihan RTO, titik pemulihan RPO, target ketersediaan, batas biaya TB tunggal secara jelas, jika tidak, semua diskusi berikut tidak memiliki ukuran.
Selanjutnya, bangun pemetaan kemampuan. Memetakan penyimpanan permanen, bukti ketersediaan yang periodik, pengambilan latensi rendah, dan tata kelola akses ke lapisan teknologi yang berbeda, bukan berharap satu lapisan mencakup semuanya.
Akhirnya, tentukan ambang migrasi. Data mana yang diizinkan untuk disimpan secara terpusat dalam periode transisi, indikator apa yang memicu migrasi, kapan harus menyelesaikan penggantian desentralisasi. Salah satu praktik yang berguna adalah menetapkan dua ambang batas: jika biaya TB tunggal dalam dua siklus statistik berturut-turut melebihi anggaran, atau latensi P95 terus-menerus melebihi target selama dua minggu, secara otomatis memicu peninjauan migrasi arsitektur. Tanpa ambang batas, tidak ada tata kelola, dan periode transisi akan menjadi keadaan permanen.
Solusi implementasi: arsitektur lima lapis, mengikat penyimpanan, pengambilan, dan pengelolaan menjadi satu kesatuan.
Nilai arsitektur tidak terletak pada jumlah lapisan, tetapi pada apakah dapat membentuk siklus tertutup yang dapat diverifikasi. Berdasarkan kerangka kerja sebelumnya, solusi menyusut menjadi lima lapisan: lapisan pengikatan on-chain, lapisan penyimpanan objek, lapisan indeks pengambilan, lapisan bukti ketersediaan, dan lapisan izin kunci. Tujuannya adalah menjadikan verifikasi sebagai kemampuan default, menjadikan kinerja sebagai kemampuan yang dapat dikonfigurasi, dan menjadikan tata kelola sebagai proses yang dapat dieksekusi.
Dalam Bitroot, lima lapisan ini dapat dipahami lebih lanjut sebagai modul tata kelola penyimpanan dari AI Stack: Parallel EVM menyediakan kemampuan pengikatan dan penyelesaian frekuensi tinggi, Pipeline BFT menyediakan kepastian latensi rendah, jaringan penyimpanan terdistribusi menangani objek besar dan data sejarah, lapisan indeks pengambilan melayani AI Agent dan pemanggilan aplikasi, lapisan bukti ketersediaan mengubah kualitas layanan node menjadi reputasi dan imbalan, sedangkan lapisan izin kunci menghubungkan kedaulatan pengguna, perlindungan privasi, dan otorisasi komersial model.
Lapisan pengikatan on-chain hanya menyimpan status minimal yang diperlukan: komitmen data, sidik jari versi, ringkasan kebijakan izin, peristiwa penyelesaian. Objek besar tidak di-chain, yang di-chain adalah bukti bahwa objek ini ada dan versinya benar. Ini menjaga verifikasi on-chain, tanpa membebani throughput dengan file besar.
Dalam konteks arsitektur Bitroot, lapisan pengikatan on-chain bukan hanya tempat untuk "mencatat hash", tetapi juga pintu masuk bersama untuk pendaftaran aset AI, tata kelola izin, distribusi keuntungan, dan penyelesaian sengketa. Dataset, bobot model, indeks vektor, dan log inferensi semuanya dapat disimpan di luar chain dengan cara yang paling sesuai, tetapi komitmen versi mereka, status otorisasi, catatan panggilan, dan kepemilikan pendapatan perlu memasuki status on-chain Bitroot. Dengan cara ini, penyimpanan off-chain bertanggung jawab untuk menampung volume, sementara Bitroot bertanggung jawab untuk menampung kepercayaan.
Lapisan penyimpanan objek menampung data nyata, menggunakan strategi campuran kode dan salinan: objek bernilai tinggi dan akses rendah lebih mengutamakan toleransi kesalahan, objek bernilai menengah dan akses tinggi lebih mengutamakan efisiensi pengambilan. Strategi ini bukan konfigurasi statis, tetapi harus disesuaikan secara dinamis berdasarkan panas akses dan tingkat bisnis.
