
Il punto di partenza per questo articolo è molto semplice: spiegare come comprendo la metodologia della rete Pyth in modo chiaro e riutilizzabile; allo stesso tempo, metterla in un contesto più ampio dell'industria dei dati di mercato e delle applicazioni a livello istituzionale. Negli ultimi anni, ho seguito a lungo l'evoluzione degli oracle e la commercializzazione dei dati, formando gradualmente un giudizio semplice ma utile: ciò che è veramente importante nella catena di approvvigionamento dei dati non è il “decentramento” decorativo, ma la produzione affidabile e la consegna verificabile. Quando offerta e domanda possono stringere la mano direttamente sulla blockchain in modo verificabile, il valore è più facilmente catturato in modo stabile.
Per me, Pyth non è "un altro componente di prezzo", ma una catena di produzione di dati sui prezzi che va dalla produzione alla distribuzione multi-chain. Il modello tradizionale è più simile a un "distributore di informazioni", dove aggregatori, raccoglitori e nodi intermedi inoltrano i dati; ritardi, incertezze e mancanza di tracciabilità spesso diventano un terreno fertile per rischi sistemici. Pyth adotta un modello di dati di prima parte, permettendo a borse, market maker e fornitori di dati professionali di firmare e pubblicare direttamente sulla blockchain; quindi aggrega, verifica e calcola gli intervalli di confidenza attraverso Pythnet, distribuendoli a prestiti, opzioni, asset sintetici, indici e altre applicazioni in modo su richiesta. Riassumo questo percorso come: non fare da amplificatore, ma costruire una "linea di produzione di prezzi verificabili".
Uno, il tetto del mercato e le esigenze reali.
Il valore dell'industria dei dati di mercato proviene da entrambe le estremità: da un lato, la qualità e la tempestività della fonte, dall'altro, l'utilizzabilità e la sensibilità ai costi dei consumatori. Nel settore finanziario tradizionale, la distribuzione dei dati e i prezzi in tempo reale sono categorie di pagamento stabili a lungo termine; trasferendosi nel mondo delle criptovalute, la domanda non è cambiata, ma sono aumentate le richieste di "verificabilità" e "programmabilità". Le strategie di prestito e liquidazione richiedono aggiornamenti a bassa latenza e stabili; la valutazione delle opzioni dipende da stime ragionevoli della volatilità; gli asset sintetici richiedono coerenza nella valutazione in condizioni di alta volatilità. Queste esigenze essenziali hanno generato una domanda continua per prezzi di alta qualità, ed è anche la mia motivazione fondamentale per continuare a investire nella ricerca e nella creazione. La visione di Pyth, partendo da DeFi, si dirige verso un mercato di servizi di dati più ampio; credo che sia un percorso "difficile ma corretto".
Due, operabilità dei prodotti e scomposizione dell'architettura.
Abituo a suddividere qualsiasi prodotto di dati in cinque segmenti: produzione grezza, pubblicazione affidabile, verifica di aggregazione, distribuzione e regolamento, feedback e ottimizzazione. In Pyth, la produzione grezza proviene da borse, market maker e fornitori di dati professionali di prima linea; questi operano come "publisher" sulla blockchain, ogni messaggio porta una firma sorgente, il che è una premessa per la tracciabilità. La pubblicazione affidabile si basa su Pythnet, per de-duplicare, pulire, allineare i timestamp e calcolare gli intervalli di confidenza basati su dati multicanale. Dopo la verifica di aggregazione, distribuiamo gli aggiornamenti dei prezzi alle applicazioni su diverse catene attraverso canali cross-chain; il meccanismo di "abbonamento e richiesta" consente agli utilizzatori di decidere la frequenza di attivazione in base ai costi e alle preferenze di tempestività, riducendo le transazioni inutili e il rumore sulla catena. Questa progettazione mette "velocità" e "robustezza" sotto un unico obiettivo ingegneristico. Dalla mia esperienza pratica, gli sviluppatori possono completare l'integrazione senza problemi, a patto di comprendere la struttura dei campi dell'oggetto prezzo, la precisione temporale e gli intervalli di confidenza.
Il diagramma di struttura qui sotto mostra i nodi chiave e i punti verificabili dei dati dalla fonte all'applicazione, facilitando la comunicazione con il team sui dettagli di implementazione e confini.
