@Mira - Trust Layer of AI #Mira
Per anni, la conversazione attorno all'intelligenza artificiale si è concentrata quasi esclusivamente sulle capacità: modelli più grandi, inferenza più veloce, più dati e risultati sempre più impressionanti che sembrano, almeno in superficie, avvicinarsi al ragionamento umano. Eppure, sotto questo rapido progresso si cela una domanda più silenziosa e difficile che l'industria ha iniziato solo di recente ad affrontare con serietà: come possiamo determinare quando un sistema di intelligenza artificiale è realmente affidabile? Non semplicemente convincente, non solo sicuro, ma affidabile in un modo che istituzioni, mercati e infrastrutture critiche possano dipendere senza esitazione.
La sfida esiste perché i moderni sistemi di intelligenza artificiale non producono conoscenza nel senso tradizionale, ma generano probabilità plasmate da schemi nei loro dati di addestramento. Un modello può sembrare autorevole mentre fabbrica silenziosamente una citazione, fraintende una clausola normativa o combina frammenti di informazioni in qualcosa che appare logico ma poggia su fondamenta instabili. Questi fallimenti raramente appaiono drammatici. Invece, si manifestano come distorsioni sottili che passano inosservate fino a quando le loro conseguenze emergono in rapporti finanziari, riassunti di ricerca o decisioni automatizzate che si basano sull'output del modello come se fosse un fatto verificato.
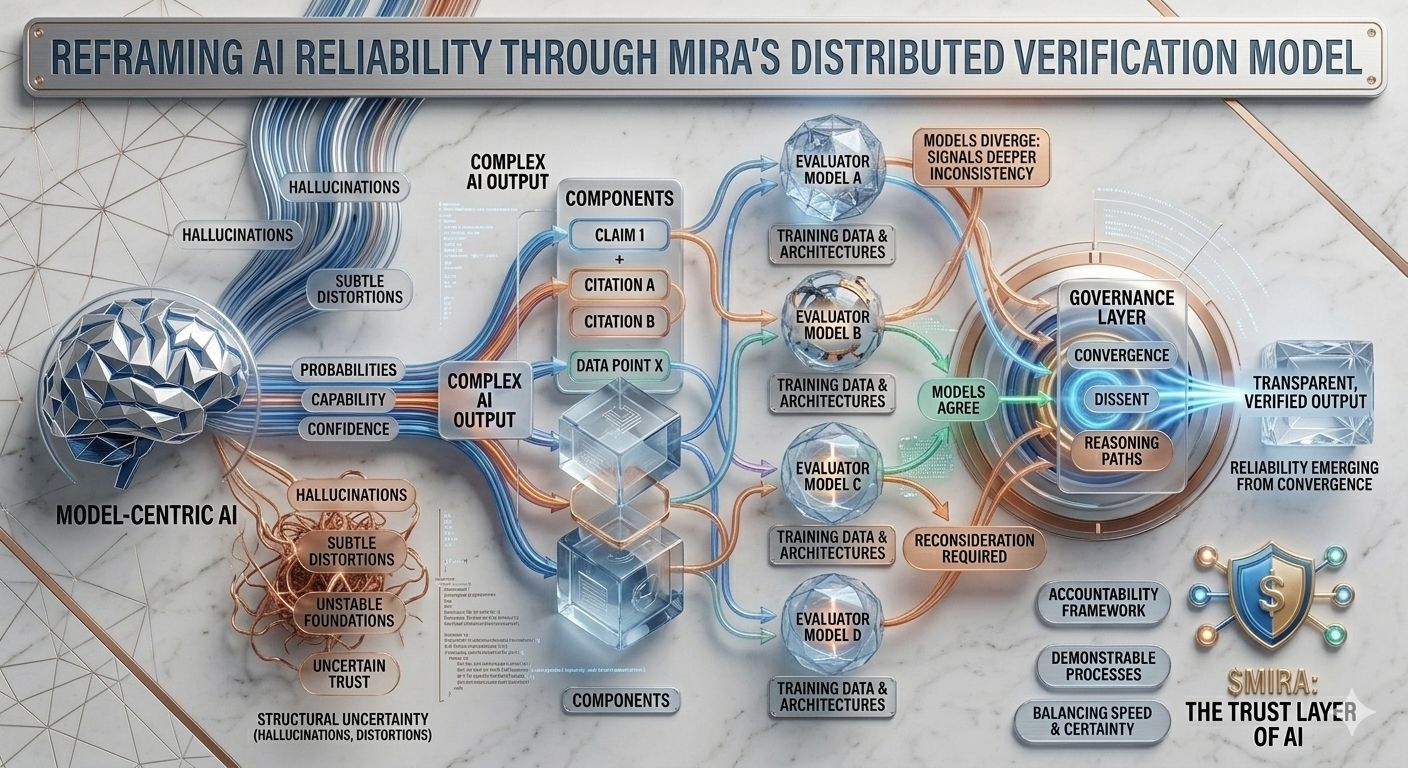
