The first time Mira felt concrete to me wasn’t in a sweeping manifesto. It was in the quieter details where real projects tend to show their work: developer documentation that digs into routing and load balancing, compliance documents written in dry, formal language, and exchange listings that boil everything down to token supply figures and contract addresses.
Look at the developer layer. The SDK overview doesn’t try to inspire you. It reads like a set of tools meant to justify their existence: a single interface connecting to multiple language models, with routing logic, load balancing, and what they call flow management. That emphasis says something. Projects built on hype usually start with vision. Projects built for builders start by shaving off friction.
Still, Mira’s core argument isn’t “we simplify model access.” It goes further than that. It says model outputs aren’t dependable, and that the problem isn’t minor. In its whitepaper, Mira treats hallucinations and bias as structural issues, not small glitches you can patch away. These systems are built to generalize, and that design naturally creates blind spots.
So Mira places its wager elsewhere. Instead of trying to fix the mind of the model, it tries to surround it. The idea is to enforce reliability outside the model itself, through a network that checks results the way auditors review financial records. The pitch isn’t about a smarter brain. It’s about a framework that keeps that brain accountable.
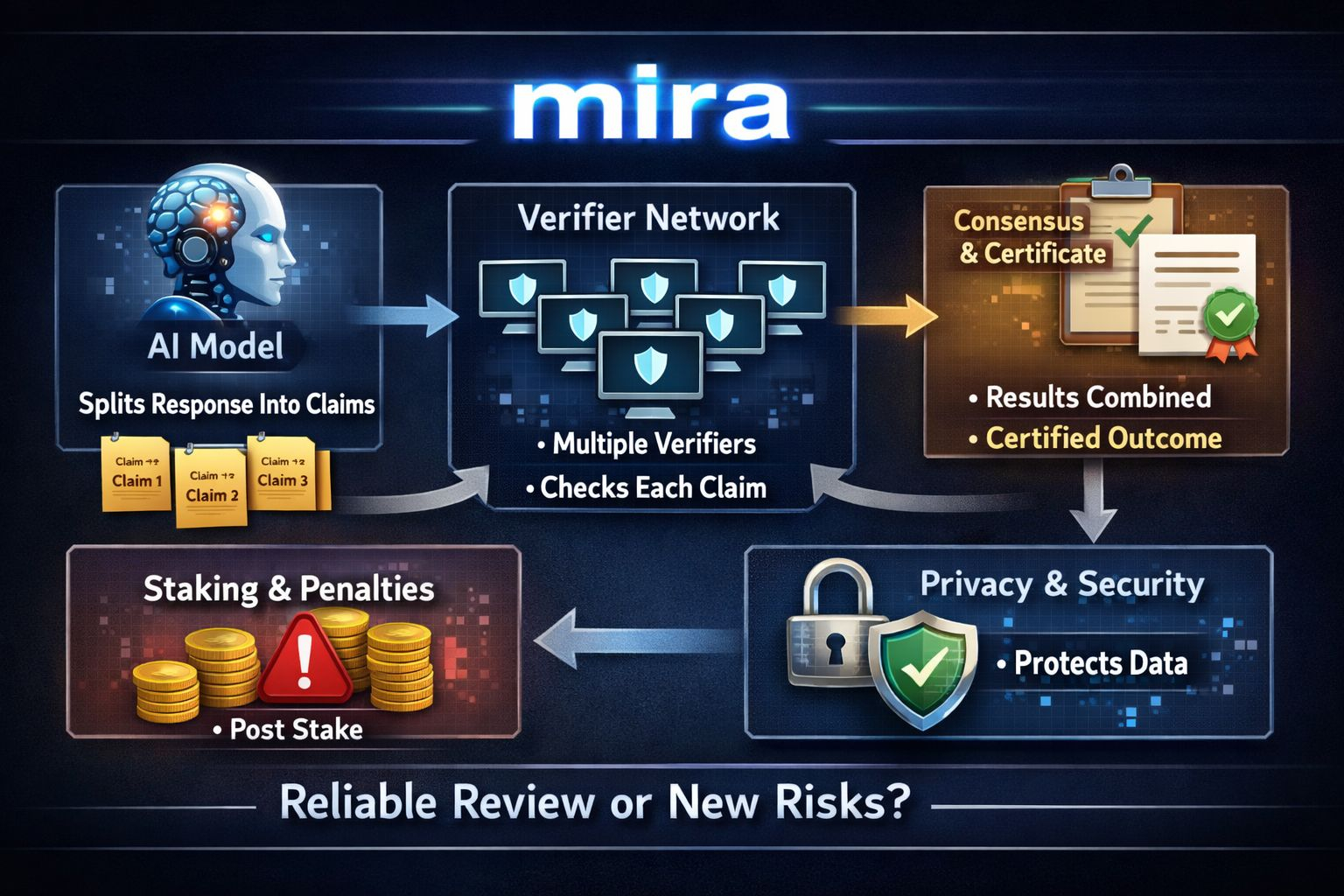
If you trace the process, it begins with an idea that sounds almost obvious: don’t treat a long AI response as one solid block. Take it apart. Mira talks about a step that reshapes the output into smaller claims that can be checked on their own. Those pieces are then sent out to different verifier nodes, each running its own model to decide whether a claim stands. After that, the network pulls the judgments together, reaches a decision, and issues a certificate that logs the outcome.
