Penulis: 0xjacobzhao | https://linktr.ee/0xjacobzhao
Laporan penelitian independen ini didukung oleh IOSG Ventures. Proses penelitian dan penulisan terinspirasi oleh karya Sam Lehman (Pantera Capital) tentang pembelajaran penguatan. Terima kasih kepada Ben Fielding (Gensyn.ai), Gao Yuan (Gradient), Samuel Dare & Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang atas saran berharga mereka pada artikel ini. Artikel ini berusaha untuk objektivitas dan akurasi, tetapi beberapa sudut pandang melibatkan penilaian subjektif dan mungkin mengandung bias. Kami menghargai pemahaman para pembaca.
Kecerdasan buatan sedang beralih dari pembelajaran statistik berbasis pola menuju sistem penalaran terstruktur, dengan pasca-pelatihan—terutama pembelajaran penguatan—menjadi pusat untuk skala kemampuan. DeepSeek-R1 menandakan pergeseran paradigma: pembelajaran penguatan sekarang secara nyata meningkatkan kedalaman penalaran dan pengambilan keputusan kompleks, berevolusi dari sekadar alat penyelarasan menjadi jalur peningkatan kecerdasan yang berkelanjutan.
Secara paralel, Web3 membentuk ulang produksi AI melalui komputasi terdesentralisasi dan insentif kripto, yang verifikabilitas dan koordinasinya selaras secara alami dengan kebutuhan pembelajaran penguatan. Laporan ini memeriksa paradigma pelatihan AI dan dasar-dasar pembelajaran penguatan, menyoroti keuntungan struktural dari “Pembelajaran Penguatan × Web3,” dan menganalisis Prime Intellect, Gensyn, Nous Research, Gradient, Grail dan Fraction AI.
I. Tiga Tahap Pelatihan AI
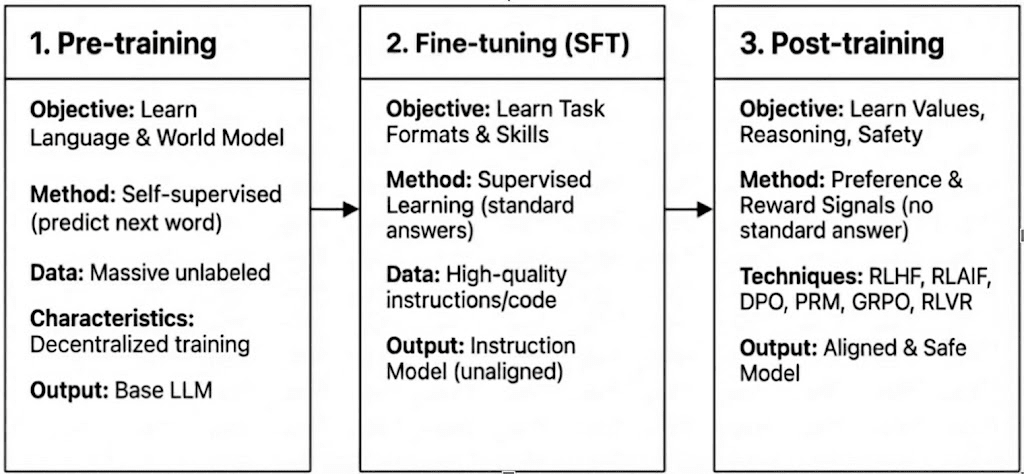
Pelatihan LLM modern mencakup tiga tahap—pra-pelatihan, penyempurnaan terawasi (SFT), dan pasca-pelatihan/pembelajaran penguatan—yang masing-masing berkaitan dengan pembangunan model dunia, penyuntikan kemampuan tugas, dan pembentukan penalaran dan nilai. Karakteristik komputasi dan verifikasinya menentukan seberapa kompatibel mereka dengan desentralisasi.
Pra-pelatihan: membangun dasar statistik dan multimodal inti melalui pembelajaran mandiri massal, mengkonsumsi 80–95% dari total biaya dan memerlukan cluster GPU yang disinkronkan ketat, homogen, dan akses data bandwidth tinggi, menjadikannya secara inheren terpusat.
Penyempurnaan Terawasi (SFT): menambahkan kemampuan tugas dan instruksi dengan dataset yang lebih kecil dan biaya yang lebih rendah (5–15%), sering menggunakan metode PEFT seperti LoRA atau Q-LoRA, tetapi masih bergantung pada sinkronisasi gradien, membatasi desentralisasi.
Pasca-pelatihan: Pasca-pelatihan terdiri dari beberapa tahap iteratif yang membentuk kemampuan penalaran model, nilai, dan batasan keamanan. Ini mencakup pendekatan berbasis RL (misalnya, RLHF, RLAIF, GRPO), optimisasi preferensi non-RL (misalnya, DPO), dan model hadiah proses (PRM). Dengan persyaratan data dan biaya yang lebih rendah (sekitar 5–10%), komputasi fokus pada rollouts dan pembaruan kebijakan. Dukungan bawaannya untuk eksekusi asinkron, terdistribusi—sering tanpa memerlukan bobot model penuh—menjadikan pasca-pelatihan fase terbaik yang cocok untuk jaringan pelatihan terdesentralisasi berbasis Web3 ketika digabungkan dengan komputasi yang dapat diverifikasi dan insentif di rantai.
II. Lanskap Teknologi Pembelajaran Penguatan
2.1 Arsitektur Sistem Pembelajaran Penguatan
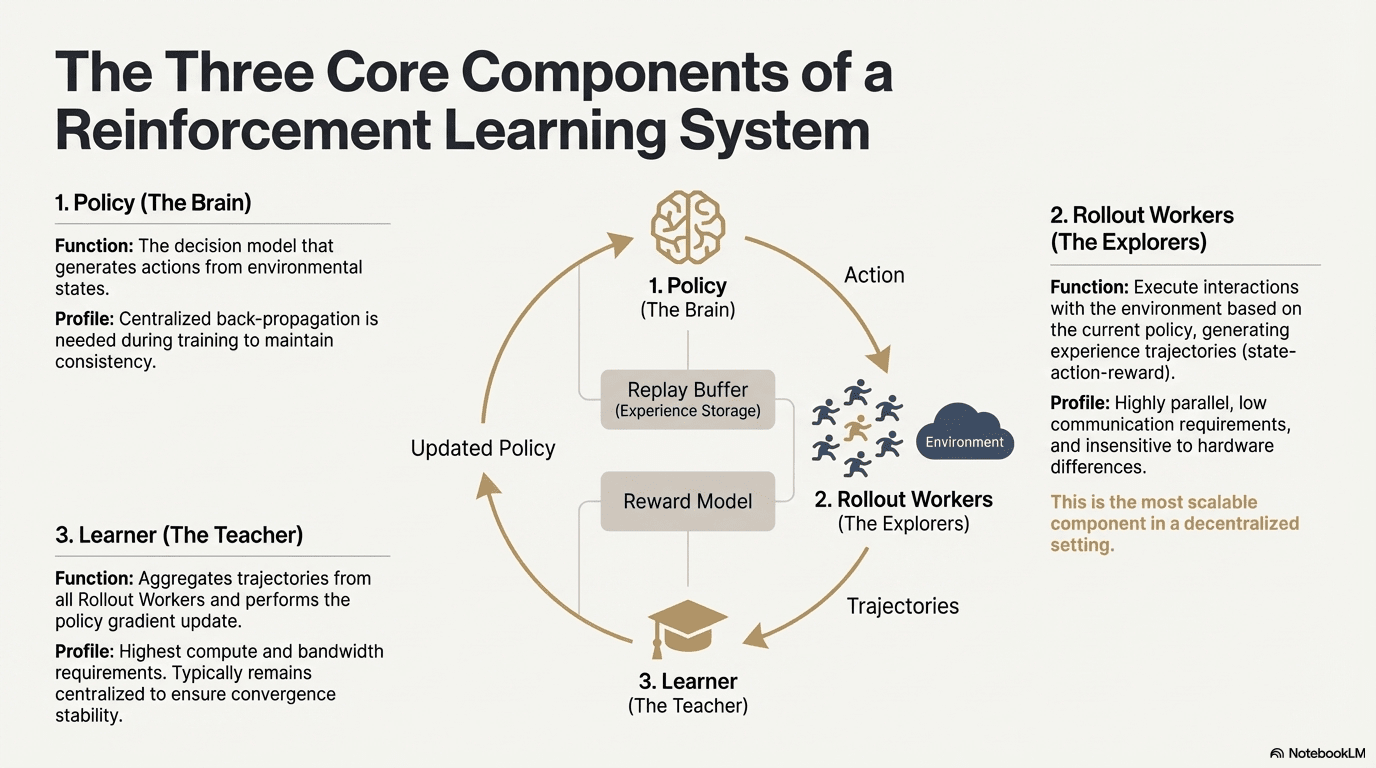
Pembelajaran penguatan memungkinkan model untuk meningkatkan pengambilan keputusan melalui loop umpan balik dari interaksi lingkungan, sinyal hadiah, dan pembaruan kebijakan. Secara struktural, sistem RL terdiri dari tiga komponen inti: jaringan kebijakan, rollout untuk sampling pengalaman, dan pelajar untuk optimisasi kebijakan. Kebijakan menghasilkan lintasan melalui interaksi dengan lingkungan, sementara pelajar memperbarui kebijakan berdasarkan hadiah, membentuk proses pembelajaran iteratif yang berkelanjutan.