Questa incertezza strutturale è precisamente il problema che Mira cerca di affrontare, non chiedendo perfezione da un singolo modello, ma ripensando l'intero processo attraverso il quale vengono prodotti e validati le risposte dell'IA. Nell'architettura di Mira, un output dell'IA è trattato meno come una conclusione finita e più come un'ipotesi che entra in una pipeline di verifica. Invece di fidarsi del percorso di ragionamento di un modello, il sistema distribuisce la valutazione tra più modelli indipendenti che esaminano la stessa affermazione da diverse prospettive, ciascuna plasmata da diversi corpora di addestramento, architetture e bias interni.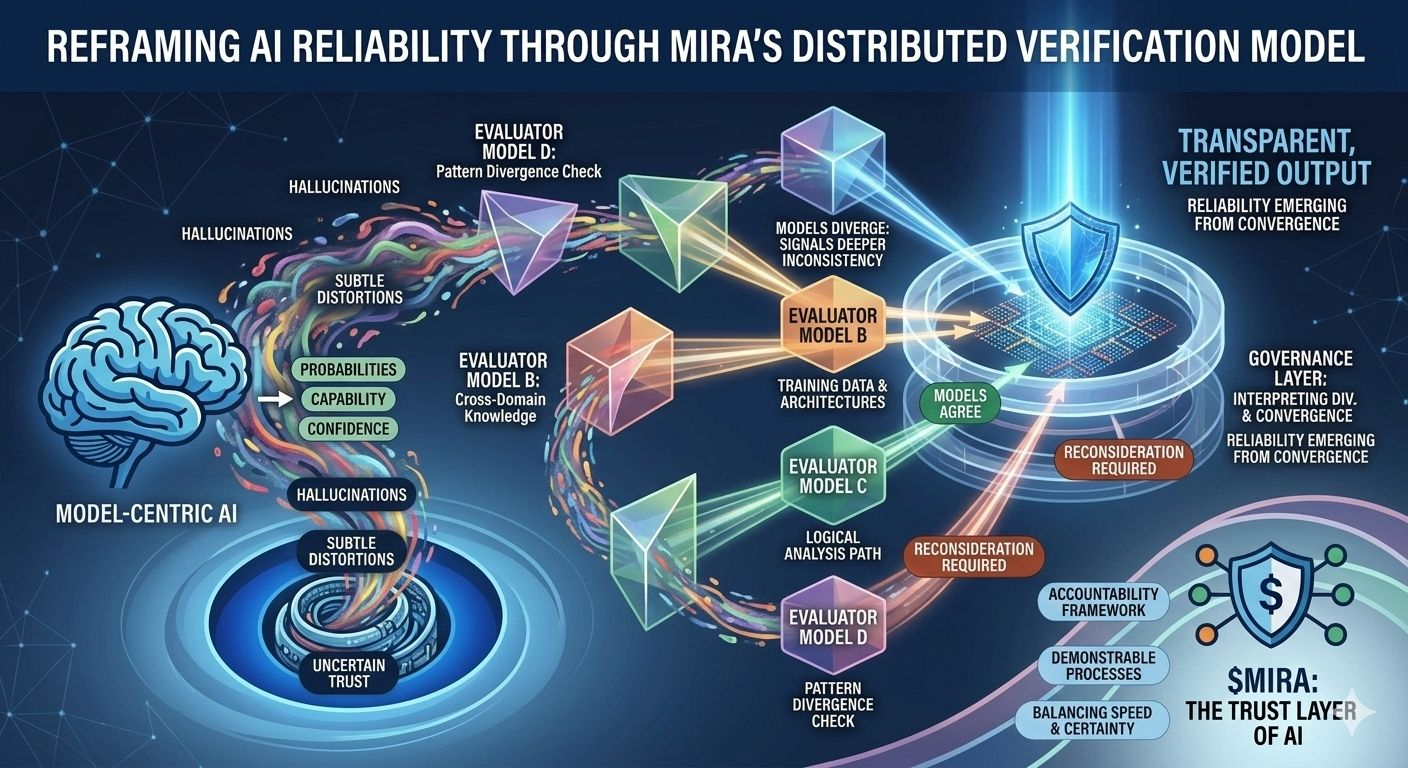
Ciò che rende questo approccio particolarmente interessante è che l'obiettivo non è un accordo cieco tra i modelli. Una semplice votazione di maggioranza offrirebbe solo una rassicurazione superficiale poiché i modelli addestrati su dati sovrapposti spesso ereditano assunzioni e punti ciechi simili. Il framework di governance di Mira si concentra invece sull'interpretazione di come i modelli concordano, dove divergono e se il disaccordo segnala un'incoerenza più profonda all'interno dell'affermazione stessa. In altre parole, l'affidabilità emerge non da risposte uniformi, ma dall'esame strutturato delle differenze nel ragionamento.
