
Tôi đã chứng kiến quá nhiều thứ được gọi là “infrastructure” trong crypto. Mỗi giai đoạn lại có một lớp narrative mới nghe hợp lý hơn, gọn gàng hơn và thường là… trông rất cần thiết nhưng rồi khi nhìn kỹ thì nhiều thứ chỉ đang giải quyết những vấn đề mà chính ngành này tự tạo ra.
Indexing là một ví dụ như vậy và Verification cũng vậy. Hai khái niệm nghe có vẻ khác nhau nhưng lại cùng xuất phát từ một điểm: dữ liệu trên blockchain vốn không dễ dùng như chúng ta nghĩ.
Vấn đề cốt lõi ở đây không mới. Blockchain lưu trữ dữ liệu nhưng không được thiết kế để truy vấn một cách hiệu quả. Bạn có thể đọc dữ liệu nhưng để hiểu nó thì cần thêm một lớp xử lý bên ngoài và đó là nơi các hệ thống indexing xuất hiện. Chúng giúp dịch dữ liệu thô thành thứ có thể dùng được. Nghe hợp lý và thực tế, nó đã trở thành một phần gần như mặc định trong stack của rất nhiều ứng dụng.
Nhưng đó cũng là điểm bắt đầu của một vấn đề khác. Khi bạn cần một bên thứ ba để tổ chức lại dữ liệu, bạn bắt đầu tin vào cách họ tổ chức nó. Bạn không còn đọc trực tiếp từ chain nữa mà bạn đọc qua một lớp đã được xử lý, đã được chọn lọc và ở đâu đó, sự “ trustless ” ban đầu bị pha loãng.
Ít nhất theo cái cách mà tôi quan sát được đó là phần lớn người dùng không thực sự quan tâm đến điều này. Họ chỉ cần dữ liệu nhanh, API ổn định và không bị lỗi. Họ không hỏi dữ liệu đó có bị thay đổi không, họ cũng không kiểm tra lại. Điều này tạo ra một vùng xám khá thú vị: chúng ta xây dựng trên blockchain để tránh phải tin tưởng nhưng lại dựa vào các hệ thống trung gian mà chúng ta… tin tưởng theo mặc định.
Đó là phần tôi luôn quay lại.
Các hệ thống indexing như cách chúng ta đang dùng dường như giải quyết một vấn đề UX nhưng lại mở ra một vấn đề về integrity. Không phải theo kiểu có ai đó đang cố gian lận mà là theo kiểu: chúng ta không còn chắc chắn tuyệt đối về dữ liệu nữa nhưng lại hành xử như thể mọi thứ vẫn ổn.
Trong bối cảnh đó có vẻ như một số dự án đang đi theo hướng khác. Không cố làm cho dữ liệu dễ truy vấn hơn mà cố làm cho dữ liệu có thể được kiểm chứng một cách rõ ràng hơn.
The Graph là một ví dụ khá điển hình của hướng đầu tiên. Nó không thay đổi bản chất dữ liệu mà nó chỉ giúp bạn truy cập dữ liệu đó nhanh hơn, có cấu trúc hơn. Nó giống như một lớp dịch vụ nằm trên blockchain. Bạn gửi query, bạn nhận kết quả. Đơn giản, hiệu quả và thực tế là đã được dùng rất nhiều.
Nhưng The Graph không thực sự trả lời câu hỏi: “làm sao tôi biết dữ liệu này là đúng ?” Nó giả định rằng hệ thống indexing hoạt động đúng hoặc ít nhất là đủ đúng.
Ở phía còn lại, SIGN dường như đang cố tiếp cận vấn đề từ góc nhìn khác. Không phải indexing mà là verification. Không phải làm cho dữ liệu dễ đọc hơn mà là làm cho việc xác minh dữ liệu trở nên rõ ràng hơn. Không phải là một lớp truy vấn mà là một lớp chứng thực.