Lapisan indeks pengambilan menggabungkan indeks metadata dan indeks vektor ke dalam direktori yang bersatu, lapisan panas menangani pengambilan online, lapisan dingin menangani pengarsipan dan rekonstruksi. Semua versi indeks harus mencatat versi data sumber dan parameter pembangun, jika tidak, pergeseran indeks tidak dapat dipertanggungjawabkan.
Lapisan bukti ketersediaan mengkuantifikasi perilaku node. Tingkat keberhasilan merespons tantangan, latensi respons, dan tingkat keberhasilan perbaikan semuanya masuk dalam penilaian reputasi, penilaian ini kemudian diikat pada distribusi imbalan, menghindari hanya memberi imbalan pada kapasitas, tanpa memberi imbalan pada ketersediaan.
Lapisan izin kunci mengontrol akses dan kepatuhan. Data sensitif menggunakan kunci berjenjang dan otorisasi berbatas waktu, log inferensi menggunakan penyimpanan desensitisasi ditambah pemutaran audit, panggilan model menggunakan izin yang dapat dicabut. Operasi izin itu sendiri juga harus meninggalkan jejak, untuk mencegah pergeseran konfigurasi.
Lima lapisan ini di tingkat eksekusi membentuk siklus tertutup, bukan jalur aliran satu arah: setelah data diintegrasikan, pertama-tama diiris dan dikodekan ke dalam lapisan objek, setelah ditulis, indeks dihasilkan dan diikat ke on-chain; kueri online melalui lapisan panas, jika tidak mencukupi, kembali ke lapisan dingin; secara bersamaan dengan mengembalikan hasil, memicu pemeriksaan integritas dan pemeriksaan izin, perilaku kunci memasuki penyelesaian dan audit. Nilai sebenarnya dari rantai ini adalah, setiap node, kapan saja, dapat menjawab empat pertanyaan: dari mana data berasal, versi saat ini apa, siapa yang memiliki hak akses, dan apakah sistem dapat membuktikan bahwa data tersedia.
Ini juga merupakan alasan kunci mengapa Bitroot cocok untuk menangani tata kelola penyimpanan AI. Panggilan oleh AI Agent, perubahan versi model, perubahan otorisasi data, sengketa hasil pencarian, bukanlah operasi latar belakang frekuensi rendah, tetapi kejadian on-chain yang terus terjadi seiring pertumbuhan aplikasi. Jika rantai dasar tidak dapat memberikan latensi konfirmasi yang cukup rendah dan throughput yang cukup tinggi, maka tata kelola penyimpanan pada akhirnya akan terpaksa kembali ke spreadsheet off-chain dan rekonsiliasi manual. Kombinasi Parallel EVM dan Pipeline BFT Bitroot, nilai bukan hanya TPS lebih tinggi, tetapi juga memungkinkan kejadian tata kelola frekuensi tinggi ini dapat diikat, diselesaikan, dan dipertanggungjawabkan secara real-time.

Siapa yang akan membayar: biarkan ketersediaan, bukan kapasitas, menentukan keuntungan.
Penyimpanan harus mampu berjalan dalam jangka panjang, insentif harus disesuaikan dengan ketersediaan, bukan hanya menumpuk kapasitas. Hanya memberi imbalan kapasitas, sama dengan secara tidak langsung mendorong node untuk menumpuk hard disk, mengurangi layanan. Hal ini telah diperbaiki oleh Filecoin dengan mekanisme: ia memperkenalkan konsep daya yang disesuaikan kualitas (quality-adjusted power), sehingga sektor yang menerima pesanan penyimpanan yang nyata, terutama pesanan yang telah diverifikasi, yaitu unit pengukuran minimum dari ruang penyimpanan, memperoleh bobot lebih tinggi dalam pengukuran daya, sehingga mengarahkan imbalan pada kapasitas yang benar-benar memberikan layanan, dan bukan hanya kapasitas kosong yang dikemas. Pemikiran ini layak untuk ditiru oleh setiap lapisan insentif yang dibangun sendiri.