Per rendere ciò possibile, gli output complessi dell'IA devono prima essere suddivisi in componenti più piccoli e verificabili. Un riassunto di ricerca generato diventa una serie di affermazioni tracciabili, un spiegazione legale si trasforma in una sequenza di affermazioni interpretative, un'analisi finanziaria si separa in affermazioni quantitabili che possono essere verificate indipendentemente. Ognuno di questi frammenti può poi essere valutato da modelli separati, consentendo al sistema di mappare non solo se la risposta complessiva appare corretta, ma quali elementi specifici resistono all'analisi e quali richiedono una revisione.
Questo cambiamento può sembrare sottile, eppure rappresenta un cambiamento profondo in cui risiede la fiducia all'interno di un sistema di IA. Le pipeline tradizionali concentrano l'autorità all'interno del modello stesso: se il modello funziona bene, il sistema funziona bene; se fallisce, l'intero processo collassa. Mira distribuisce quella responsabilità attraverso uno strato di governance che valuta le affermazioni prima che si solidifichino in output. In questo ambiente, la credibilità non origina da un punteggio di fiducia di un modello, ma dalla convergenza di percorsi di ragionamento valutati indipendentemente.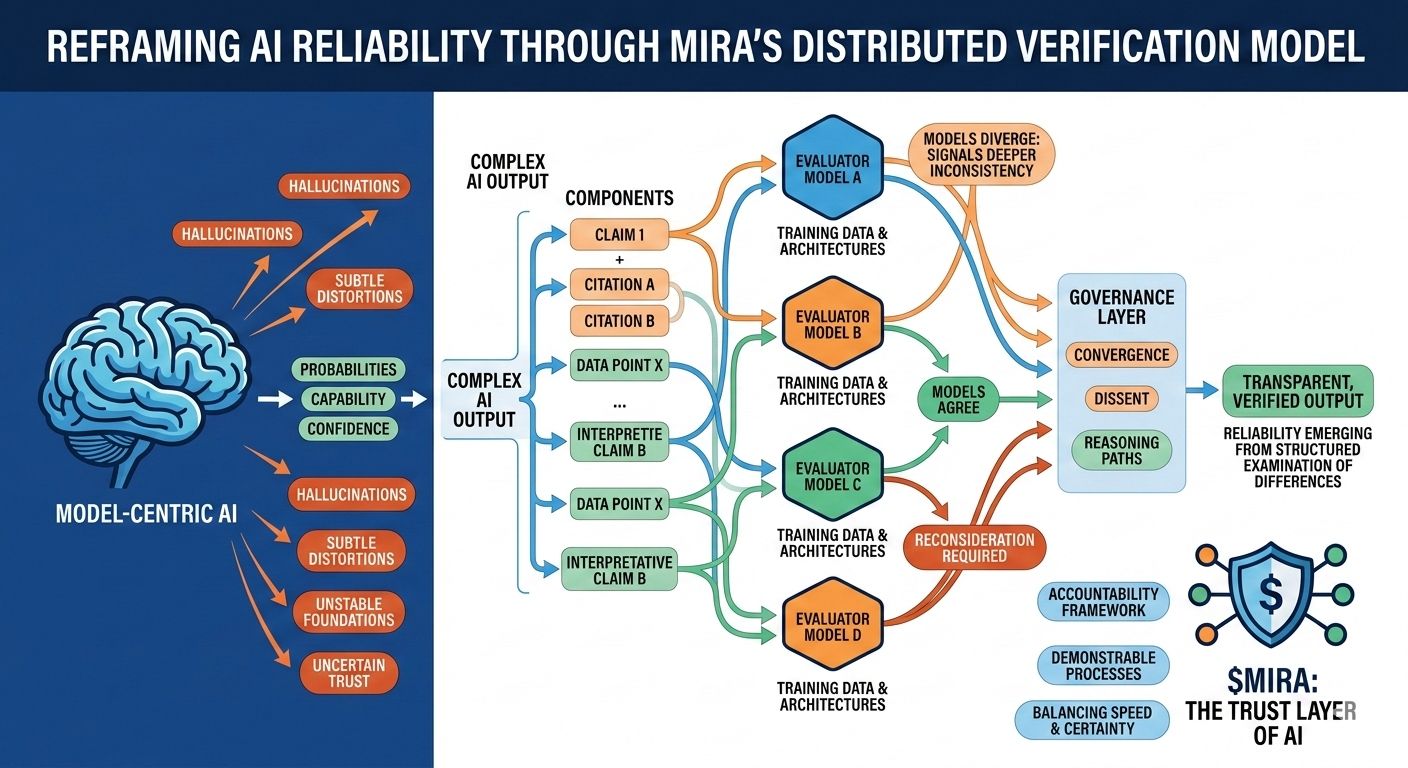
Naturalmente, distribuire la verifica non elimina ogni forma di errore. I modelli addestrati su dataset simili possono comunque riprodurre informazioni obsolete e prompt avversari sofisticati possono sfruttare debolezze sistemiche condivise tra le architetture. Il consenso multi-modello riduce la probabilità di allucinazioni casuali, ma non può prevenire completamente errori coordinati che emergono da assunzioni condivise incorporate