30/10/2025 HEMI Articolo #25
La rete HEMI non si concentra solo sul throughput o sulla sicurezza, ma gestisce anche la latenza a livello di millisecondi, poiché anche un piccolo ritardo in molti casi d'uso sensibili a DeFi e al settlement può portare a grandi conseguenze finanziarie. Questo articolo chiarirà in quali fasi i budget di latenza sono suddivisi in HEMI, perché sono importanti e quali sono i suggerimenti pratici per sviluppatori e produttori di prodotti.

Osservazione delle fasi di latenza:
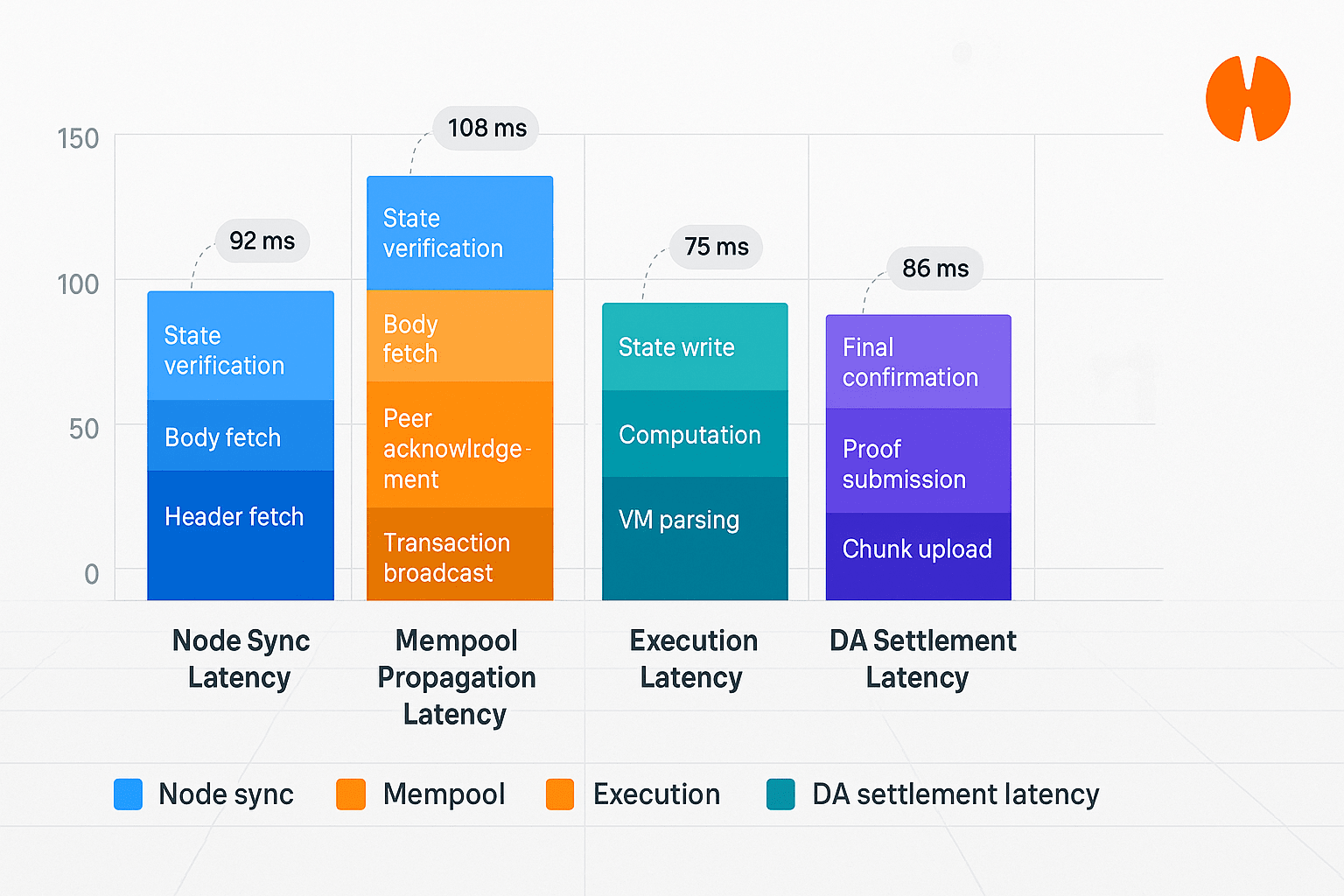
$HEMI Quattro fasi principali di latenza giocano un ruolo cruciale nell'architettura: latenza di sincronizzazione nodo, ovvero il tempo necessario a un nuovo nodo o a un nodo sincronizzato per raggiungere la situazione della rete completa; latenza di propagazione del Mempool, ovvero quanto rapidamente una transazione si diffonde nel mempool della rete quando viene inviata; latenza di esecuzione, ovvero il tempo necessario per l'esecuzione della logica del contratto intelligente o delle transazioni; e latenza di disponibilità dei dati, ovvero quanto tempo ci vuole prima che i dati delle transazioni siano disponibili e verificabili. La combinazione di queste fasi crea l'intero percorso di latenza che deve essere monitorato e ottimizzato in modo sistematico.