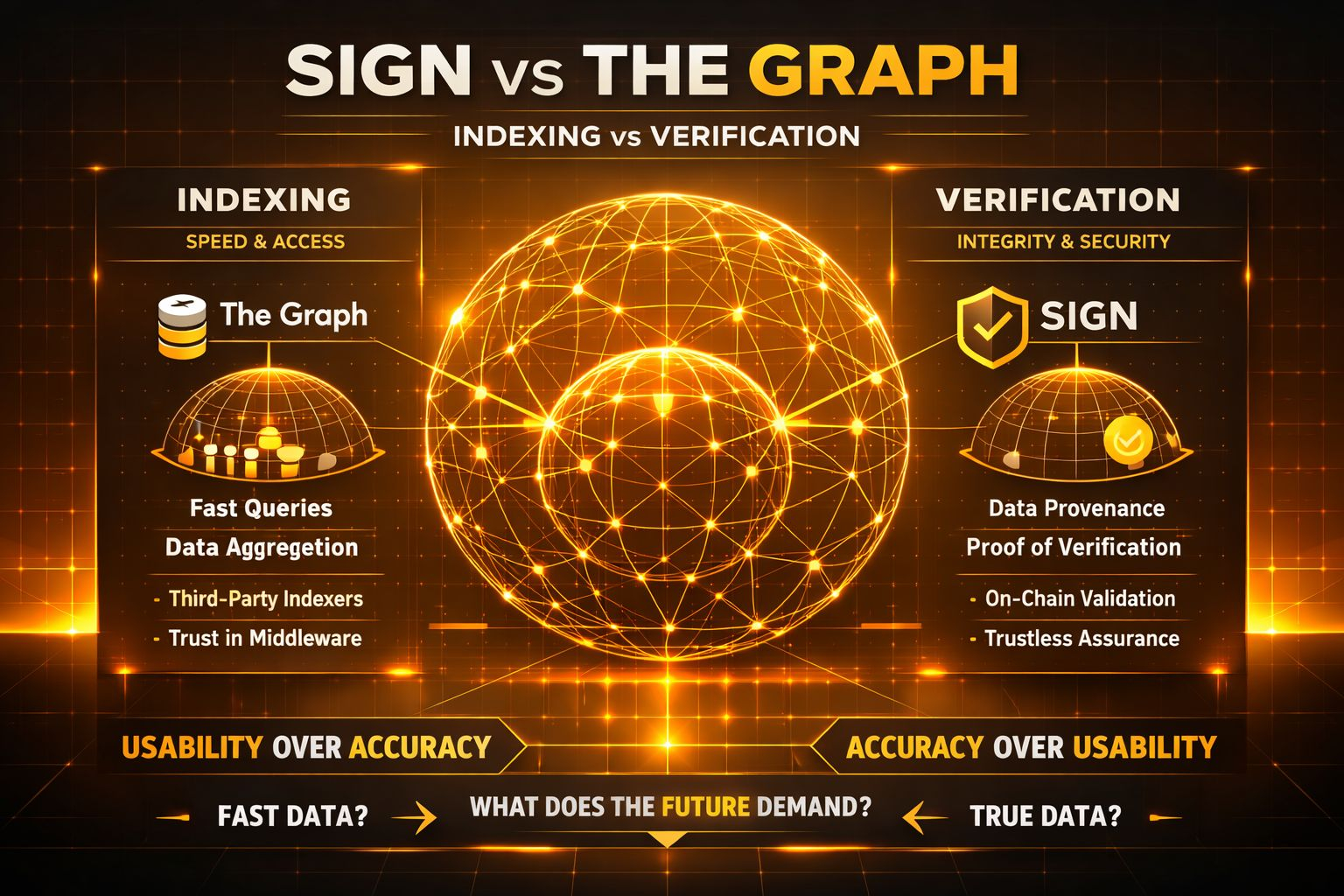
Sự khác biệt này nghe có vẻ nhỏ nhưng lại khá căn bản. Một bên tối ưu cho tốc độ và trải nghiệm, một bên tối ưu cho tính đúng đắn và khả năng kiểm chứng. Một bên giúp bạn dùng dữ liệu còn một bên cố gắng đảm bảo rằng dữ liệu bạn đang dùng là thứ bạn có thể tin mà không cần tin.
Tất nhiên nói thì dễ còn làm được hay không lại là câu chuyện khác.
Thực tế là phần lớn ứng dụng hiện tại không yêu cầu mức độ verification cao như vậy hoặc ít nhất họ chưa cảm thấy cần. Khi mọi thứ vẫn chạy, khi user vẫn không phàn nàn thì việc thêm một lớp verification có thể bị xem là overkill. Nó làm hệ thống phức tạp hơn, chậm hơn và đôi khi là không cần thiết.
Nhưng điều đó chỉ đúng cho đến khi nó không còn đúng nữa.
Khi có lỗi xảy ra, khi có dữ liệu sai, khi có một hệ thống phụ thuộc vào dữ liệu đó và bị ảnh hưởng dây chuyền thì lúc đó câu hỏi về verification mới bắt đầu trở nên quan trọng nhưng lúc đó thì thường đã muộn.
Dường như chúng ta đang ở một giai đoạn mà indexing là đủ tốt, còn verification thì vẫn là một “nice to have” nhưng tôi không chắc điều này sẽ giữ nguyên khi hệ sinh thái trở nên phức tạp hơn khi nhiều hệ thống bắt đầu phụ thuộc lẫn nhau, khi một sai lệch nhỏ có thể lan rộng.
SIGN, ít nhất từ cách tôi nhìn đang đặt cược vào kịch bản đó. Rằng trong tương lai việc “ biết dữ liệu đến từ đâu và có đúng không ” sẽ quan trọng không kém việc “lấy dữ liệu nhanh như thế nào”.
Nhưng đó vẫn chỉ là một giả định.
Whitepaper có thể rất thuyết phục, narrative có thể rất hợp lý nhưng cuối cùng mọi thứ vẫn quay về usage. Có ai thực sự cần điều này không, có ai sẵn sàng đánh đổi performance để lấy verification không ? Hay họ chỉ nói rằng họ cần nhưng khi build thì lại chọn cách nhanh hơn, đơn giản hơn ?
Tôi chưa có câu trả lời rõ ràng.
Tôi chỉ thấy rằng hai hướng tiếp cận này đang phản ánh hai cách nhìn khác nhau về cùng một vấn đề. Một bên chấp nhận trade off để tối ưu trải nghiệm còn một bên cố gắng giữ lại tính đúng đắn ngay cả khi nó chưa thực sự cần thiết.
Có thể cả hai đều đúng trong những ngữ cảnh khác nhau.
Hoặc có thể một trong hai sẽ trở nên không còn phù hợp khi hệ thống tiến hóa... Tuy nhiên tôi vẫn khá thích ý tưởng của SIGN..
Tôi sẽ tiếp tục theo dõi.