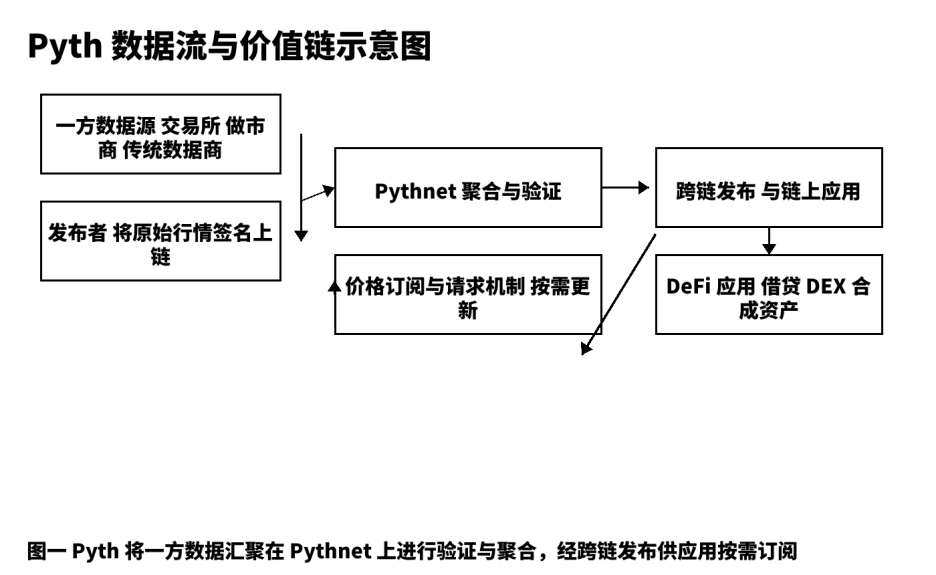
Tre, confronto a cinque dimensioni e scelta strategica.
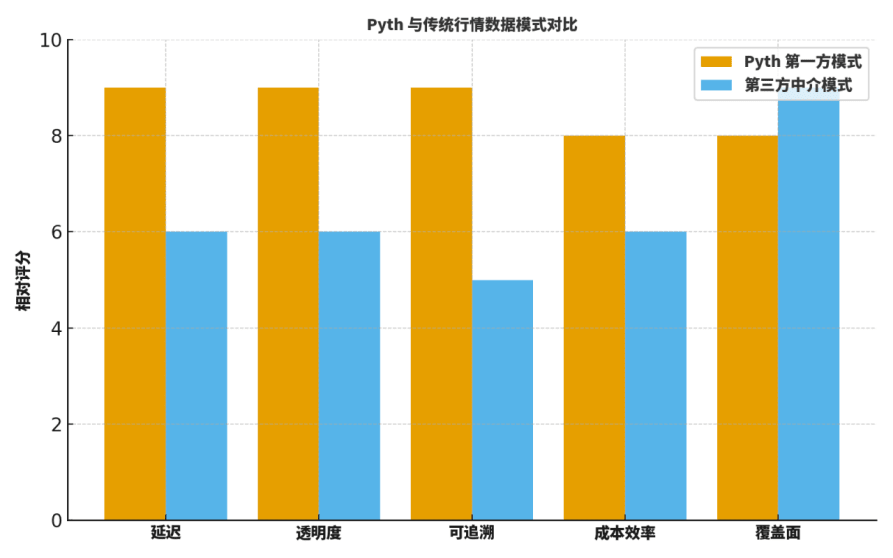
Molti studenti chiedono: quali sono le differenze tra Pyth e i tradizionali "oracoli intermediari" o i fornitori di dati affermati? Di solito confronto su cinque dimensioni: latenza, trasparenza, tracciabilità, efficienza dei costi, copertura.
Primo, in termini di latenza, la trasmissione diretta di prima parte riduce significativamente i passaggi intermedi, risultando in aggiornamenti più rapidi;
Secondo, in termini di trasparenza e tracciabilità, la firma sorgente e il processo di aggregazione verificabile forniscono visibilità a livello di dettaglio;
Terzo, in termini di efficienza dei costi, si eliminano i costi di estrazione esterna e di inoltro multilivello;
Quarto, in termini di copertura, i giganti tradizionali hanno ancora vantaggi nella distribuzione storica e geografica;
Quinto, in termini di collaborazione ingegneristica, l'abbonamento "on-demand" di Pyth è favorevole al coupling con parametri di rischio e sistemi di allerta.
Pertanto, la strategia non è "una soluzione unica", ma si tratta di utilizzare Pyth in scenari chiave: prestiti, liquidazioni, opzioni, asset sintetici, ecc., che considero "mostre" più importanti durante il processo di selezione.
Per aiutare i lettori a costruire un'intuizione, fornisco un grafico di "valutazione relativa"; non è una conclusione assoluta, ma è molto adatto come punto di partenza per discussioni e modelli di riesame.
Quattro, la "seconda fase" nella tabella di marcia: abbonamento ai dati di livello istituzionale.