Jaringan Kebijakan (Kebijakan): Menghasilkan tindakan dari keadaan lingkungan dan merupakan inti pengambilan keputusan sistem. Ini memerlukan backpropagation terpusat untuk menjaga konsistensi selama pelatihan; selama inferensi, dapat didistribusikan ke node yang berbeda untuk operasi paralel.
Sampling Pengalaman (Rollout): Node mengeksekusi interaksi lingkungan berdasarkan kebijakan, menghasilkan lintasan keadaan-tindakan-hadiah. Proses ini sangat paralel, memiliki komunikasi yang sangat rendah, tidak sensitif terhadap perbedaan perangkat keras, dan merupakan komponen yang paling cocok untuk ekspansi dalam desentralisasi.
Pelajar: Mengagregasi semua lintasan Rollout dan mengeksekusi pembaruan gradien kebijakan. Ini adalah satu-satunya modul dengan persyaratan tertinggi untuk daya komputasi dan bandwidth, sehingga biasanya dijaga terpusat atau sedikit terpusat untuk memastikan stabilitas konvergensi.
2.2 Kerangka Tahap Pembelajaran Penguatan
Pembelajaran penguatan biasanya dapat dibagi menjadi lima tahap, dan keseluruhan proses sebagai berikut:
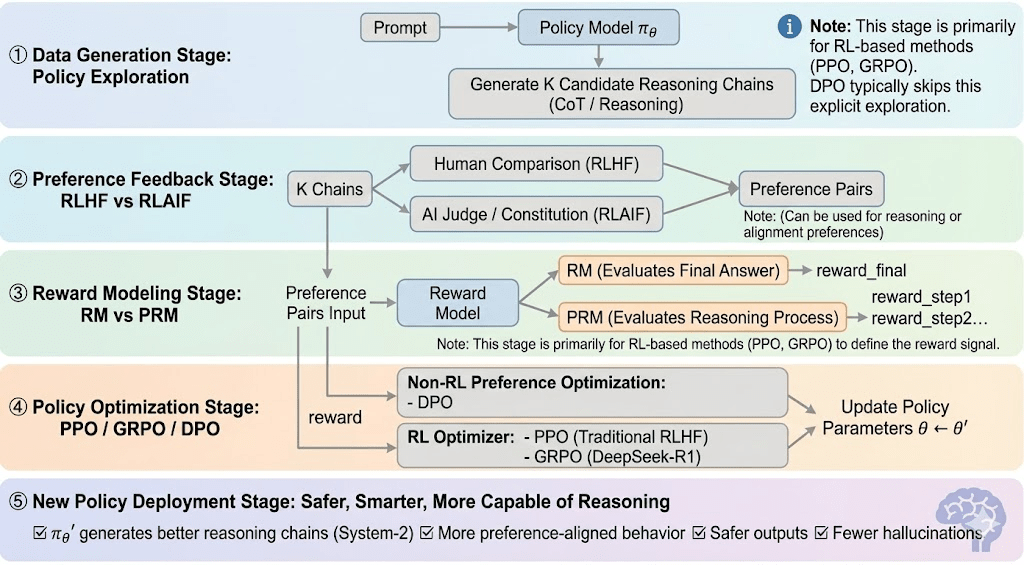
Tahap Pembuatan Data (Eksplorasi Kebijakan): Mengingat prompt, kebijakan mengambil sampel beberapa rantai penalaran atau lintasan, menyediakan kandidat untuk evaluasi preferensi dan pemodelan hadiah serta mendefinisikan ruang eksplorasi kebijakan.
Tahap Umpan Balik Preferensi (RLHF / RLAIF):
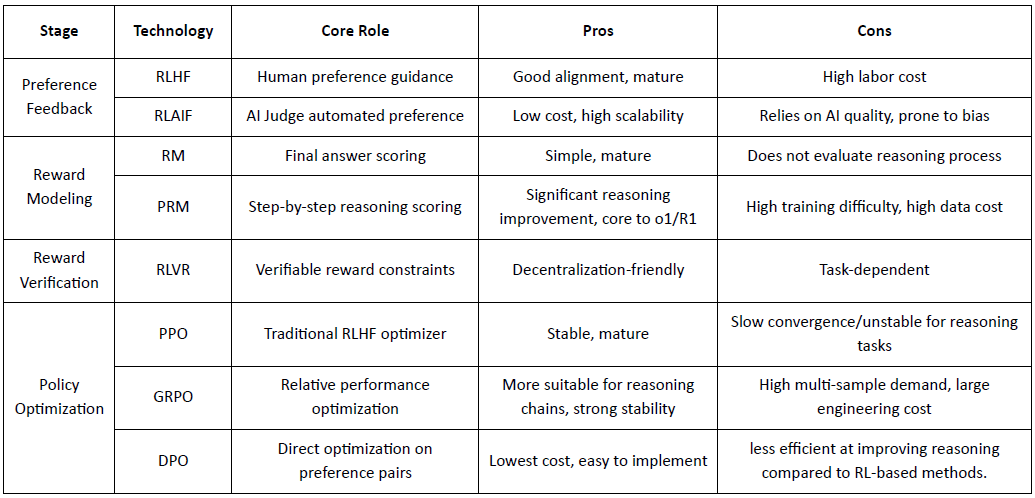
RLHF (Pembelajaran Penguatan dari Umpan Balik Manusia): melatih model hadiah dari preferensi manusia dan kemudian menggunakan RL (biasanya PPO) untuk mengoptimalkan kebijakan berdasarkan sinyal hadiah itu.
RLAIF (Pembelajaran Penguatan dari Umpan Balik AI): menggantikan manusia dengan hakim AI atau aturan konstitusi, memotong biaya dan meningkatkan skala penyelarasan—sekarang pendekatan dominan untuk Anthropic, OpenAI, dan DeepSeek.
Tahap Pemodelan Hadiah (Pemodelan Hadiah): Belajar untuk memetakan output ke hadiah berdasarkan pasangan preferensi. RM mengajarkan model "apa jawaban yang benar," sementara PRM mengajarkan model "bagaimana cara berpikir dengan benar."
RM (Model Hadiah): Digunakan untuk mengevaluasi kualitas jawaban akhir, hanya memberi skor pada output.
Model Hadiah Proses (PRM): memberi skor penalaran langkah demi langkah, secara efektif melatih proses penalaran model (misalnya, dalam o1 dan DeepSeek-R1).
Verifikasi Hadiah (RLVR / Verifikasi Hadiah): Lapisan verifikasi hadiah membatasi sinyal hadiah untuk diambil dari aturan yang dapat direproduksi, fakta kebenaran, atau mekanisme konsensus. Ini mengurangi peretasan hadiah dan bias sistemik, serta meningkatkan auditabilitas dan ketahanan dalam lingkungan pelatihan terbuka dan terdistribusi.
Tahap Optimisasi Kebijakan (Optimisasi Kebijakan): Memperbarui parameter kebijakan $\theta$ di bawah panduan sinyal yang diberikan oleh model hadiah untuk mendapatkan kebijakan $\pi_{\theta'}$ dengan kemampuan penalaran yang lebih kuat, keamanan yang lebih tinggi, dan pola perilaku yang lebih stabil. Metode optimisasi arus utama termasuk:
PPO (Optimisasi Kebijakan Proksimal): pengoptimal RLHF standar, dihargai karena stabilitas tetapi dibatasi oleh konvergensi lambat dalam penalaran kompleks.
