@Mira - Trust Layer of AI #Mira
Quando sento “consenso multi-modello per l'affidabilità dell'IA”, la mia prima reazione non è fiducia. È cautela. Non perché controllare a croce i risultati sia una cattiva idea, ma perché la frase rischia di suonare come una garanzia matematica in un dominio che rimane fondamentalmente probabilistico. L'accordo tra i modelli può segnalare fiducia — ma può anche segnalare punti ciechi condivisi. L'affidabilità non deriva solo dall'unanimità. Deriva da come viene gestito il disaccordo.
La maggior parte dei fallimenti dell'IA oggi non sono drammatici. Sono sottili: una citazione fabbricata, una clausola male interpretata, una risposta sicura basata su una premessa falsa. Questi non sono casi limite; sono artefatti strutturali di come i grandi modelli generano testo. Chiedere a un singolo modello di auto-correggersi è come chiedere a un testimone di contro-interrogare la propria testimonianza. A volte funziona. Spesso, semplicemente rafforza lo stesso errore.
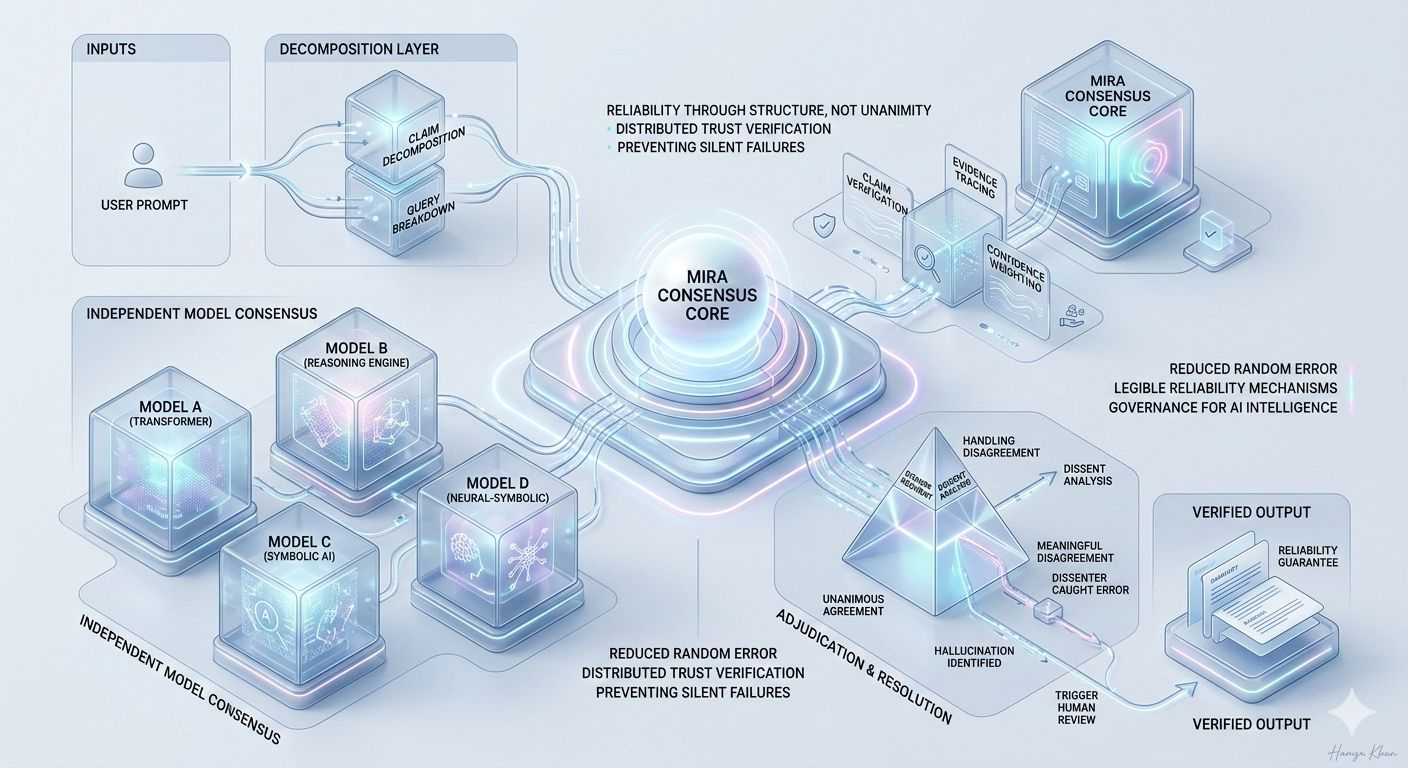
Questo è il punto in cui il consenso multi-modello di Mira riformula il problema. Invece di trattare un output di IA come un prodotto finito, lo tratta come un'affermazione da valutare. Modelli indipendenti multipli esaminano la stessa affermazione, portando ciascuno i propri dati di addestramento, pregiudizi architettonici e modelli di ragionamento. L'affidabilità emerge non dall'autorità di un singolo modello, ma dalla struttura di verifica attorno a loro.
