Quando le persone parlano della gestione del rischio dell'IA, la conversazione solitamente salta subito alla regolamentazione o all'allineamento dei modelli. La mia prima reazione è diversa. Il vero problema spesso non è se i sistemi di IA possano essere guidati da regole, ma se i loro risultati possano essere fidati in primo luogo. La maggior parte dei moderni sistemi di IA produce risposte rapidamente e in modo convincente, eppure l'affidabilità sottostante rimane incerta. Quel divario tra fiducia e correttezza è dove inizia il vero rischio.
Il problema non è nuovo. Chiunque abbia lavorato con grandi modelli di IA ha visto quanto facilmente possano produrre informazioni incorrette pur suonando autorevoli. Questi errori vengono solitamente descritti come allucinazioni, ma da una prospettiva di rischio rappresentano qualcosa di più serio: decisioni non verificabili che entrano nei flussi di lavoro reali. Quando i risultati dell'IA influenzano la finanza, la sanità, la governance o le infrastrutture, il costo dell'incertezza cresce rapidamente.
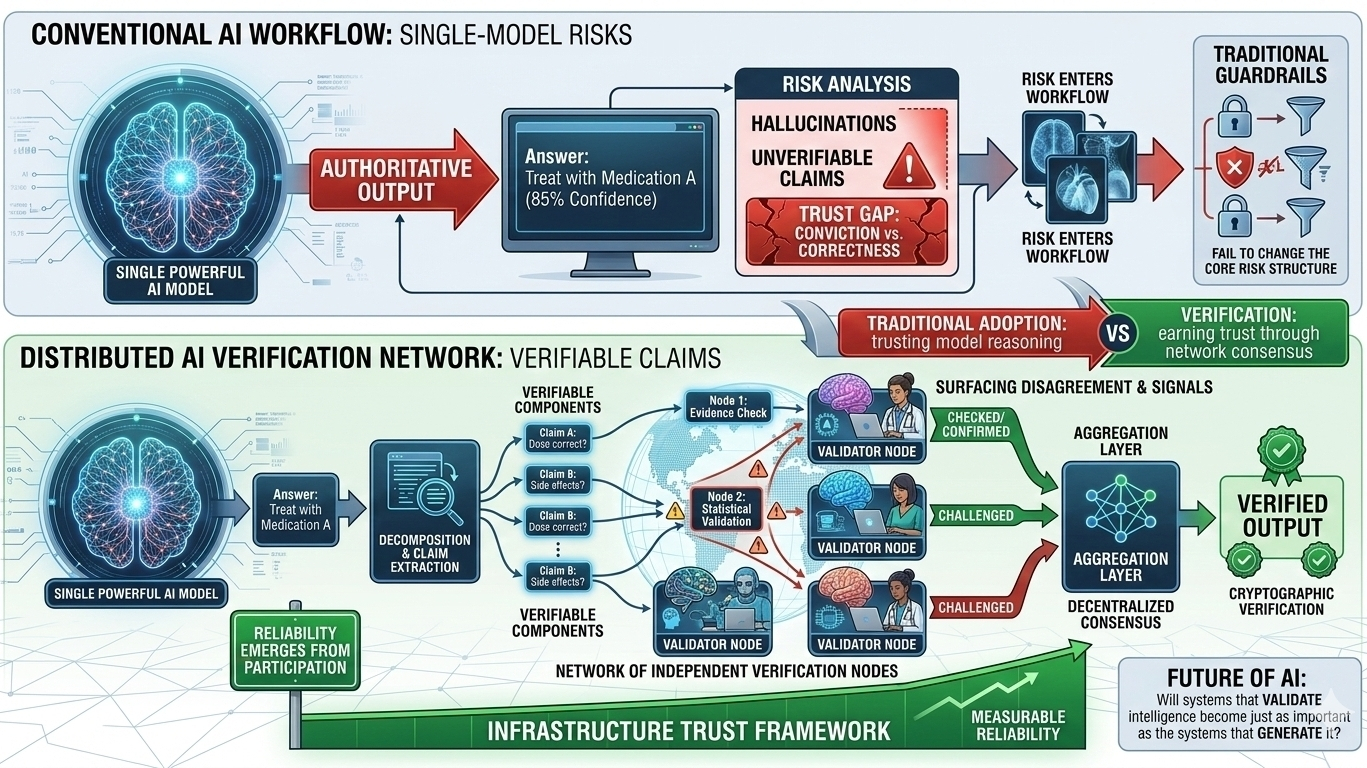
Gli approcci tradizionali per gestire questo rischio di solito si concentrano sul miglioramento del modello stesso. Gli sviluppatori aggiungono guardrail, riaddestrano modelli su dataset curati o costruiscono sistemi di monitoraggio per rilevare comportamenti problematici. Questi sforzi aiutano, ma dipendono ancora pesantemente dalla fiducia nel processo di ragionamento di un singolo modello. Quando lo stesso sistema che genera una risposta è anche responsabile della convalida, la struttura del rischio non cambia davvero.