Nella creazione di contenuti e nella pratica della consulenza, ho diviso la rotta di Pyth in due fasi interconnesse:
La prima fase si concentra sulla creazione di standard di prezzo per scenari DeFi ad alta velocità, con un focus su qualità e velocità;
La seconda fase si orienta verso la productizzazione degli "abbonamenti ai dati di livello istituzionale", che includono: accordi di livello di servizio (SLA) con ritardi, registri di log auditabili, sistemi di etichettatura delle anomalie orientati al rischio, interfacce di fatturazione modulare e riconciliazione.
Questo passo estende la capacità ingegneristica in capacità di servizio: collega i segnali di prezzo con capacità organizzative come regolamentazione, conformità e gestione del rischio; lega realmente "entrate sostenibili" e governance di rete. Sono particolarmente interessato a sapere se i modelli di servizio ripetibili possono funzionare, ad esempio:
(1) fornire piani di abbonamento con diversi livelli di ritardo e frequenze di aggiornamento;
(2) l'origine, la firma, il timestamp e l'elenco dei publisher partecipanti a ogni aggiornamento di prezzo possono essere esportati e tracciati;
(3) etichette anomale orientate al rischio che possono essere riprodotte, riesaminate e correlate a eventi di rischio.
Questi dettagli determinano se un'istituzione è disposta a migrare e quanto è disposta a pagare.
Cinque, utilità dei token e ciclo economico.
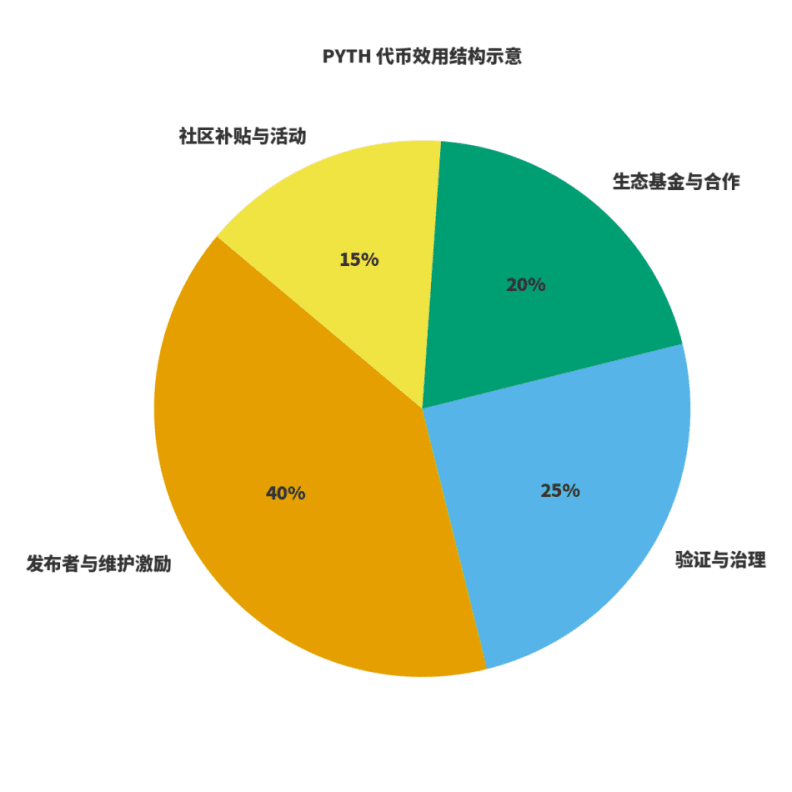
Per valutare se una rete è sana, bisogna considerare due cose: primo, se le entrate sono legate alla creazione di valore; secondo, se gli incentivi sono legati alla qualità a lungo termine. Per $PYTH , lo interpreto come tre ruoli: il carburante per la produzione e manutenzione dei dati; il peso per la governance e la verifica; la leva per l'espansione ecologica. I publisher e i manutentori partecipano attraverso incentivi token previsti; le entrate della rete provengono da abbonamenti e utilizzo dei dati, e la governance distribuisce le entrate tra manutenzione, incentivi ed espansione ecologica. Ho disegnato un diagramma per rappresentare la "distribuzione dell'utilità", le proporzioni specifiche verranno regolate nel tempo con l'evoluzione della governance, ma il principio rimane invariato: pubblicazione e manutenzione hanno un grande peso; governance e verifica garantiscono la stabilità; ecologia e comunità sono responsabili dell'estensione e della rottura delle barriere.
Sei, elenco di implementazione orientato alle istituzioni.