Sembra semplice, ma la meccanica è importante. Il consenso non è una semplice votazione di maggioranza. I modelli possono non essere d'accordo per motivi diversi: ambiguità nel prompt, contesto mancante o dati in conflitto. Uno strato di consenso robusto deve distinguere tra disaccordo significativo e rumore. Se due modelli sono d'accordo e uno dissente, il dissenziente sta individuando un errore sottile o sta allucinando? Il valore del sistema dipende da come adjudica quell'incertezza.
Questo introduce una nuova superficie di verifica: ponderazione della fiducia, decomposizione delle affermazioni e tracciamento delle prove. Output complessi devono essere suddivisi in affermazioni più piccole che possono essere verificate in modo indipendente. Un riassunto di un rapporto finanziario diventa una serie di affermazioni verificabili. Una spiegazione legale diventa una catena di interpretazioni. L'affidabilità migliora non perché i modelli siano più intelligenti, ma perché le affermazioni diventano testabili.
Il cambiamento più profondo è strutturale. Le pipeline di IA tradizionali centralizzano la fiducia nel fornitore del modello. Se il modello è sbagliato, il sistema è sbagliato. L'approccio di Mira distribuisce la fiducia attraverso uno strato di verifica. L'output non è più "vero perché lo ha detto il modello", ma "credibile perché sistemi indipendenti hanno raggiunto conclusioni compatibili." Questo è un cambiamento sottile ma profondo nel modo in cui le informazioni generate dalle macchine guadagnano legittimità.
Certo, l'accordo ha le sue modalità di fallimento. I modelli addestrati su dati sovrapposti possono convergere sullo stesso fatto obsoleto. Il consenso può amplificare il pregiudizio sistemico piuttosto che eliminarlo. E gli input avversari progettati per sfruttare debolezze condivise potrebbero comunque superare la verifica. Un sistema multi-modello riduce l'errore casuale, ma non elimina l'errore coordinato.
Questo è il motivo per cui la trasparenza nel processo di consenso è importante tanto quanto il consenso stesso. Gli utenti devono sapere se la verifica riflette una vera indipendenza o un gruppo di modelli quasi identici. La diversità di architetture, corpora di addestramento e metodi di valutazione diventa parte della garanzia di affidabilità. Senza quella diversità, il consenso rischia di diventare teatro — una performance di accordo piuttosto che una dimostrazione della verità.
C'è anche uno strato economico che emerge al di sotto di quello tecnico. La verifica non è gratuita. Ogni chiamata di modello aggiuntiva comporta costi, latenza e sovraccarico infrastrutturale. Qualcuno deve decidere quali affermazioni valgono la pena di essere verificate, quanto in profondità controllarle e quando accettare la fiducia probabilistica invece della prova deterministica. L'affidabilità diventa un problema di allocazione delle risorse e non solo una sfida tecnica.
Questo sposta la responsabilità verso l'alto nel stack. Le applicazioni che integrano output di IA verificati non sono più semplici consumatori di modelli; sono orchestratori di affidabilità. Scegliendo soglie, gestendo compromessi tra velocità e certezza e definendo quale livello di disaccordo attiva la revisione umana. Se la verifica fallisce, gli utenti non daranno la colpa allo strato di consenso. Daranno la colpa al prodotto che ha promesso risultati affidabili.
Questo, a sua volta, crea una nuova frontiera competitiva. I sistemi di IA non competono solo sulla capacità del modello, ma sulla qualità della verifica: quanto transparentemente gestiscono l'incertezza, quanto elegantemente evidenziano il disaccordo e quanto costantemente prevengono fallimenti silenziosi. I sistemi che guadagnano fiducia non saranno quelli che dichiarano perfezione, ma quelli che rendono i loro meccanismi di affidabilità leggibili e resilienti.