Untuk menjadikannya fungsi penghargaan yang dapat dieksekusi, setidaknya harus menghitung empat dimensi secara bersamaan dan jelas menyatakan logika bobot masing-masing. Kapasitas menentukan bagian dasar, menjawab seberapa besar ruang yang Anda janjikan. Tingkat online dan latensi respons menentukan koefisien kualitas layanan, menjawab apakah ruang ini benar-benar dapat diambil saat dibutuhkan, yang seharusnya memiliki bobot tinggi, jika tidak, ketersediaan hanya akan menjadi slogan. Tingkat keberhasilan pemulihan data menentukan kredibilitas pemulihan bencana, menjawab apakah salinan dapat dibangun kembali setelah node terputus, yang langsung berkaitan dengan kelangsungan data ekor panjang. Kepadatan nilai data menentukan tambahan sisi permintaan, menetapkan pengali yang berbeda untuk dataset bernilai tinggi dan model permintaan tinggi, memberikan pengembalian lebih tinggi untuk data langka yang sering dipanggil. Penghargaan harus diberikan kepada layanan yang dapat dibuktikan, bukan kapasitas yang dinyatakan.
Hanya memiliki insentif positif tidak cukup, sisi pembatas dari staking, hukuman, dan arbitrase juga harus ada, dan harus memenuhi ketentuan dasar: keuntungan yang diharapkan dari kecurangan harus lebih rendah daripada biaya yang diharapkan dari penyitaan, jika tidak, mekanisme pembuktian apa pun akan dilalui oleh rasionalitas ekonomi. Staking membuat node menjanjikan ketersediaan dengan mempertaruhkan biaya, ukuran kolateral harus sebanding dengan daya komputasi dan nilai data yang mereka janjikan; dalam desain Filecoin, pihak penyimpanan harus membayar kolateral di muka berdasarkan daya komputasi yang dijanjikan, jika terputus dalam jendela pembuktian, akan memicu biaya kerugian, jika sektor ditinggalkan secara permanen, akan memicu penyitaan akhir yang lebih berat, makna dari sistem hukuman bertahap ini adalah membedakan antara pemutusan jangka pendek dan keluar jahat. Arbitrase akan menggunakan bukti on-chain untuk mendorong penyelesaian sengketa: ketika pengguna mengklaim data tidak tersedia, dan node mengklaim telah memberikan layanan normal, catatan tantangan, bukti sampling, dan log peristiwa membentuk dasar arbitrasi yang dapat dibaca mesin, menyusutkan sengketa yang sebelumnya memerlukan intervensi manusia menjadi penilaian on-chain yang dapat diverifikasi.
Skenario AI juga perlu menambahkan lapisan tata kelola yang lebih sulit: bagaimana membagi keuntungan antara tiga pihak. Sebuah model yang dipanggil berulang kali, di belakangnya adalah data kontributor yang menyediakan korpus, kontributor model yang melakukan pelatihan, dan node penyimpanan yang bertanggung jawab atas pengelolaan; ketiga pihak berkontribusi terhadap nilai pemanggilan akhir, tetapi kontribusi sulit untuk diamati secara langsung. Cara yang layak adalah membangun atribusi nilai berdasarkan peristiwa on-chain yang terukur: pemanggilan dihitung per kali dan diselesaikan secara otomatis, data dan model terikat melalui sidik jari versi dan hubungan keturunan ke setiap pemanggilan, kemudian dibagi secara otomatis menurut proporsi pembagian yang dapat diprogram yang sudah ditentukan sebelumnya, menghindari konflik di kemudian hari. Yang mendukungnya adalah mekanisme daftar hitam dan penyitaan, untuk perilaku pengunggahan data yang jahat, pelanggaran hak cipta, dan pencurian model, yang segera disita dan dibekukan pendapatan di masa mendatang begitu dinyatakan oleh arbitrase. Jika tidak, akan muncul hasil yang kontra-intuitif: semakin berhasil di dalam aset, semakin banyak perselisihan dalam pembagian dan pengakuan, yang pada akhirnya justru merusak kepercayaan ekosistem itu sendiri.