Perché i budget di latenza sono importanti:
Un ritardo ridotto ha un impatto diretto sull'esperienza utente, feedback più rapidi e tempi di attesa ridotti aumentano l'affidabilità dell'applicazione. Nei contesti commerciali, se si mantiene bassa la latenza di esecuzione e DA, si ottiene un vantaggio competitivo per strategie sensibili alla latenza e arbitraggio. In termini di sicurezza, la latenza non può essere trascurata; una lunga latenza DA o di sincronizzazione del nodo può causare rischi di ri-organizzazione rari ma gravi o stati inconsistenti. Pertanto, i modelli di rischio praticabili possono essere creati solo identificando i livelli di millisecondi.
Principali intuizioni e considerazioni architettoniche:
@Hemi Il design della latenza funziona secondo i principi della pipeline, aggregando lo stack di latenza dei diversi componenti per derivare il ritardo totale previsto. Gli sviluppatori devono comprendere quale tipo di applicazione è sensibile a quale fase; ad esempio, nella pagamenti istantanei o nell'ordinamento, la latenza del Mempool e dell'Esecuzione è primaria, mentre nella riconciliazione di grandi valori, la latenza DA e di sincronizzazione del nodo diventa determinante. Monitorare la latenza in visualizzazioni come barre impilate aiuta a identificare i colli di bottiglia e a impostare obiettivi SLA.
Suggerimenti pratici focalizzati sugli sviluppatori:
Crea una mappa della latenza per la tua dApp, dove vengono registrate le misurazioni stimate e reali per ogni fase; includi test di regressione della latenza nel CI per mostrare le tendenze ad ogni commit. Mantieni un monitoraggio della rete e una configurazione di osservabilità che riporti il tracciamento end-to-end, le latenze p95/p99 e il tempo di propagazione del mempool. Adotta strategie come la priorità di accodamento, la regolazione della propagazione del mempool e il batching di esecuzione quando necessario, per aiutare a rimanere entro i percorsi critici. Infine, esegui test su vari scenari di latenza in simulazioni locali e di rete limitata per catturare i casi limite in anticipo.
KPI e metriche da monitorare:
Includere le metriche principali: latenza end-to-end (in millisecondi), latenza mempool→esecuzione, tempo di esecuzione per tx, tempo di riconciliazione DA e latenza di sincronizzazione nodo. Registrare regolarmente i valori p50, p95 e p99 di questi KPI e creare avvisi quando vengono superate le soglie. Inoltre, sarà utile mantenere KPI orientati al business come i fallimenti delle riconciliazioni per ora e il tempo medio di recupero.
Conclusione:
I budget di latenza non sono più un aspetto tecnico trascurabile; sono decisivi per il prodotto, specialmente per quelle reti dove i millisecondi contano. HEMI ha chiaramente mappato le fasi Node, Mempool, Execution e DA, indicando che il design delle prestazioni è una responsabilità complessiva. Se stai costruendo su HEMI o valutando una rete, dai priorità alla gestione della latenza nella tua architettura e nei tuoi standard di QA.
Rimani aggiornato con IncomeCrypto per ulteriori informazioni su questo progetto.


\u003cm-72/\u003e\u003cc-73/\u003e\u003ct-74/\u003e\u003ct-75/\u003e\u003ct-76/\u003e\u003ct-77/\u003e