GRPO (Optimisasi Kebijakan Relatif Grup): diperkenalkan oleh DeepSeek-R1, mengoptimalkan kebijakan menggunakan estimasi keuntungan tingkat grup daripada peringkat sederhana, mempertahankan besaran nilai dan memungkinkan optimisasi rantai penalaran yang lebih stabil.
DPO (Optimisasi Preferensi Langsung): melewati RL dengan mengoptimalkan langsung pada pasangan preferensi—murah dan stabil untuk penyelarasan, tetapi tidak efektif dalam meningkatkan penalaran.
Tahap Penyebaran Kebijakan Baru (Penyebaran Kebijakan Baru): model yang diperbarui menunjukkan penalaran Sistem-2 yang lebih kuat, penyelarasan preferensi yang lebih baik, lebih sedikit halusinasi, dan keamanan yang lebih tinggi, dan terus meningkatkan melalui loop umpan balik iteratif.
2.3 Aplikasi Industri Pembelajaran Penguatan
Pembelajaran Penguatan (RL) telah berkembang dari kecerdasan permainan awal menjadi kerangka inti untuk pengambilan keputusan otonom lintas industri. Skenario aplikasinya, berdasarkan kematangan teknologi dan implementasi industri, dapat diringkas menjadi lima kategori besar:
Permainan & Strategi: Arah paling awal di mana RL diverifikasi. Dalam lingkungan dengan "informasi sempurna + hadiah yang jelas" seperti AlphaGo, AlphaZero, AlphaStar, dan OpenAI Five, RL menunjukkan kecerdasan pengambilan keputusan yang sebanding atau melampaui pakar manusia, meletakkan dasar untuk algoritma RL modern.
Robotika & AI Berwujud: Melalui kontrol berkelanjutan, pemodelan dinamika, dan interaksi lingkungan, RL memungkinkan robot untuk belajar manipulasi, kontrol gerakan, dan tugas lintas-modal (misalnya, RT-2, RT-X). Ini dengan cepat bergerak menuju industrialisasi dan merupakan jalur teknis kunci untuk penerapan robot dunia nyata.
Penalaran Digital / Sistem LLM-2: RL + PRM menggerakkan model besar dari "imitasi bahasa" ke "penalaran terstruktur." Pencapaian perwakilan termasuk DeepSeek-R1, OpenAI o1/o3, Anthropic Claude, dan AlphaGeometry. Pada dasarnya, ini melakukan optimisasi hadiah di tingkat rantai penalaran daripada hanya mengevaluasi jawaban akhir.
Penemuan Ilmiah & Optimisasi Matematika: RL menemukan struktur atau strategi optimal dalam ruang pencarian yang besar tanpa label, penghargaan kompleks. Ini telah mencapai terobosan dasar dalam AlphaTensor, AlphaDev, dan Fusion RL, menunjukkan kemampuan eksplorasi yang melampaui intuisi manusia.
Pengambilan Keputusan Ekonomi & Perdagangan: RL digunakan untuk optimisasi strategi, pengendalian risiko berdimensi tinggi, dan pembuatan sistem perdagangan adaptif. Dibandingkan dengan model kuantitatif tradisional, ia dapat belajar secara terus-menerus dalam lingkungan yang tidak pasti dan merupakan komponen penting dari keuangan cerdas.
III. Kesesuaian Alami Antara Pembelajaran Penguatan dan Web3
Pembelajaran penguatan dan Web3 secara alami selaras sebagai sistem yang didorong insentif: RL mengoptimalkan perilaku melalui hadiah, sementara blockchain mengoordinasikan peserta melalui insentif ekonomi. Kebutuhan inti RL—rollouts heterogen skala besar, distribusi hadiah, dan eksekusi yang dapat diverifikasi—secara langsung memetakan pada kekuatan struktural Web3.
Penguraian Penalaran dan Pelatihan: Pembelajaran penguatan terpisah menjadi fase rollout dan pembaruan: rollouts berat komputasi tetapi ringan komunikasi dan dapat berjalan secara paralel di GPU konsumen terdistribusi, sementara pembaruan memerlukan sumber daya terpusat dengan bandwidth tinggi. Penguraian ini memungkinkan jaringan terbuka menangani rollouts dengan insentif token, sementara pembaruan terpusat mempertahankan stabilitas pelatihan.
Verifikabilitas: ZK (Zero-Knowledge) dan Bukti-Pembelajaran menyediakan cara untuk memverifikasi apakah node benar-benar menjalankan penalaran, menyelesaikan masalah kejujuran dalam jaringan terbuka. Dalam tugas deterministik seperti kode dan penalaran matematis, verifier hanya perlu memeriksa jawabannya untuk mengkonfirmasi beban kerja, secara signifikan meningkatkan kredibilitas sistem RL terdesentralisasi.
Lapisan Insentif, Mekanisme Produksi Umpan Balik Berbasis Ekonomi Token: Insentif token Web3 dapat langsung memberi penghargaan kepada kontributor umpan balik RLHF/RLAIF, memungkinkan generasi preferensi yang transparan dan tanpa izin, dengan staking dan slashing menegakkan kualitas lebih efisien daripada crowdsourcing tradisional.
Potensi untuk Pembelajaran Penguatan Multi-Agen (MARL): Blockchain membentuk lingkungan multi-agen terbuka yang didorong insentif dengan keadaan publik, eksekusi yang dapat diverifikasi, dan insentif yang dapat diprogram, menjadikannya testbed alami untuk MARL skala besar meskipun bidang ini masih awal.
IV. Analisis Proyek Web3 + Pembelajaran Penguatan
Berdasarkan kerangka teori di atas, kita akan secara singkat menganalisis proyek-proyek paling representatif dalam ekosistem saat ini:
Intellect Utama: Pembelajaran Penguatan Asinkron prime-rl
Prime Intellect bertujuan untuk membangun pasar komputasi global terbuka dan tumpukan superintelligence sumber terbuka, mencakup Prime Compute, keluarga model INTELLECT, lingkungan RL terbuka, dan mesin data sintetik skala besar. Kerangka prime-rl intinya dirancang untuk RL terdistribusi asinkron, dilengkapi oleh OpenDiLoCo untuk pelatihan efisien bandwidth dan TopLoc untuk verifikasi.