nell'ecosistema più ampio dell'IA. Per questo motivo, la trasparenza diventa essenziale quanto la verifica stessa. Gli utenti devono capire se i modelli di verifica rappresentano veramente prospettive indipendenti o semplicemente variazioni dello stesso sistema sottostante.
Un'altra dimensione di questo design risiede nelle sue implicazioni economiche. La verifica non è gratuita: ogni chiamata aggiuntiva al modello introduce costi computazionali, latenza e complessità infrastrutturale. Man mano che i sistemi di IA integrano sempre più strati di verifica, gli sviluppatori devono fare scelte deliberate su quando una validazione profonda è necessaria e quando risposte rapide sono sufficienti. Le applicazioni costruite su IA verificata quindi evolvono in gestori di affidabilità, bilanciando costantemente velocità, costo e certezza, mentre determinano quali output richiedono un'analisi più profonda o supervisione umana.
Questi compromessi probabilmente rimodelleranno il modo in cui le piattaforme di IA competono negli anni a venire. La capacità da sola non definirà più i sistemi più forti. Invece, la capacità di dimostrare processi di verifica trasparenti, comunicare chiaramente l'incertezza e rivelare con grazia il disaccordo tra i modelli potrebbe diventare le caratteristiche distintive di un'infrastruttura di IA affidabile. I sistemi che riconoscono le loro limitazioni pur contenendo sistematicamente gli errori si dimostreranno infine più preziosi di quelli che semplicemente proiettano fiducia.
