I’ve spent enough time watching identity systems, payment rails, and crypto projects collide to know one thing: nothing breaks where people expect it to. It doesn’t fail in the clean diagrams or in the “happy path” demos. It fails in the in-between moments, when one system hands something off to another and both assume the other side has things under control. That gap is where most of the real problems live.
So when I look at something like a global infrastructure for credential verification and token distribution, I don’t start with what it promises. I start with where it’s likely to crack.
At a high level, the idea sounds almost boring in a good way. A credential gets issued once, it can be verified anywhere, and it unlocks access or value without repeating the same checks over and over. Tokens move through the same network, tied to those credentials, making distribution more direct and less dependent on layers of intermediaries. It’s the kind of system that, if it works, fades into the background. Like electricity. You don’t think about it unless it stops.
But the moment you stretch that system across borders, institutions, and real users, it stops being simple. Credentials aren’t just data. They’re claims. And claims always carry risk.
Who issued it? Under what rules? Can it be revoked? What happens if it’s wrong?
In a controlled environment, those questions have clean answers. In the real world, they don’t. Different issuers have different standards. Some are strict, some are sloppy, some are just trying to move fast and fix things later. Verifiers, on the other side, have their own incentives. They want speed, low cost, and minimal liability. If something goes wrong, they don’t want to be the one holding the bag.
That tension doesn’t disappear just because you put a shared infrastructure in the middle. If anything, it becomes more visible.
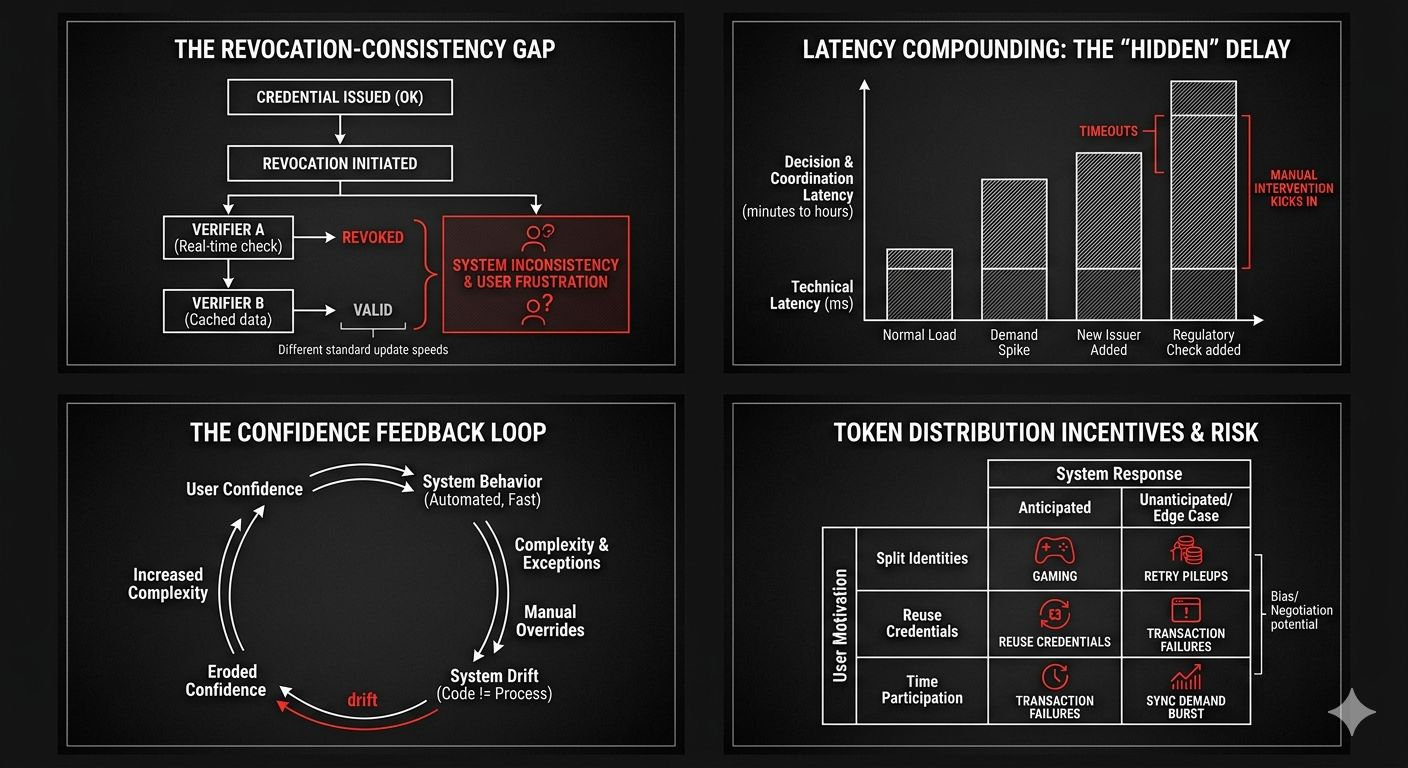
I’ve seen systems where everything works fine until revocation enters the picture. Issuing a credential is easy. Updating it is manageable. Revoking it cleanly across a distributed network? That’s where things slow down. Some verifiers check revocation status in real time. Others cache data to reduce latency. Now you’ve got inconsistency. One part of the network thinks a credential is valid, another part doesn’t. Neither is technically wrong. But from the user’s perspective, it feels broken.