Gambaran Umum Komponen Infrastruktur Intellect Utama
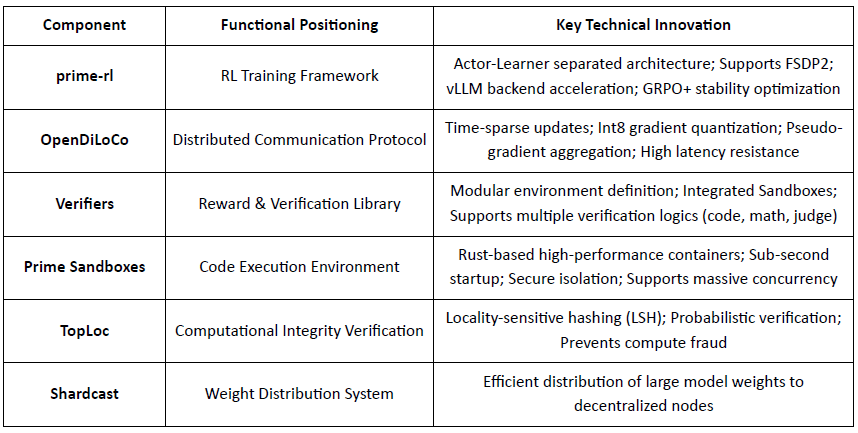
Batu Loncatan Teknikal: kerangka Pembelajaran Penguatan Asinkron prime-rl
prime-rl adalah mesin pelatihan inti Prime Intellect, dirancang untuk lingkungan terdesentralisasi besar-besaran yang asinkron. Ini mencapai inferensi throughput tinggi dan pembaruan yang stabil melalui pemisahan lengkap Actor–Learner. Pelaksana (Pekerja Rollout) dan Pelajar (Pelatih) tidak memblokir secara sinkron. Node dapat bergabung atau meninggalkan kapan saja, hanya perlu terus menarik kebijakan terbaru dan mengunggah data yang dihasilkan:
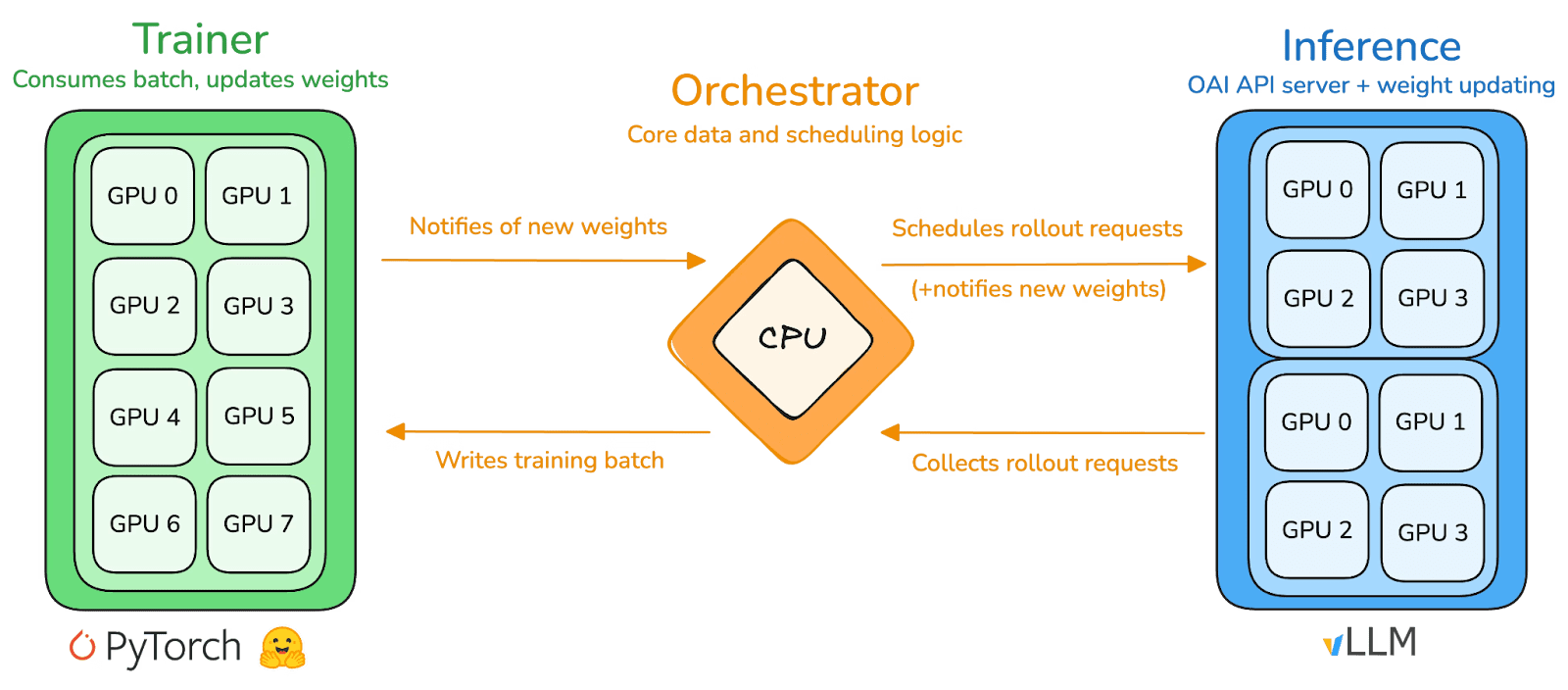
Aktor (Pekerja Rollout): Bertanggung jawab untuk inferensi model dan pembuatan data. Prime Intellect secara inovatif mengintegrasikan mesin inferensi vLLM di ujung Aktor. Teknologi PagedAttention vLLM dan kemampuan Batching Berkelanjutan memungkinkan Aktor menghasilkan lintasan inferensi dengan throughput yang sangat tinggi.
Pelajar (Pelatih): Bertanggung jawab untuk optimisasi kebijakan. Pelajar secara asinkron menarik data dari Buffer Pengalaman bersama untuk pembaruan gradien tanpa menunggu semua Aktor menyelesaikan batch saat ini.
Orkestrator: Bertanggung jawab untuk penjadwalan bobot model dan aliran data.
Inovasi Kunci dari prime-rl:
Asinkron Sejati: prime-rl meninggalkan paradigma sinkron tradisional PPO, tidak menunggu node lambat, dan tidak memerlukan penyelarasan batch, memungkinkan jumlah GPU dan kinerja berapa pun untuk diakses kapan saja, menetapkan kelayakan RL terdesentralisasi.
Integrasi Dalam FSDP2 dan MoE: Melalui pembagian parameter FSDP2 dan aktivasi jarang MoE, prime-rl memungkinkan model dengan puluhan miliar parameter untuk dilatih secara efisien dalam lingkungan terdistribusi. Aktor hanya menjalankan ahli aktif, secara signifikan mengurangi biaya VRAM dan inferensi.
GRPO+ (Optimisasi Kebijakan Relatif Grup): GRPO menghilangkan jaringan Kritikus, secara signifikan mengurangi komputasi dan overhead VRAM, secara alami beradaptasi dengan lingkungan asinkron. GRPO+ prime-rl memastikan konvergensi yang andal dalam kondisi latensi tinggi melalui mekanisme stabilisasi.
Keluarga Model INTELLECT: Simbol Kedewasaan Teknologi RL Terdesentralisasi
INTELLECT-1 (10B, Okt 2024): Membuktikan untuk pertama kalinya bahwa OpenDiLoCo dapat dilatih secara efisien dalam jaringan heterogen di tiga benua (pembagian komunikasi < 2%, pemanfaatan komputasi 98%), mematahkan persepsi fisik pelatihan lintas wilayah.
INTELLECT-2 (32B, Apr 2025): Sebagai model RL Pertama yang Tanpa Izin, membuktikan kemampuan konvergensi stabil dari prime-rl dan GRPO+ dalam lingkungan latensi multi-langkah dan asinkron, mewujudkan RL terdesentralisasi dengan partisipasi komputasi terbuka global.
INTELLECT-3 (106B MoE, Nov 2025): Mengadopsi arsitektur jarang yang mengaktifkan hanya 12B parameter, dilatih pada 512×H200 dan mencapai kinerja inferensi unggulan (AIME 90.8%, GPQA 74.4%, MMLU-Pro 81.9%, dll.). Kinerja keseluruhan mendekati atau melampaui model sumber tertutup terpusat yang jauh lebih besar dari dirinya sendiri.
Prime Intellect telah membangun tumpukan RL terdesentralisasi penuh: OpenDiLoCo memotong lalu lintas pelatihan lintas wilayah dengan urutan besar sambil mempertahankan ~98% pemanfaatan di seluruh benua; TopLoc dan Verifiers memastikan inferensi dan data hadiah yang dapat dipercaya melalui sidik jari aktivasi dan verifikasi yang dibatasi; dan mesin data SINTETIK menghasilkan rantai penalaran berkualitas tinggi sambil memungkinkan model besar berjalan secara efisien di GPU konsumen melalui paralelisme pipeline. Bersama-sama, komponen ini mendasari pembuatan data, verifikasi, dan inferensi yang dapat diskalakan dalam RL terdesentralisasi, dengan seri INTELLECT menunjukkan bahwa sistem semacam itu dapat menghasilkan model kelas dunia dalam praktik.
Gensyn: Tumpukan Inti RL Swarm dan SAPO
Gensyn berusaha untuk menyatukan komputasi global yang menganggur menjadi jaringan pelatihan AI yang tidak memerlukan kepercayaan dan dapat diskalakan, menggabungkan eksekusi yang distandarisasi, koordinasi P2P, dan verifikasi tugas di rantai. Melalui mekanisme seperti RL Swarm, SAPO, dan SkipPipe, ia memisahkan generasi, evaluasi, dan pembaruan di seluruh GPU heterogen, memberikan bukan hanya komputasi, tetapi juga kecerdasan yang dapat diverifikasi.