Kepatuhan bukanlah tambalan setelah peluncuran, tetapi batasan di tahap arsitektur: garis dasar keamanan adalah enkripsi end-to-end, manajemen kunci berjenjang, dan rotasi siklus, ditambah pemeriksaan hash dan komitmen Merkle memastikan bahwa unduhan dapat diverifikasi, kemudian menggunakan beberapa salinan dan kode penghapusan bersama untuk menangani pemulihan bencana; sisi privasi membuat kontrol akses dengan izin minimal berdasarkan tingkat data, mendukung otorisasi yang dapat dicabut, otorisasi sekali, dan otorisasi berbatas waktu, akses kunci dan operasi menyisakan jejak di seluruh rantai, memudahkan pemutaran audit. Kepatuhan juga merupakan bagian yang paling mudah ditunda dan paling mahal: kebijakan lokal dan pengiriman lintas domain harus dapat dikonfigurasi, permintaan penghapusan, akses, dan audit harus memiliki antarmuka proses standar; yang paling sulit adalah konflik alami antara tidak dapat diubah dan dapat dihapus, solusi yang layak adalah penghapusan terenkripsi ditambah penghapusan indeks: menghancurkan kunci membuat ciphertext tidak dapat dipulihkan, dan membuat indeks tidak dapat dicari, dengan catatan di rantai yang tersisa untuk memenuhi permintaan penghapusan. Dari uji coba hingga produksi ada tiga ambang batas: pertama membangun siklus tertutup yang paling dapat dipercaya, menjalankan penyimpanan objek, pengikatan on-chain, pemeriksaan integritas, dan pemantauan dasar, pengujian berdasarkan ketersediaan, tingkat keberhasilan baca/tulis, konsistensi versi antara pengikatan dan objek, dan pemulihan kegagalan; kemudian membuat aset AI dan tata kelola indeks, memperkenalkan manajemen aset dataset dan model, garis keturunan versi, pemisahan indeks vektor panas-dingin, otorisasi panggilan model, dan pendaftaran sumber data pelatihan, pengujian berdasarkan kejelasan pelatihan, model yang dapat dikembalikan dan diaudit, serta latensi lapisan panas yang memenuhi target, dampak rekonstruksi indeks yang dapat dikendalikan; akhirnya memperkenalkan pencarian yang dapat dibuktikan dan tata kelola otomatis, dengan tantangan pembuktian, pemindahan kebijakan, dan otomatisasi penghargaan dan hukuman, pengujian berdasarkan cakupan bukti ketersediaan, waktu penanganan risiko, penurunan biaya per unit, serta perubahan kebijakan yang dapat dilacak dan dibatalkan. Sistem indikator adalah sistem strategi dan bukan laporan tampilan. Jika hanya menulis item teknis, tidak menulis hasil bisnis, solusi penyimpanan akan runtuh menjadi pusat biaya murni; disarankan untuk membagi menjadi tiga lapisan: indikator teknis dasar (ketersediaan, latensi P95/P99, throughput, RTO/RPO, tingkat kesalahan) menjawab apakah sistem sehat, indikator khusus AI (tingkat pelacakan data pelatihan, tingkat reproduksi model, cakupan verifikasi inferensi, konsistensi indeks) menjawab apakah kualitas model dapat dikelola, indikator hasil bisnis (pertumbuhan pasokan data, penurunan biaya panggilan, tingkat aktif node, skala perdagangan aset) menjawab apakah sistem menciptakan nilai, ada hubungan pemetaan antara ketiga lapisan, kegunaan sebenarnya dari indikator adalah input untuk penyesuaian strategi, bukan laporan tampilan. Lima titik kegagalan yang paling umum dapat dihindari sebelumnya: hanya melakukan penyimpanan tanpa melakukan tata kelola versi, data tidak berarti dapat digunakan, dan dapat digunakan tidak berarti dapat direproduksi; hanya memperhatikan kapasitas tanpa memperhatikan bukti ketersediaan, memberikan imbalan berdasarkan kapasitas akan mendorong penumpukan kapasitas ringan dalam layanan; meskipun pemisahan panas-dingin telah dilakukan, tetapi strategi sinkronisasi tidak diterapkan, sinkronisasi versi indeks dan penanganan kegagalan tidak tertutup; strategi kepatuhan ditunda, izin, log, desensitisasi, dan respons penghapusan semakin lama ditunda, biaya semakin tinggi; arsitektur transisi tanpa mekanisme keluar, terlebih dahulu terpusat kemudian desentralisasi adalah jalur yang masuk akal, tetapi tanpa ambang batas migrasi akan membuat keadaan transisi menjadi permanen, menyimpang dari tujuan awal.