This is the point where the concept starts to feel both compelling and delicate at the same time.
It’s compelling because the real damage from hallucinations isn’t just that a model slips up now and then. It’s that the mistake sounds just as assured as everything it gets right. When you break an answer into separate claims, you create points you can grab onto. Doubt stops being a vague feeling and becomes something you can track, record, and challenge if needed.
It’s delicate because the person shaping those claims is also shaping the argument. Anyone who has seen lawyers debate what a sentence truly “states” knows how slippery that can be. A line can be technically accurate and still distort the bigger picture once you pull it out of context. Or it can be sliced so narrowly that verification turns into a checklist of harmless facts, while the real error hides in what’s implied, left out, or subtly reframed.
Mira’s whitepaper quietly acknowledges how sensitive that layer is by explaining that, at least in the early stages, the transformation step is centralized, with decentralization planned over time. It’s an honest detail, and it clarifies where trust actually lives at the start: not entirely in the network, but in the team shaping and updating that transformation logic.
From there, the focus shifts to standardization. Mira makes the case that verification should happen within tight boundaries, often in multiple choice or similarly structured formats, so each verifier is responding to the exact same prompt instead of freely interpreting open ended text in their own way.
From an engineering standpoint, that logic holds up. But it’s also the moment where incentive design steps in, because once you standardize answers, you create room for a new kind of shortcut: educated guessing. Mira even walks through a basic probability example, showing how random success rates drop as you add more options and repeat checks, then leans on the usual enforcement toolset: verifiers post stake, and the protocol can penalize those who act carelessly or dishonestly.
It looks tidy on paper. Out in practice, though, everything hinges on a subtle line that’s notoriously hard to draw: telling apart someone who is sloppy and wrong from someone who disagrees in good faith.
If verifiers split because the subject itself is fuzzy, what do you do with the outliers? Penalize the minority and you risk nudging the whole system toward safe agreement, where models rubber stamp whatever the dominant pattern tends to favor, even if that pattern carries bias. Leave the minority untouched and you create space for coordinated noise or quiet collusion. Mira suggests dividing tasks and studying response patterns to make organized gaming more difficult. That likely raises the bar for manipulation. It doesn’t dissolve the deeper tradeoff.
Then there’s privacy, which sits quietly at the center of all this. Mira calls it fundamental, and the whitepaper outlines an approach where outputs are broken into smaller claim fragments and scattered across verifiers so that no single node can piece together the full original response.
Fair direction, but it’s not some clever illusion that solves everything. In tightly regulated settings, the fact that no single node sees the whole picture might not be enough if any individual node still touches sensitive material. And when you peel away context to protect privacy, you can blunt the verification itself. A lot of model mistakes aren’t simple false statements. They’re accurate facts used in the wrong place, missing caveats, or claims that only look wrong once you see the broader objective behind them.
By now, Mira can be interpreted in two distinct ways. You can see it as a protocol built on a serious conviction. Or you can view it as a working product that happens to speak in protocol terms while carving out a path toward real adoption.
The seed round announcement gives a clearer signal. It didn’t just pitch “verification” as a concept. It highlighted infrastructure and access for developers. In July 2024, Mira revealed a $9 million seed raise led by BITKRAFT Ventures and Framework Ventures, presenting itself as decentralized AI infrastructure rather than a niche experiment.
That context is important. By mid 2024, the space was packed with projects claiming to be the AI chain, the marketplace for models, or the backbone for compute. Mira’s early framing, especially in mainstream funding coverage, leaned more toward helping teams build and ship AI workflows than declaring itself the final referee of truth.
Then the compliance phase kicks in, and the narrative tightens around the token itself. Mira’s MiCA disclosure lays it out plainly: the token is the native asset of the network, required for staking if you want to take part in verification, eligible for staking rewards, and tied to governance inside the ecosystem.
Once listings follow, the abstraction disappears and the numbers take over. Binance’s notice for Mira (MIRA) spells out a maximum supply of 1,000,000,000 tokens and a circulating amount at launch of 191,244,643, roughly 19.12%, along with the relevant network and contract specifics that whitepapers usually leave in the margins.