Combinando esperienze passate di integrazione, ho sintetizzato un elenco che può essere utilizzato direttamente:
Primo, chiarire il dominio dei dati e i confini del servizio: quali sono i prezzi di base e quali appartengono al livello di valore aggiunto;
Secondo, allineare gli accordi di livello di servizio: compresi ritardi negli aggiornamenti, stabilità, gestione delle anomalie, strategie di allerta e piani di disaster recovery;
Terzo, fornire pipeline di log auditabili: registrare l'origine di ogni aggiornamento di prezzo, le variazioni degli intervalli di confidenza e le etichette anomale;
Quarto, integrare la gestione interna del rischio e il framework di backtesting: connettere il flusso di prezzo al sistema di replay, testando la stabilità della strategia a diverse soglie e finestre;
Quinto, standardizzare la fatturazione e la riconciliazione: le istituzioni sono più interessate a termini di pagamento prevedibili e dettagli di riconciliazione chiari.
In questo elenco, il vantaggio evidente di Pyth è la verifica "dalla fonte all'aggregazione", che può ridurre significativamente il ciclo di valutazione di conformità e gestione del rischio.
Sette, mappa dei rischi e design antifragile.
Divido i rischi in tre categorie: pubblicazione anomala alla fonte, sincronizzazione anomala cross-chain, amplificazione dei ritardi in condizioni di mercato estreme. Le misure di attenuazione corrispondenti devono essere "istituzionalizzate" nell'ingegneria. Le mie pratiche comuni includono: abbonamenti multipli con verifica delle soglie; riduzione automatica della leva collegata agli intervalli di confidenza; protezione dal tempo e slippage nei contratti di trading; e simulazioni di mercato estremo condotte trimestralmente, accompagnate da script di replay unificati e modelli di riesame. Queste pratiche ingegneristiche disciplinate, unite ai log verificabili di Pyth, possono migliorare significativamente la resilienza del sistema.
Otto, suggerimenti narrativi per creatori di contenuti e sviluppatori.
Continuo a sottolineare: il valore dei creatori è tradurre il valore ingegneristico complesso in un linguaggio "comprensibile e utilizzabile" per lettori e utenti. Se si vuole parlare di Pyth, suggerisco di partire dal "cambiamento di paradigma" piuttosto che fermarsi alla "battaglia degli oracoli". Parlare di come allinea l'offerta e la domanda in modo verificabile sulla blockchain; parlare di come riduce i rischi a lungo termine attraverso intervalli di confidenza e processi di aggregazione visualizzabili; parlare di come, attraverso "abbonamenti di livello istituzionale", collega la capacità di servizio a un ciclo commerciale chiuso. Questo è più persuasivo rispetto a un elenco generico di indicatori.
Nove, gli indicatori che seguirò nel prossimo anno.
Primo, la larghezza e la profondità dell'accesso ecologico: copertura dei principali progetti in quattro categorie: prestiti, asset sintetici, opzioni e indici;
Secondo, il progresso della productizzazione dell'abbonamento istituzionale: i livelli di ritardo, gli accordi di servizio e i log auditabili vengono aggiornati tempestivamente;
Terzo, la trasparenza delle entrate e della distribuzione del protocollo: si forma un calibro di dati verificabili pubblicamente;
Quarto, i progressi di conformità nelle diverse giurisdizioni: incluse la conformità all'esportazione dei dati e la conformità ai servizi finanziari.
Questi indicatori influenzeranno direttamente i miei temi e il ritmo nella parte dei contenuti, e influenzeranno anche la mia valutazione a lungo termine di PYTH.
Dieci, guida per sviluppatori: da zero a uno.
Per aiutare i partner che iniziano a muovere i primi passi, propongo un "metodo in tre passaggi" eseguibile.
Primo passo, completare una chiamata di abbonamento ai prezzi in un ambiente di test; comprendere la struttura dei prezzi, la precisione temporale e i campi degli intervalli di confidenza;
Secondo passo, incorporare la "strategia di abbonamento e richiesta" nei contratti o nei robot di trading, confrontando i risultati di diverse soglie e finestre attraverso un sistema di backtesting;
Terzo passo, attivare il monitoraggio degli allarmi; impostare le soglie di allerta in base agli indicatori di gestione del rischio e includere le etichette anomale nel replay e nel riesame.
Quando hai completato i tre passaggi, non solo hai utilizzato Pyth, ma hai anche implementato il "concetto di dati verificabili" nel codice.
Undici, confronto del settore e spazi di collaborazione.
Non sostengo un pensiero a somma zero di "questo consuma quello". In scenari con una copertura più ampia, ma requisiti di tempestività meno rigorosi, i fornitori di dati tradizionali hanno ancora un vantaggio; mentre in scenari altamente sensibili alla latenza e alla verificabilità, il paradigma di prima parte di Pyth ha più probabilità di successo. In futuro, mi aspetto che gli sviluppatori combinino flussi di dati da diverse fonti in modo modulare, facendo un bilanciamento dinamico tra costi e prestazioni in base alla funzione obiettivo.
@Pyth Network #PythRoadmap $PYTH