Questo è il punto in cui l'architettura dietro la Mira Network inizia a spostare la conversazione. Invece di chiedere a un modello di generare e valutare informazioni, il protocollo suddivide le uscite dell'IA in affermazioni più piccole che possono essere verificate indipendentemente attraverso una rete distribuita di modelli. Ogni affermazione diventa qualcosa che può essere controllato, contestato o confermato attraverso un consenso decentralizzato piuttosto che accettato a valore nominale.
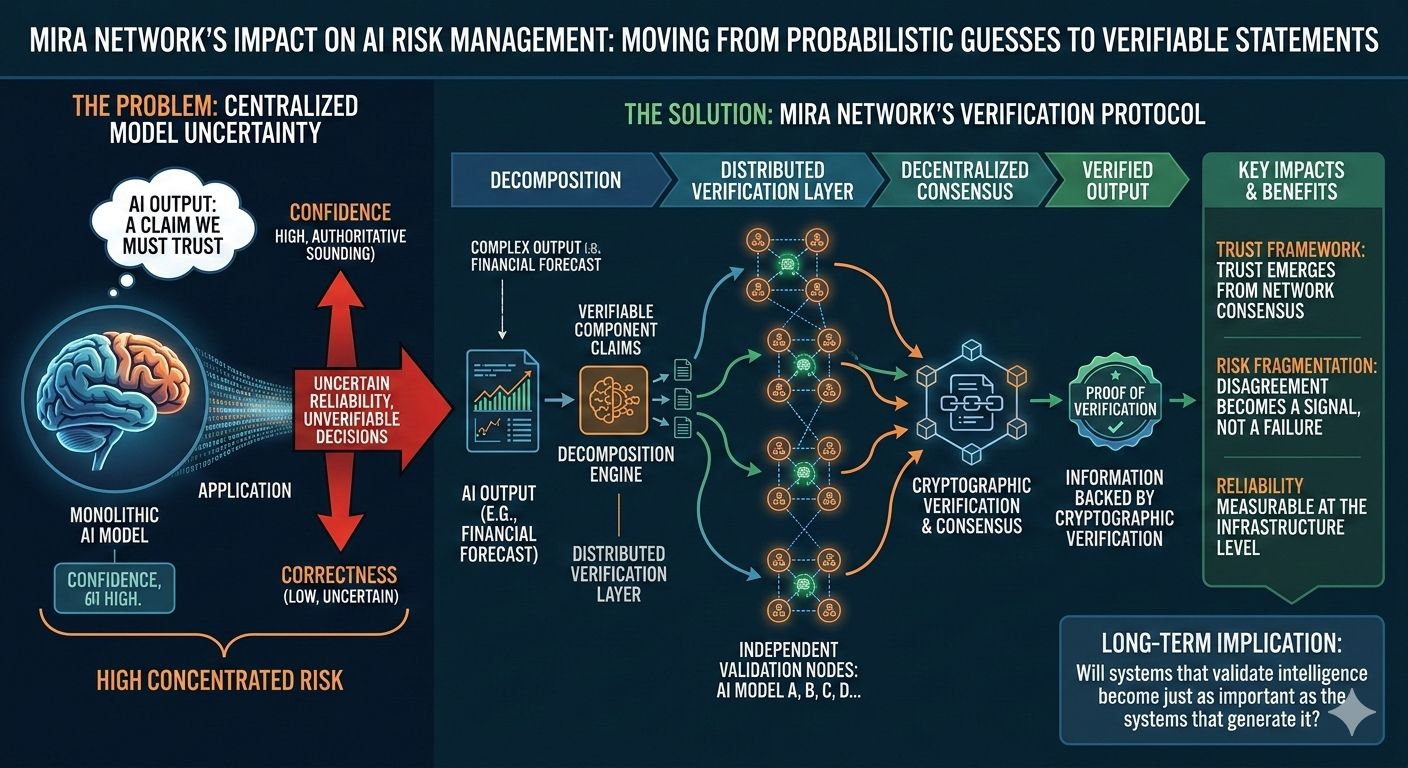
La meccanica dietro questo è sottile ma importante. Quando un sistema di IA produce una risposta complessa, essa viene scomposta in componenti verificabili. Quei componenti vengono quindi distribuiti su più nodi di verifica indipendenti. Ogni nodo valuta l'affermazione utilizzando il proprio processo di ragionamento e la rete aggrega quelle valutazioni in un risultato di consenso. L'output finale non è solo una risposta, diventa un pezzo di informazione supportato da verifica crittografica.