That’s the point where a protocol built around reliability collides with how markets actually function. In a system secured by staking, neutrality isn’t only about the codebase. It’s shaped by who has enough capital to stake, who is willing to keep funds locked, and how voting influence spreads as time passes.
Unlock schedules quietly become part of the trust equation, whether the team emphasizes them or not. Tokenomist’s dashboard for Mira details how much of the supply is already unlocked and notes a March 2026 release, specifying which allocation bucket will receive the next tranche.
If you’re feeling skeptical, you might argue that in the near term, “decentralized verification” is boxed in by the same force that limits most decentralized systems: concentration of stake and influence. If you’re feeling generous, you could counter that vesting is simply a bridge from early concentration toward broader distribution, and that most networks need that transition period to stay alive long enough to decentralize.
Either way, it isn’t a side detail. It becomes part of the lens outsiders will use when deciding whether the network’s verification results deserve trust, especially once serious, high-stakes use cases begin leaning on it.
Then come the performance claims, which is where the narrative becomes attractive—and where it makes sense to stay cautious rather than get carried away.
Aethir’s announcement about working with Mira presents the collaboration as a way to expand verification capacity and strengthen reliability, built on the premise that distributed compute and distributed checking are natural partners.
Messari’s coverage takes a similar angle, characterizing Mira as a decentralized audit layer for AI results and explaining how its approach—splitting outputs into concrete claims and pushing them through a consensus step—aims to increase credibility before those results ever reach the end user.
Both write-ups are useful, but neither is a detached academic review. Aethir has clear reasons to frame the partnership positively. Messari’s research can be thoughtful, yet it’s still an interpretation, not a peer-reviewed trial. If you actually want to understand what Mira delivers in the real world, you end up looking for something more concrete: which tasks were tested, how samples were selected, what models were used as baselines, how “error” was defined, and in how many cases verification meaningfully altered the result instead of simply tagging it.
Those are the specifics that often lag behind when a project is young and the narrative moves faster than the audit trail. It’s not necessarily a flaw. It’s just the rhythm of this space. Still, that’s exactly why a dose of doubt should sit alongside the excitement.
CoinMarketCap’s listing for Mira offers a different sort of grounding. Instead of vision statements, you get circulating supply data and market stats that place the token inside the wider crypto landscape rather than inside the project’s own narrative.
Step back and a more grounded picture starts to form. Mira’s most realistic entry point may not be lofty verification ideals, but orchestration—serving as the hub where developers coordinate multiple models in one workflow. That’s a clear, immediate problem, and it’s something teams can justify paying for.
Verification then becomes a layer you switch on when the downside of being wrong outweighs the extra time and compute required. It’s not glamorous. It doesn’t make headlines. But that kind of quiet, practical integration is often how tools end up lasting.
Still, everything circles back to the verification promise. That’s where the project either builds real credibility or slowly loses it.
The real measure isn’t whether Mira can polish a performance graph. It’s whether the mechanism survives contact with incentives. Could a group of verifiers quietly align their behavior? Does sharding actually make coordinated manipulation harder once people try to game it? Can slashing target bad actors without penalizing minority views that happen to be right? And does the claim-splitting layer decentralize fast enough to avoid becoming a subtle bottleneck controlled by a few hands?
Then there’s the question no one likes to linger on: what does the system do when verification itself breaks down?
And maybe the hardest question to sit with is this: what if the verification layer itself gets it wrong?
With ordinary software, a mistake shows up as a bug. In a verification network, the failure can look cleaner and more dangerous: a polished certificate endorsing a flawed conclusion. A visible stamp of “checked” that doesn’t stop the error but actually helps it spread, because now it carries documentation.
Mira’s argument is that it can make bad outputs harder to slip into real systems unnoticed by forcing them through a structured process that leaves a trail. The mechanics make sense. The incentive design isn’t exotic. The interface looks practical enough that developers could integrate it without rewriting everything.
What remains unanswered, and probably can’t be resolved by whitepapers alone, is whether those mechanisms hold up under pressure. When incentives collide. When participants act strategically. When ambiguity blurs what counts as correct. Do all those pieces combine into genuine reliability, or do they just produce a more convincing version of plausibility?
That’s where Mira stands right now. It’s an attempt to convert the uneasy thought of “I’m not sure I trust this model” into a formal, stake-backed workflow that can be recorded, priced, and audited. It doesn’t promise to eliminate hallucinations. It’s a wager that accountability can be built into the process, and that enough teams will decide the cost of that structure is worth paying.
@Mira - Trust Layer of AI #Mira $MIRA