Siklus lengkap Bitroot: dari data, model ke AI Agent
Dalam siklus tertutup ini, Bitroot dapat mengubah setiap perilaku kunci aset AI menjadi peristiwa yang dapat diselesaikan: pendaftaran dataset, publikasi versi model, rekonstruksi indeks vektor, panggilan AI Agent, pengikatan log inferensi, otorisasi dan pencabutan izin, tantangan sengketa dan hasil arbitrase. Di chain tidak perlu menampung semua data, tetapi harus menampung bukti minimal dari perilaku ini. Hanya dengan cara ini, hubungan nilai antara data, model, daya komputasi, dan aplikasi tidak akan terhenti pada janji lisan, tetapi akan masuk ke pembagian yang dapat diprogram dan tata kelola yang dapat diaudit.
Menerapkan mekanisme ini dalam operasi dan ekspansi ekosistem Bitroot, insentif penyimpanan tidak seharusnya dirancang sebagai subsidi perangkat keras terpisah, tetapi harus menjadi bagian dari aliran nilai AI Stack: kontributor data mendapatkan keuntungan karena data mereka dilatih atau dipanggil, kontributor model mendapatkan keuntungan karena layanan model, dan node penyimpanan serta pengambilan mendapatkan keuntungan karena layanan yang terus tersedia dan latensi rendah, sedangkan node verifikasi dan tantangan mendapatkan imbalan karena menemukan ketidaktersediaan, pergeseran indeks, atau anomali izin. Dengan cara ini, sistem ekonomi Bitroot menghargai bukan "unggahan", tetapi "secara berkelanjutan terbukti berguna."
Penyimpanan bukanlah pusat biaya, tetapi sistem distribusi kepercayaan dan nilai.
Penyimpanan terdistribusi di era AI harus menyelesaikan bukan menggantikan produk penyimpanan objek tertentu, juga bukan mengejar narasi desentralisasi, tetapi empat hal yang lebih sulit: bukti terpercaya yang dapat digunakan dalam jangka panjang, tatanan tata kelola kolaborasi antar pihak, jalur tanggung jawab untuk data dan model, insentif ekonomi yang berkelanjutan.
Arsitektur lapisan protokol tunggal tidak dapat mencakup target ini. Jalur yang lebih realistis adalah arsitektur komposit: pengalamatan konten menjaga integritas, bukti penyimpanan menjaga ketersediaan dimensi waktu, lapisan permanen menjaga sejarah kunci, lapisan panas menjaga pengalaman online, pengikatan on-chain menjaga tata kelola dan penyelesaian yang dapat dibuktikan. Ini bukan kompromi, tetapi rasionalitas teknik. Fokus implementasi tidak hanya pada fungsi yang paling lengkap, tetapi pada siklus tertutup yang paling cepat terbentuk, pertama-tama jalankan siklus tertutup yang paling dapat dipercaya, kemudian tambahkan lapisan demi lapisan untuk mengubah AI menjadi aset, pencarian dapat dibuktikan, dan tata kelola otomatis.
Menyederhanakan metode ini menjadi tindakan satu minggu, sebenarnya hanya ada tiga langkah: hari pertama menyelesaikan tabel inventaris data dengan delapan kolom, hari ketiga menjalankan sekali rantai minimum dari penerimaan, penyimpanan, pengambilan hingga verifikasi dalam satu domain bisnis nyata, hari ketujuh menggunakan latensi P95 dan biaya per unit untuk melakukan tinjauan ambang batas migrasi. Dengan menyelesaikan tiga langkah ini, tim akan beralih dari konsensus konseptual ke konsensus teknik.
Juga harus mengakui batasan nyata: terlepas dari kombinasi protokol apa pun yang digunakan, ada trade-off antara biaya, latensi, dan ketahanan, tidak ada jawaban tunggal yang optimal untuk semua bisnis. Solusi yang benar-benar berkelanjutan datang dari iterasi berkelanjutan di bawah batasan yang jelas, bukan konfigurasi statis jangka panjang setelah satu keputusan.