Questo cambiamento modifica il modo in cui il rischio è distribuito nel sistema. Negli architetture di IA convenzionali, il rischio principale risiede all'interno dello strato di output di un singolo modello. Se quel modello è errato, l'errore si trasferisce direttamente all'applicazione. In una rete di verifica, il rischio è frammentato. Le singole affermazioni possono essere messe in discussione da più valutatori e il disaccordo diventa un segnale piuttosto che un fallimento. Invece di nascondere l'incertezza, il sistema la mette in evidenza.
La parte interessante è come questo inizia a rimodellare gli incentivi intorno all'affidabilità dell'IA. In un modello centralizzato, i miglioramenti di accuratezza della pipeline dipendono principalmente dall'organizzazione che addestra il modello. In uno strato di verifica decentralizzato, l'affidabilità emerge dalla partecipazione alla rete. Validator indipendenti contribuiscono al processo di valutazione e il consenso determina quali affermazioni vengono accettate. La fiducia diventa una proprietà della rete piuttosto che una promessa di un singolo fornitore.
Certo, introdurre uno strato di verifica non elimina la complessità. Crea nuove considerazioni operative. La velocità di verifica, gli incentivi per i validatori e i meccanismi di risoluzione delle controversie diventano tutti fattori importanti per mantenere l'affidabilità del sistema. Se la verifica diventa lenta o economicamente inefficiente, l'esperienza dell'utente ne risente. Se gli incentivi sono mal progettati, i validatori potrebbero dare priorità a controlli facili piuttosto che a quelli significativi.
Ma anche con queste sfide, la direzione è notevole perché cambia da dove proviene la fiducia. Invece di fidarsi del fatto che un potente modello di IA "probabilmente ha fatto la cosa giusta", il sistema chiede a più valutatori indipendenti di confermare l'affermazione. Questa distinzione potrebbe sembrare sottile, ma trasforma le uscite dell'IA da congetture probabilistiche in dichiarazioni verificabili.
Un'altra implicazione è come questo influisca sulla relazione tra gli sviluppatori di IA e le applicazioni che dipendono da loro. Nell'attuale panorama, le applicazioni dipendono fortemente da quale fornitore di modelli integrano. Se quel fornitore cambia comportamento o introduce errori, i sistemi a valle ereditano immediatamente le conseguenze. Uno strato di verifica separa generazione da validazione, consentendo alle applicazioni di fare affidamento su informazioni confermate in modo indipendente piuttosto che su output grezzi del modello.
Questo inizia a spostare l'infrastruttura dell'IA più vicino a qualcosa che somiglia ai framework di fiducia visti nei sistemi distribuiti. L'informazione diventa più forte quando sopravvive a più cicli di verifica piuttosto che quando proviene da una singola fonte potente. Il risultato non è una certezza perfetta, ma un quadro molto più chiaro di quali uscite siano sufficientemente affidabili per decisioni nel mondo reale.
Da una prospettiva di gestione del rischio, il risultato più significativo potrebbe essere culturale piuttosto che tecnico. I sistemi di IA sono spesso trattati come strumenti autoritativi perché generano risposte rapidamente e con fiducia. Le reti di verifica sfidano questa assunzione trasformando ogni risposta in un'affermazione che deve guadagnare fiducia attraverso il consenso.
Quindi l'impatto reale non è semplicemente che le uscite dell'IA possano essere controllate. Il cambiamento più profondo è che l'affidabilità diventa misurabile a livello di infrastruttura. Invece di chiedere se un modello sia generalmente accurato, gli sviluppatori possono chiedere se una specifica affermazione è stata verificata in modo indipendente.
E questo solleva una domanda a lungo termine più interessante: se le uscite dell'IA richiedono sempre più strati di verifica per essere affidabili, i sistemi che convalidano l'intelligenza diventeranno altrettanto importanti quanto i sistemi che la generano?
@Mira - Trust Layer of AI #Mira

