

Most conversations about decentralized storage focus on mechanics.
How files are split.
How nodes replicate data.
How availability is verified.
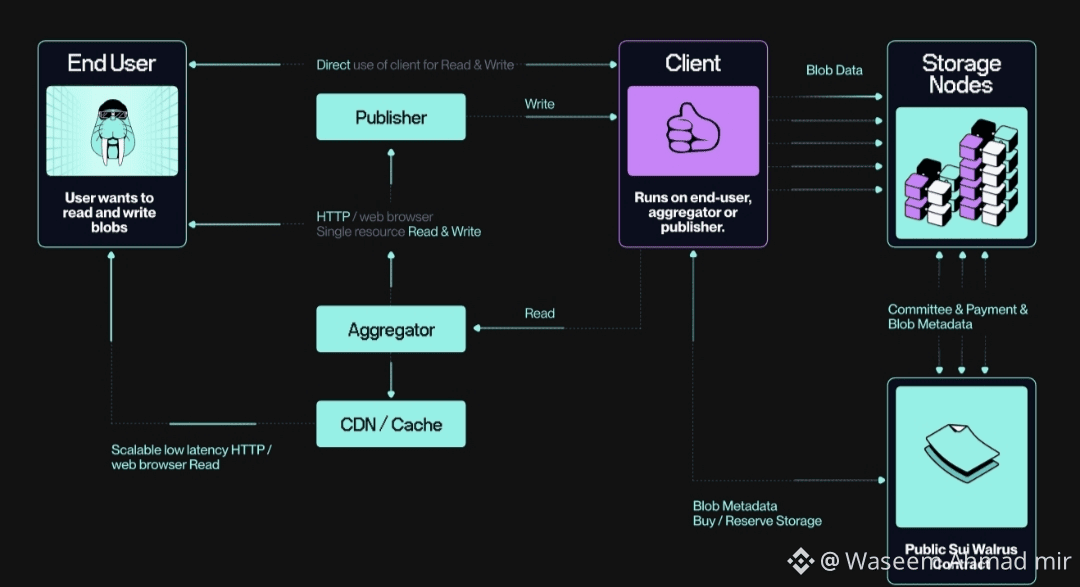
Walrus looks at a different question first: why should the network keep your data alive when no one is watching?
That framing matters more than it sounds.
Storage Fails When Incentives Drift
Technically, many systems can store data.
Economically, far fewer can keep it.
Over time:
nodes rotate out,
priorities change,
rewards shrink,
and “cold” data gets neglected.
Walrus assumes this drift is inevitable. Instead of fighting it with heavier replication, it designs incentives so staying reliable remains the rational choice for operators.
Durability becomes an economic equilibrium, not a hope.
Erasure Coding Is Only Half the Story
Walrus uses erasure coding to split large blobs into pieces that can be reconstructed even if some parts disappear. That’s the technical layer.
But the deeper layer is behavioral:
nodes are rewarded for ongoing availability,
penalties reflect sustained absence, not momentary hiccups,
and data survival doesn’t depend on any single actor.
The system isn’t optimized for perfect uptime. It’s optimized for survival under churn.
Why This Matters for Real Applications
Applications don’t care how elegant the storage math is.
They care whether data is still there months later.
Walrus is designed for:
AI datasets that need long-lived availability,
NFT metadata that must not vanish after hype fades,
archives and logs that are rarely accessed but critical when needed.
These aren’t high-frequency reads. They’re long-memory use cases.
Durability Without Constant Attention
A key insight behind Walrus is that most data shouldn’t require babysitting.
Developers shouldn’t have to:
constantly re-pin files,
monitor node health manually,
or migrate storage every market cycle.
Walrus pushes that burden into the protocol itself. The network is structured so that doing nothing doesn’t mean losing data.
That’s a quiet but important shift.
Economic Signals Replace Manual Trust
Instead of trusting operators by reputation or promises, Walrus relies on:
measurable uptime,
verifiable availability,
and long-term participation.
Nodes that stay aligned earn.
Nodes that don’t gradually lose relevance.
No drama. No sudden slashing. Just steady economic pressure toward reliability.
Why This Fits the Sui Ecosystem
On Sui, applications are increasingly data-heavy:
parallel execution creates richer state,
on-chain logic references off-chain blobs,
and performance expectations are high.
Walrus complements that by acting as a long-term memory layer, not a hot cache. It doesn’t compete with execution speed. It supports continuity.
Durability Is a Time Problem
Most storage designs look good at launch.
Few are tested at year three.
Walrus is built around the idea that:
incentives compound,
neglect accumulates,
and durability is proven only by time.
By aligning rewards with long-term behavior, the protocol tries to make the boring choice staying online, staying honest the profitable one.
The Quiet Payoff
Walrus isn’t trying to win benchmarks for speed or novelty.
It’s trying to answer a simpler question:
Will this data still exist when the excitement is gone?
By treating storage as an economic system first and a technical system second, Walrus is aiming for something many protocols promise but few deliver:
Data that outlasts attention.
If you want the next piece, I can go deeper into:
how Walrus handles blob pricing over time,
why it’s well-suited for AI and ML datasets,
or how enterprises might use Walrus for compliance-grade archiving.
Just tell me the angle.