And users don’t care about the nuance. They care that something worked yesterday and doesn’t work today.
Latency plays a bigger role here than most people admit. Not just technical latency, but decision latency. Even if the system responds quickly, the coordination between parties often doesn’t. If a verifier has to double-check something, or if a fallback process kicks in, the delay compounds. In isolation, each delay is small. In sequence, they stack up into something noticeable.
I’ve watched this happen in systems that were “fast enough” under normal load. Then demand spikes, or a new issuer joins, or a regulatory check gets added, and suddenly the timing assumptions don’t hold. Queues form. Timeouts happen. Operators step in manually. And once manual intervention becomes common, the system starts drifting away from its original design.
Token distribution has its own version of this problem. On paper, it’s clean. Define the rules, attach them to credentials, distribute tokens automatically. No bias, no negotiation, just execution.
In reality, distribution is where incentives get sharp.
If tokens have value, people will try to qualify for them in ways the system didn’t anticipate. They’ll split identities, reuse credentials, or time their participation to maximize allocation. None of this is surprising. It’s basic behavior. But it means the system has to constantly deal with edge cases that weren’t part of the original design.
And then there’s timing. Distribution events tend to create bursts of activity. Everyone shows up at once, either to claim something or to move it. That kind of synchronized demand is hard to handle. Even well-built systems struggle when everything hits at the same moment.
I’ve seen queues stretch, transactions fail, retries pile up. Each retry adds more load, which slows things further, which triggers more retries. It’s a feedback loop. Not catastrophic, but messy enough to erode confidence.
Confidence is a quiet dependency in all of this. You don’t notice it when it’s there. You definitely notice when it’s not.
A global infrastructure like this depends on multiple layers of trust. Trust in issuers, trust in the network, trust in the verification process, and trust that the rules won’t change unpredictably. None of these are absolute. They’re negotiated over time, shaped by experience.
If one layer weakens, the others have to compensate. If they can’t, the system starts to fragment. Some participants tighten their requirements. Others loosen them to stay competitive. Interoperability, which was the original goal, becomes conditional.
That’s why design choices matter, but not in the way they’re usually presented. It’s not about finding the perfect architecture. It’s about managing trade-offs.
Centralization makes coordination easier but creates single points of failure and control. Decentralization reduces reliance on any one party but increases complexity and latency. Real systems sit somewhere in between, whether they admit it or not.
I tend to trust systems that acknowledge this openly. Ones that separate responsibilities instead of trying to do everything in one layer. Issuers issue. Verifiers verify. The network moves proofs and value but doesn’t try to interpret everything itself. That kind of separation doesn’t eliminate problems, but it limits how far they spread.
Observability is another piece that often gets overlooked. When something goes wrong, can operators see what happened? Can they trace a credential from issuance to verification to revocation? Can they identify where delays or inconsistencies are coming from?
Without that visibility, debugging turns into guesswork. And guesswork, under pressure, leads to bad decisions.
Governance sits on top of all this, whether people like it or not. Rules need to exist for disputes, updates, and exceptions. Who can revoke a credential? Under what conditions? How quickly? What evidence is required?
These aren’t technical questions, but they shape the system just as much as the code does.
I’ve seen technically solid systems stall because governance wasn’t clear. No one wanted to take responsibility in a gray area, so nothing happened. Or worse, multiple parties acted independently and made things inconsistent.
There are also limits that no design can get around. This kind of infrastructure can reduce fraud, but it can’t eliminate it. It can make verification easier, but it can’t guarantee correctness. It can streamline distribution, but it can’t stop people from trying to game the rules.
And it definitely can’t resolve the deeper issues around identity and jurisdiction. Different regions will always have different standards, different legal frameworks, different expectations. A global system has to operate across those differences, not erase them.
I think of it less like a single system and more like a network of agreements. The technology provides the rails, but the behavior on those rails is shaped by the participants.
What makes this interesting, at least to me, is not the promise of perfection. It’s the attempt to build something that holds together when conditions aren’t ideal. When latency increases, when trust is partial, when incentives aren’t aligned.
Most systems look fine when everything is calm. The real test is when things get uneven.
If this kind of infrastructure can handle that unevenness—if it can degrade gracefully instead of failing abruptly—that’s already meaningful progress. Not a solution to everything. Just a system that behaves predictably when the environment doesn’t.
And honestly, that’s a higher bar than it sounds.
@SignOfficial $SIGN #SignDigitalSovereignInfra