Vista in questo modo, il consenso multi-modello di Mira è meno una caratteristica che uno strato di governance per l'intelligenza artificiale. Tratta gli output dell'IA come proposte soggette a scrutinio, non dichiarazioni da accettare. Riconosce che gli errori sono inevitabili e progetta un processo per contenerli prima che si propaghino in decisioni, mercati o discorsi pubblici.
Il valore a lungo termine di questo design sarà determinato sotto stress. In contesti a basso rischio, il consenso appare impressionante. In ambienti ad alto rischio — automazione finanziaria, triage medico, interpretazione legale — la vera prova è come il sistema si comporta quando i modelli sono in conflitto, i dati sono incompleti o gli incentivi incoraggiano scorciatoie. L'affidabilità non è provata dall'accordo in condizioni calme, ma dalla gestione disciplinata del disaccordo quando il costo dell'errore è alto.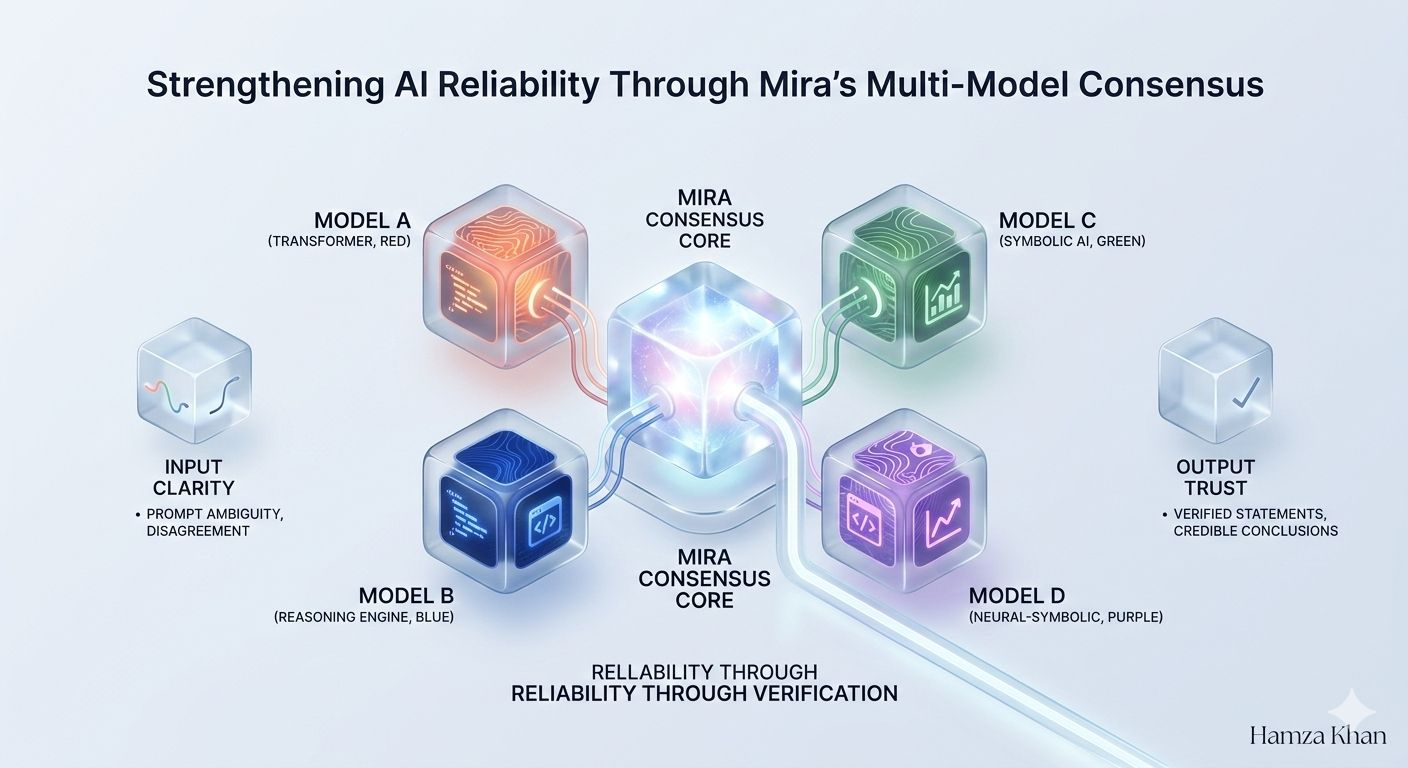
Quindi la domanda che conta non è se più modelli possono essere d'accordo. È chi definisce le regole dell'accordo, come viene interpretato il dissenso, e quali salvaguardie si attivano quando il consenso diventa incerto.