Masa depan yang akan menghapus sebuah proyek, sering kali bukan karena TPS yang tidak cukup tinggi, tetapi karena jalur tanggung jawab data yang tidak jelas; di era blockchain AI, penyimpanan bukan hanya tentang menaruh data, tetapi membuat data dapat dibuktikan kapan saja.
Kesimpulan
Kompetisi blockchain AI yang sebenarnya, pada akhirnya tidak akan berhenti hanya pada perbandingan TPS, Gas, atau waktu konfirmasi. Kinerja adalah pintu masuk, tetapi bukan akhir. Memasuki era aplikasi asli AI, sistem on-chain tidak hanya akan menangani transaksi, tetapi juga versi data, panggilan model, penjadwalan daya komputasi, catatan inferensi, perilaku Agent, dan distribusi keuntungan multi-pihak.
Ini juga merupakan penilaian Bitroot terhadap lapisan penyimpanan: penyimpanan bukanlah modul tambahan, tetapi lapisan yang paling dekat dengan sumber nilai dalam AI Stack. Apakah data dapat dibuktikan, apakah model dapat direproduksi, apakah panggilan dapat diaudit, apakah pendapatan dapat dibagi secara otomatis, menentukan apakah jaringan AI yang terdesentralisasi benar-benar memiliki keberlangsungan jangka panjang.
Apa yang ingin dibangun oleh Bitroot, bukanlah rantai yang hanya mengejar eksekusi lebih cepat, tetapi infrastruktur yang memungkinkan aset AI dapat dikonfirmasi, dipanggil, diselesaikan, dan dikelola. Parallel EVM dan Pipeline BFT menyelesaikan kapasitas penanganan kejadian on-chain frekuensi tinggi, penyimpanan terdistribusi dan mekanisme yang dapat divalidasi menyelesaikan dasar kepercayaan data dan model AI, sedangkan pembagian yang dapat diprogram dan tata kelola on-chain mengubah kontribusi menjadi insentif ekonomi yang berkelanjutan.
Ketika AI Agent mulai bertindak atas nama pengguna, ketika model dan data mulai menjadi aset yang dapat diperdagangkan, ketika daya komputasi, penyimpanan, dan layanan inferensi memasuki jaringan nilai yang sama, penyimpanan tidak lagi menjadi masalah "di mana menaruh file".
Ini akan menjadi dasar kepercayaan bagi blockchain AI, serta sistem distribusi nilai untuk jaringan cerdas generasi berikutnya.
Dalam pandangan Bitroot, masa depan yang benar-benar penting bukan siapa yang memiliki data terbanyak, tetapi siapa yang dapat membuktikan, memanggil, dan mempertanggungjawabkan data kapan saja, dan akhirnya berpartisipasi dalam penyelesaian nilai.
Tentang Bitroot
Bitroot adalah proyek Layer 1 publik yang berfokus pada eksekusi paralel dan arsitektur asli AI. Bitroot mengadopsi jalur teknologi kompatibel EVM dan, melalui mekanisme eksekusi paralel, optimasi konsensus, dan desain antarmuka terkait AI, mengeksplorasi untuk menyediakan lingkungan eksekusi on-chain yang berkinerja tinggi dan biaya rendah untuk aplikasi AI Agent, DeFi, dan Web3.
Artikel ini berasal dari kontribusi, tidak mewakili pandangan BlockBeats.
Klik untuk mengetahui posisi yang dibuka oleh BlockBeats.
Selamat datang di komunitas resmi BlockBeats:
Grup langganan Telegram: https://t.me/theblockbeats
Grup diskusi Telegram: https://t.me/BlockBeats_App
Akun resmi Twitter: https://twitter.com/BlockBeatsAsia
#Bitroot
Laporan kesalahan/pengaduan.
Artikel terkaitBlockchain Bitroot diundang untuk hadir di konferensi AI Tencent Cloud Singapura, berbicara bersama Solana tentang masa depan.

B.AI resmi diluncurkan: membangun dasar keuangan untuk AI Agent, mendorong logika dasar komersial di era AGI.

Analisis mendalam teknologi EVM paralel Bitroot: Desain dan implementasi arsitektur blockchain berkinerja tinggi.