Aplikasi RL dalam Tumpukan Gensyn
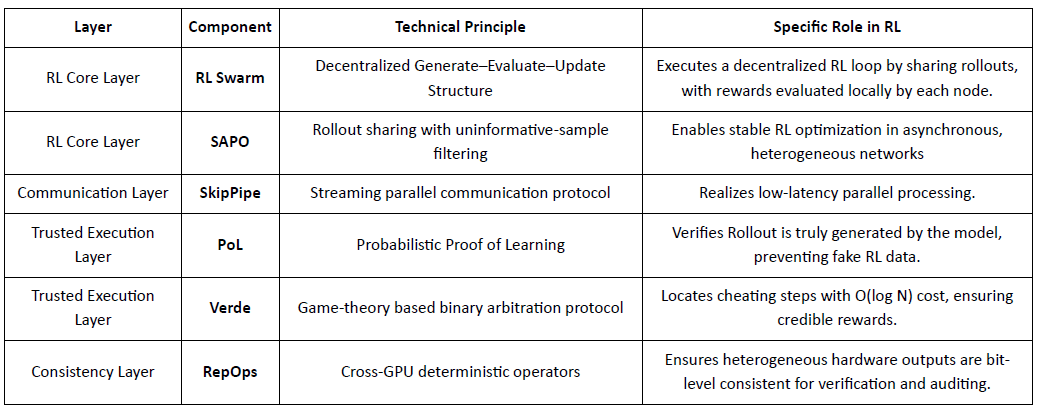
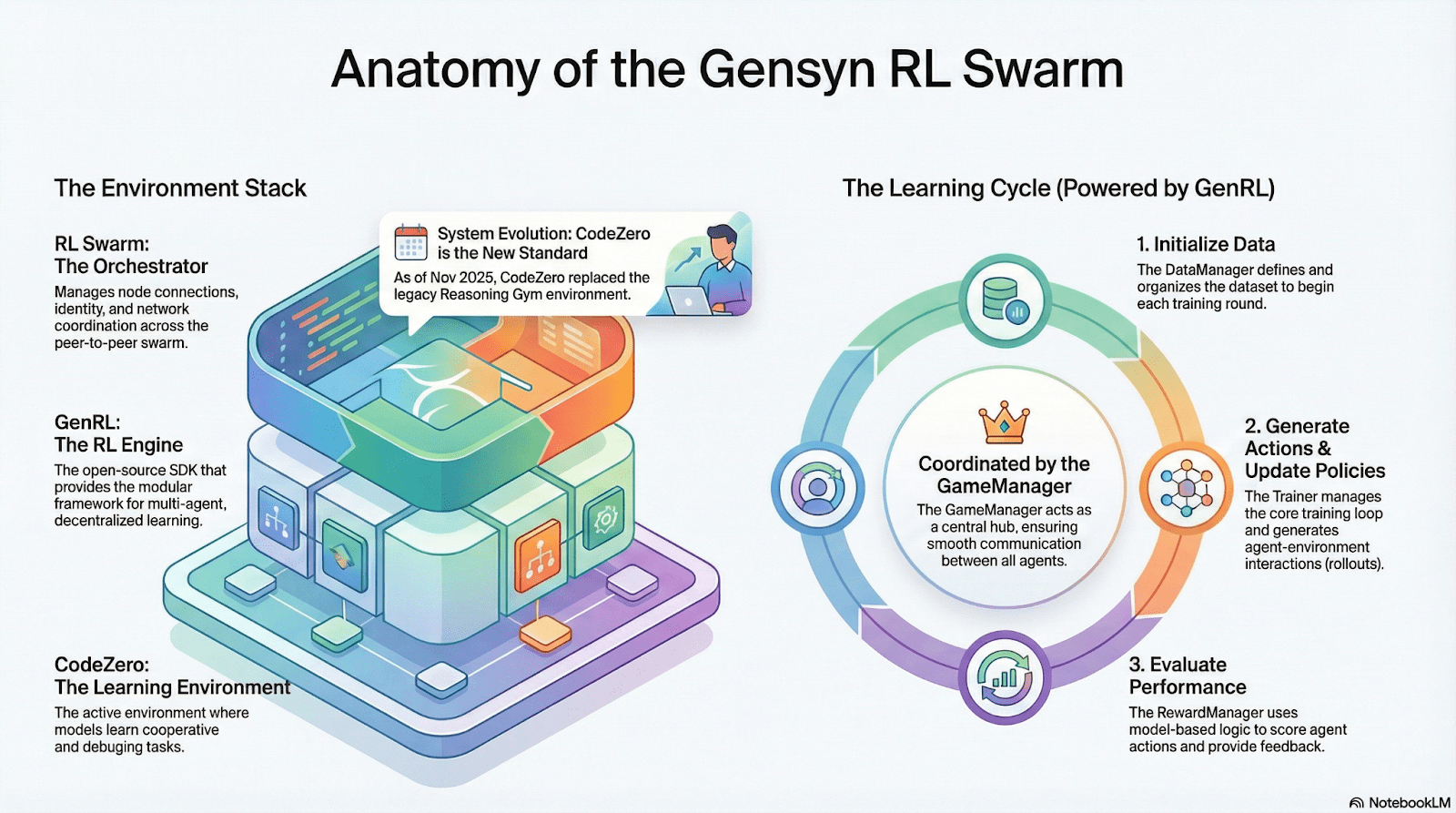
RL Swarm: Mesin Pembelajaran Penguatan Kolaboratif Terdesentralisasi
RL Swarm menunjukkan mode kolaborasi baru yang brand new. Ini bukan lagi distribusi tugas sederhana, tetapi loop tak terbatas dari loop generate–evaluate–update yang terdesentralisasi yang terinspirasi oleh pembelajaran kolaboratif yang menyimulasikan pembelajaran sosial manusia:
Penyelesai (Pelaksana): Bertanggung jawab untuk inferensi model lokal dan pembuatan Rollout, tidak terhalang oleh heterogenitas node. Gensyn mengintegrasikan mesin inferensi throughput tinggi (seperti CodeZero) secara lokal untuk menghasilkan lintasan lengkap daripada hanya jawaban.
Pengusul: Secara dinamis menghasilkan tugas (masalah matematika, pertanyaan kode, dll.), memungkinkan keberagaman tugas dan adaptasi seperti kurikulum untuk menyesuaikan kesulitan pelatihan dengan kemampuan model.
Penilai: Menggunakan "Model Hakim" yang beku atau aturan untuk memeriksa kualitas output, membentuk sinyal hadiah lokal yang dievaluasi secara independen oleh setiap node. Proses evaluasi dapat diaudit, mengurangi ruang untuk niat jahat.
Ketiga-tiganya membentuk struktur organisasi RL P2P yang dapat menyelesaikan pembelajaran kolaboratif skala besar tanpa penjadwalan terpusat.
SAPO: Algoritma Optimisasi Kebijakan yang Dibangun Kembali untuk Desentralisasi
SAPO (Swarm Sampling Policy Optimization) berfokus pada berbagi rollouts sambil menyaring yang tanpa sinyal gradien, daripada berbagi gradien. Dengan memungkinkan sampling rollout terdesentralisasi skala besar dan memperlakukan rollout yang diterima sebagai yang dihasilkan secara lokal, SAPO mempertahankan konvergensi stabil di lingkungan tanpa koordinasi pusat dan dengan heterogenitas latensi node yang signifikan. Dibandingkan dengan PPO (yang bergantung pada jaringan kritikus yang mendominasi biaya komputasi) atau GRPO (yang bergantung pada estimasi keuntungan tingkat grup daripada peringkat sederhana), SAPO memungkinkan GPU kelas konsumen untuk berpartisipasi secara efektif dalam optimisasi RL skala besar dengan persyaratan bandwidth yang sangat rendah.
Melalui RL Swarm dan SAPO, Gensyn menunjukkan bahwa pembelajaran penguatan—terutama RLVR pasca-pelatihan—secara alami cocok dengan arsitektur terdesentralisasi, karena lebih bergantung pada eksplorasi beragam melalui rollouts daripada pada sinkronisasi parameter frekuensi tinggi. Digabungkan dengan sistem verifikasi PoL dan Verde, Gensyn menawarkan jalur alternatif menuju pelatihan model trillion-parameter: jaringan superintelligence yang berevolusi sendiri yang terdiri dari jutaan GPU heterogen di seluruh dunia.
Nous Research: Lingkungan Pembelajaran Penguatan Atropos
Nous Research sedang membangun tumpukan kognitif terdesentralisasi yang berkembang sendiri, di mana komponen seperti Hermes, Atropos, DisTrO, Psyche, dan World Sim membentuk sistem kecerdasan loop tertutup. Menggunakan metode RL seperti DPO, GRPO, dan sampling penolakan, ia menggantikan jalur pelatihan linier dengan umpan balik berkelanjutan di seluruh pembuatan data, pembelajaran, dan inferensi.