Visto da questa prospettiva, il modello di Mira è meno incentrato sulla costruzione di modelli individuali più intelligenti e più sulla costruzione di un framework di responsabilità attorno all'intelligenza artificiale stessa. Le risposte dell'IA diventano proposte piuttosto che dichiarazioni: affermazioni che devono passare attraverso una rete di valutatori indipendenti prima di essere accettate come output credibili. In un tale sistema, gli errori rimangono inevitabili, ma il loro impatto è contenuto attraverso meccanismi di verifica che identificano le debolezze prima che si propaghino in decisioni, sistemi finanziari o discorsi pubblici.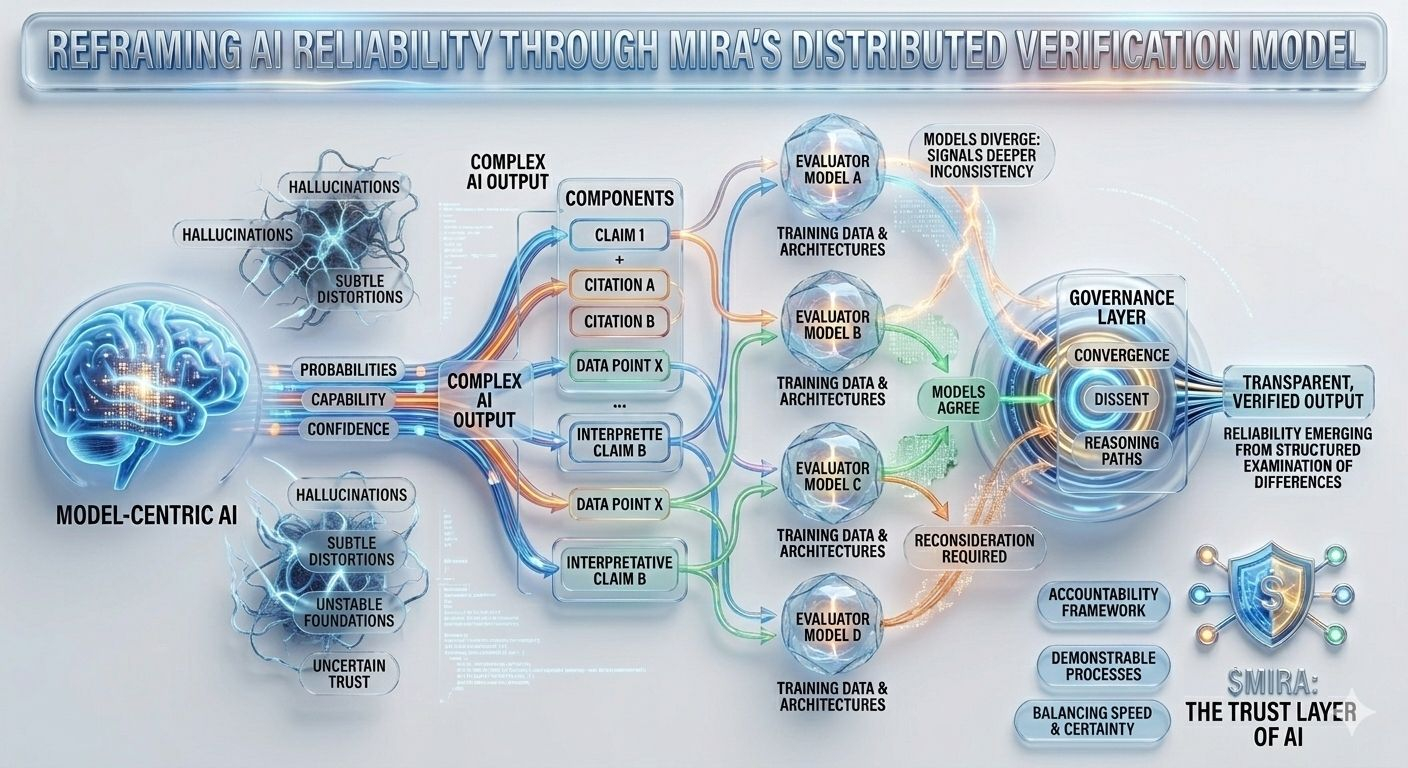
In definitiva, il futuro dell'IA affidabile potrebbe dipendere meno dal raggiungimento di un accordo perfetto tra i modelli e più dalla definizione di come quell'accordo viene interpretato, come vengono analizzati i segnali dissenzienti e quali salvaguardie si attivano quando il consenso inizia a fratturarsi. La vera misura della fiducia non sarà se le macchine producono sempre la risposta giusta, ma se i sistemi che le circondano sono progettati per mettere in discussione, testare e convalidare quelle risposte prima che il mondo si fidi di esse.
$MIRA