Gambaran Umum Komponen Penelitian Nous
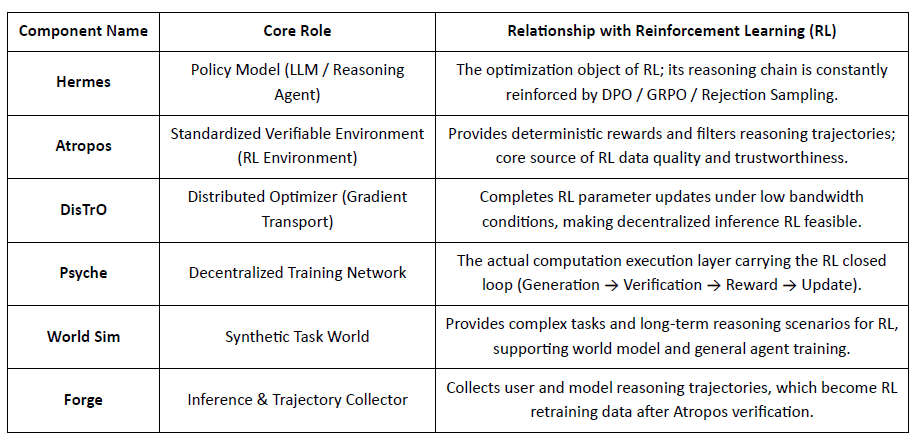
Lapisan Model: Hermes dan Evolusi Kemampuan Penalaran
Seri Hermes adalah antarmuka model utama dari Nous Research yang menghadapi pengguna. Evolusinya jelas menunjukkan jalur industri yang bermigrasi dari penyelarasan SFT/DPO tradisional menuju RL Penalaran:
Hermes 1–3: Penyelarasan Instruksi & Kemampuan Awal Agen: Hermes 1–3 mengandalkan DPO biaya rendah untuk penyelarasan instruksi yang kuat dan memanfaatkan data sintetik serta pengenalan pertama mekanisme verifikasi Atropos dalam Hermes 3.
Hermes 4 / DeepHermes: Menulis gaya berpikir lambat Sistem-2 ke dalam bobot melalui Chain-of-Thought, meningkatkan kinerja matematika dan kode dengan Test-Time Scaling, dan bergantung pada "Rejection Sampling + Verifikasi Atropos" untuk membangun data penalaran murni tinggi.
DeepHermes lebih lanjut mengadopsi GRPO untuk menggantikan PPO (yang sulit diimplementasikan terutama), memungkinkan RL Penalaran berjalan di jaringan GPU terdesentralisasi Psyche, meletakkan dasar teknik untuk skalabilitas RL Penalaran sumber terbuka.
Atropos: Lingkungan Pembelajaran Penguatan yang Dapat Diverifikasi dan Didorong Hadiah
Atropos adalah pusat sejati dari sistem RL Nous. Ini mengenkapsulasi prompt, panggilan alat, eksekusi kode, dan interaksi multi-putaran ke dalam lingkungan RL yang terstandarisasi, secara langsung memverifikasi apakah output benar, sehingga memberikan sinyal hadiah deterministik untuk menggantikan pelabelan manusia yang mahal dan tidak dapat diskalakan. Yang lebih penting, dalam jaringan pelatihan terdesentralisasi Psyche, Atropos bertindak sebagai "hakim" untuk memverifikasi apakah node benar-benar meningkatkan kebijakan, mendukung Bukti-Pembelajaran yang dapat diaudit, secara fundamental menyelesaikan masalah kredibilitas hadiah dalam RL terdistribusi.
DisTrO dan Psyche: Lapisan Pengoptimal untuk Pembelajaran Penguatan Terdesentralisasi
Pelatihan RLF tradisional (RLHF/RLAIF) bergantung pada cluster berkecepatan tinggi terpusat, sebuah penghalang inti yang tidak dapat direplikasi sumber terbuka. DisTrO mengurangi biaya komunikasi RL dengan urutan besar melalui pemisahan momentum dan kompresi gradien, memungkinkan pelatihan berjalan pada bandwidth internet; Psyche menerapkan mekanisme pelatihan ini pada jaringan di rantai, memungkinkan node menyelesaikan inferensi, verifikasi, evaluasi hadiah, dan pembaruan bobot secara lokal, membentuk loop RL lengkap.
Dalam sistem Nous, Atropos memverifikasi rantai pemikiran; DisTrO mengompres komunikasi pelatihan; Psyche menjalankan loop RL; World Sim menyediakan lingkungan kompleks; Forge mengumpulkan penalaran nyata; Hermes menulis semua pembelajaran ke dalam bobot. Pembelajaran penguatan bukan hanya tahap pelatihan, tetapi protokol inti yang menghubungkan data, lingkungan, model, dan infrastruktur dalam arsitektur Nous, menjadikan Hermes sebagai sistem hidup yang mampu perbaikan diri yang berkelanjutan di jaringan komputasi terbuka.
Jaringan Gradien: Arsitektur Pembelajaran Penguatan Echo
Jaringan Gradient bertujuan untuk membangun komputasi AI melalui Tumpukan Intelijen Terbuka: seperangkat protokol interoperable modular yang mencakup komunikasi P2P (Lattica), inferensi terdistribusi (Parallax), pelatihan RL terdesentralisasi (Echo), verifikasi (VeriLLM), simulasi (Mirage), dan koordinasi memori dan agen tingkat lebih tinggi—bersama-sama membentuk infrastruktur kecerdasan terdesentralisasi yang berkembang.
Echo — Arsitektur Pelatihan Pembelajaran Penguatan
Echo adalah kerangka pembelajaran penguatan Gradient. Prinsip desain intinya terletak pada penguraian jalur pelatihan, inferensi, dan data (hadiah) dalam pembelajaran penguatan, menjalankannya secara terpisah dalam Inference Swarm dan Training Swarm heterogen, menjaga perilaku optimisasi yang stabil di seluruh lingkungan heterogen area luas dengan protokol sinkronisasi ringan. Ini secara efektif mengurangi kegagalan SPMD dan bottleneck pemanfaatan GPU yang disebabkan oleh pencampuran inferensi dan pelatihan dalam RLHF / VERL tradisional.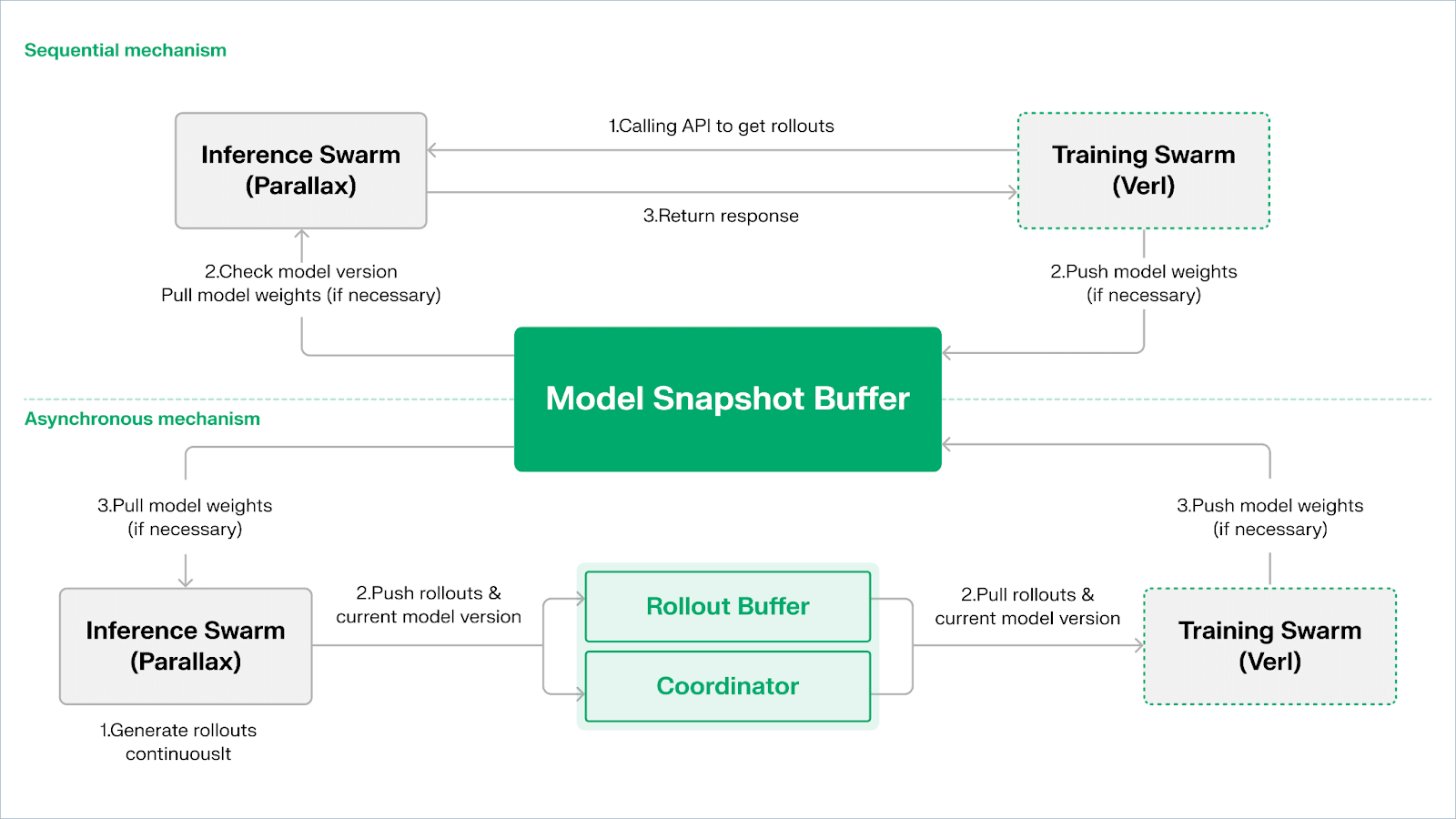
Echo menggunakan "Arsitektur Dual Swarm Inferensi-Pelatihan" untuk memaksimalkan pemanfaatan daya komputasi. Kedua swarm berjalan secara independen tanpa menghalangi satu sama lain:
Maksimalkan Throughput Sampling: Inference Swarm terdiri dari GPU kelas konsumen dan perangkat edge, membangun sampler throughput tinggi melalui pipeline-paralel dengan Parallax, berfokus pada generasi lintasan.
Maksimalkan Daya Komputasi Gradien: Training Swarm dapat berjalan di cluster terpusat atau jaringan GPU kelas konsumen terdistribusi secara global, bertanggung jawab untuk pembaruan gradien, sinkronisasi parameter, dan penyempurnaan LoRA, berfokus pada proses pembelajaran.
Untuk menjaga konsistensi kebijakan dan data, Echo menyediakan dua jenis protokol sinkronisasi ringan: Urutan dan Asinkron, mengelola konsistensi dua arah dari bobot kebijakan dan lintasan:
Mode Tarik Berurutan (Akurasi Pertama): Sisi pelatihan memaksa node inferensi untuk menyegarkan versi model sebelum menarik lintasan baru untuk memastikan kesegaran lintasan, cocok untuk tugas yang sangat sensitif terhadap kedaluwarsa kebijakan.
Mode Dorong-Pull Asinkron (Efisiensi Pertama): Sisi inferensi terus menghasilkan lintasan dengan tag versi, dan sisi pelatihan mengonsumsinya sesuai kecepatan sendiri. Koordinator memantau deviasi versi dan memicu penyegaran bobot, memaksimalkan pemanfaatan perangkat.
Di lapisan bawah, Echo dibangun di atas Parallax (inferensi heterogen dalam lingkungan bandwidth rendah) dan komponen pelatihan terdistribusi ringan (misalnya, VERL), bergantung pada LoRA untuk mengurangi biaya sinkronisasi antar-node, memungkinkan pembelajaran penguatan berjalan stabil di jaringan global yang heterogen.
Grail: Pembelajaran Penguatan dalam Ekosistem Bittensor
Bittensor membangun jaringan fungsi hadiah yang besar, jarang, dan non-stasioner melalui mekanisme konsensus Yuma yang unik.
Covenant AI dalam ekosistem Bittensor membangun jalur terpadu vertikal dari pra-pelatihan ke pasca-pelatihan RL melalui SN3 Templar, SN39 Basilica, dan SN81 Grail. Di antara mereka, SN3 Templar bertanggung jawab untuk pra-pelatihan model dasar, SN39 Basilica menyediakan pasar daya komputasi terdistribusi, dan SN81 Grail berfungsi sebagai "lapisan inferensi yang dapat diverifikasi" untuk pasca-pelatihan RL, membawa proses inti RLHF / RLAIF dan menyelesaikan optimisasi loop tertutup dari model dasar ke kebijakan yang diselaraskan.

GRAIL memverifikasi secara kriptografis rollouts RL dan mengikatnya dengan identitas model, memungkinkan RLHF tanpa kepercayaan. Ini menggunakan tantangan deterministik untuk mencegah pra-perhitungan, sampling biaya rendah dan komitmen untuk memverifikasi rollouts, serta pencetakan sidik jari model untuk mendeteksi substitusi atau replay—menetapkan keaslian dari ujung ke ujung untuk lintasan inferensi RL.
Subnet Grail mengimplementasikan loop pasca-pelatihan gaya GRPO yang dapat diverifikasi: penambang menghasilkan beberapa jalur penalaran, validator menilai kebenaran dan kualitas penalaran, dan hasil dinormalisasi ditulis di rantai. Uji publik meningkatkan akurasi Qwen2.5-1.5B MATH dari 12.7% menjadi 47.6%, menunjukkan ketahanan terhadap kecurangan dan peningkatan kemampuan yang kuat; di Covenant AI, Grail berfungsi sebagai inti kepercayaan dan eksekusi untuk RLVR/RLAIF terdesentralisasi.
Fraction AI: Pembelajaran Penguatan Berbasis Kompetisi RLFC
Fraction AI mereformulasi penyelarasan sebagai Pembelajaran Penguatan dari Kompetisi, menggunakan pelabelan gamified dan kontes agen-versus-agen. Peringkat relatif dan skor hakim AI menggantikan label manusia statis, mengubah RLHF menjadi permainan multi-agen yang kompetitif dan berkelanjutan.
Perbedaan Inti Antara RLHF Tradisional dan RLFC Fraction AI:
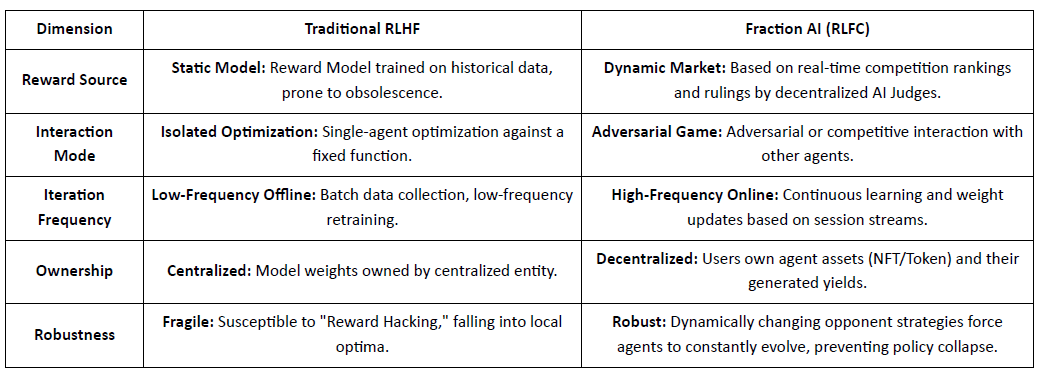
Nilai inti RLFC adalah bahwa hadiah berasal dari lawan dan evaluator yang berkembang, bukan dari satu model, mengurangi peretasan hadiah dan mempertahankan keberagaman kebijakan. Desain ruang membentuk dinamika permainan, memungkinkan perilaku kompetitif dan kooperatif yang kompleks.
Dalam arsitektur sistem, Fraction AI membongkar proses pelatihan menjadi empat komponen kunci:
Agen: Unit kebijakan ringan berbasis LLM sumber terbuka, diperluas melalui QLoRA dengan bobot diferensial untuk pembaruan biaya rendah.
Ruang: Lingkungan domain tugas terisolasi di mana agen membayar untuk masuk dan mendapatkan hadiah dengan menang.
Hakim AI: Lapisan hadiah langsung dibangun dengan RLAIF, menyediakan evaluasi terdesentralisasi yang dapat diskalakan.
Bukti-Pembelajaran: Mengikat pembaruan kebijakan ke hasil kompetisi tertentu, memastikan bahwa proses pelatihan dapat diverifikasi dan tahan kecurangan.
Fraction AI berfungsi sebagai mesin ko-evolusi manusia-mesin: pengguna bertindak sebagai meta-optimizers yang membimbing eksplorasi, sementara agen bersaing untuk menghasilkan data preferensi berkualitas tinggi, memungkinkan penyempurnaan yang tidak memerlukan kepercayaan dan terkomersialisasi.
Perbandingan Arsitektur Proyek Pembelajaran Penguatan Web3
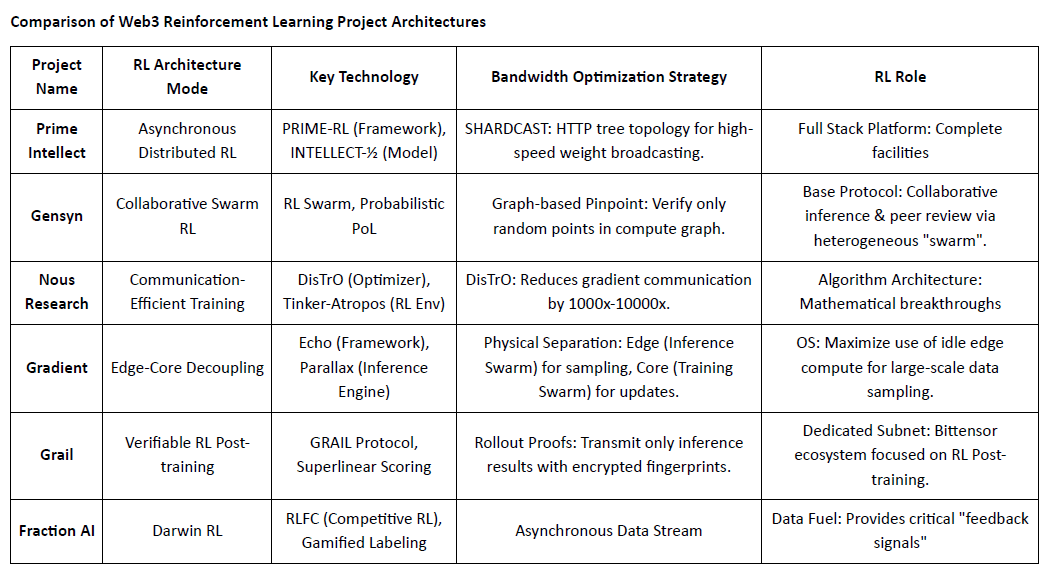
V. Jalur dan Peluang Pembelajaran Penguatan × Web3
Di antara proyek perbatasan ini, meskipun titik masuk berbeda, RL yang dipadukan dengan Web3 secara konsisten converge pada arsitektur “penguraian–verifikasi–insentif” yang dibagikan—sebuah hasil yang tak terhindarkan dari mengadaptasi pembelajaran penguatan ke jaringan terdesentralisasi.
Fitur Arsitektur Umum Pembelajaran Penguatan: Menyelesaikan Batas Fisik Inti dan Masalah Kepercayaan
Penguraian Rollouts & Pembelajaran (Pemisahan Fisik Inferensi/Pelatihan) — Topologi Komputasi Default: Rollouts yang jarang komunikasi, dapat diparalelkan diserahkan kepada GPU kelas konsumen global, sementara pembaruan parameter bandwidth tinggi terfokus di beberapa node pelatihan. Ini benar dari Actor–Learner asinkron Prime Intellect hingga arsitektur dual-swarm Gradient Echo.
Kepercayaan Berbasis Verifikasi — Infrastruktur: Dalam jaringan tanpa izin, keaslian komputasi harus dipaksakan dijamin melalui matematika dan desain mekanisme. Implementasi perwakilan termasuk PoL Gensyn, TopLoc Prime Intellect, dan verifikasi kriptografis Grail.
Loop Insentif Terokenisasi — Regulasi Diri Pasar: Pasokan komputasi, pembuatan data, pengurutan verifikasi, dan distribusi hadiah membentuk loop tertutup. Hadiah mendorong partisipasi, dan Slashing menekan kecurangan, menjaga jaringan tetap stabil dan terus berkembang dalam lingkungan terbuka.
Jalur Teknik Diferensiasi: Titik "Terobosan" Berbeda Di Bawah Arsitektur Konsisten
Meskipun arsitektur konvergen, proyek memilih parit teknis yang berbeda berdasarkan DNA mereka:
Terobosan Algoritma Sekolah (Nous Research): Mengatasi bottleneck bandwidth pelatihan terdistribusi di tingkat pengoptimal—DisTrO mengompres komunikasi gradien dengan urutan besar, bertujuan untuk memungkinkan pelatihan model besar melalui broadband rumah.
Sekolah Rekayasa Sistem (Prime Intellect, Gensyn, Gradient): Fokus pada membangun generasi berikutnya "Sistem Runtime AI." ShardCast Prime Intellect dan Parallax Gradient dirancang untuk memeras efisiensi tertinggi dari cluster heterogen di bawah kondisi jaringan yang ada melalui cara rekayasa ekstrem.
Sekolah Permainan Pasar (Bittensor, Fraction AI): Fokus pada desain Fungsi Hadiah. Dengan merancang mekanisme penilaian yang canggih, mereka membimbing penambang untuk secara sukarela menemukan strategi optimal untuk mempercepat munculnya kecerdasan.
Keuntungan, Tantangan, dan Outlook Akhir
Di bawah paradigma Pembelajaran Penguatan yang dipadukan dengan Web3, keuntungan sistem tingkat pertama tercermin dalam penulisan ulang struktur biaya dan struktur tata kelola.
Perombakan Biaya: Pasca-pelatihan RL memiliki permintaan tak terbatas untuk sampling (Rollout). Web3 dapat memobilisasi daya komputasi global jangka panjang dengan biaya yang sangat rendah, keuntungan biaya yang sulit dicocokkan oleh penyedia cloud terpusat.
Penyelarasan Berdaulat: Memecahkan monopoli teknologi besar pada nilai AI (Penyelarasan). Komunitas dapat memutuskan "apa jawaban yang baik" untuk model melalui pemungutan suara Token, mewujudkan demokratisasi tata kelola AI.
Pada saat yang sama, sistem ini menghadapi dua batasan struktural:
Dinding Bandwidth: Meskipun inovasi seperti DisTrO, latensi fisik masih membatasi pelatihan penuh model parameter ultra-besar (70B+). Saat ini, Web3 AI lebih terbatas pada fine-tuning dan inferensi.
Peretasan Hadiah (Hukum Goodhart): Dalam jaringan yang sangat terinsentif, penambang sangat rentan terhadap "overfitting" aturan hadiah (bermain sistem) daripada meningkatkan kecerdasan nyata. Merancang fungsi hadiah yang tahan kecurangan adalah permainan abadi.
Pekerja Byzantine yang jahat: merujuk pada manipulasi dan pencemaran sinyal pelatihan yang disengaja untuk mengganggu konvergensi model. Tantangan inti bukanlah desain terus-menerus dari fungsi hadiah yang tahan kecurangan, tetapi mekanisme dengan ketahanan terhadap musuh.
RL dan Web3 membentuk kembali kecerdasan melalui jaringan rollout terdesentralisasi, umpan balik yang terasetisasi di rantai, dan agen RL vertikal dengan penangkapan nilai langsung. Peluang sebenarnya bukanlah OpenAI terdesentralisasi, tetapi hubungan produksi kecerdasan baru—pasar komputasi terbuka, penghargaan dan preferensi yang dapat diatur, dan nilai bersama di antara pelatih, penyelarasan, dan pengguna.
Penafian: Artikel ini diselesaikan dengan bantuan alat AI ChatGPT-5 dan Gemini 3. Penulis telah melakukan segala upaya untuk menyunting dan memastikan keaslian dan akurasi informasi, tetapi kekurangan mungkin masih ada. Harap dipahami. Perlu dicatat khususnya bahwa pasar aset kripto sering mengalami perbedaan antara fundamental proyek dan kinerja harga pasar sekunder. Konten artikel ini untuk integrasi informasi dan pertukaran akademis/penelitian saja dan tidak merupakan saran investasi, maupun harus dianggap sebagai rekomendasi untuk membeli atau menjual token apa pun.