At first glance, OpenLedger sounds like one of those projects that already has its conclusion written before it begins. The kind you’ve seen cycle through the market too many times to take at face value—big promises wrapped in technical language, a confident narrative about “unlocking value,” and an ecosystem that supposedly fixes a problem no one fully agrees on how to measure in the first place. AI meets blockchain, data becomes liquid, models become assets, and somehow everyone gets paid fairly. It’s a familiar script, and usually by the time you’ve read the third paragraph of any such pitch, you already know where it ends: early excitement, incentive-driven participation, a short speculative window, and then a slow drift into irrelevance once attention moves on.
That’s the default expectation, and OpenLedger doesn’t completely escape it. The language still carries that weight of ambition that sounds almost too clean, too aligned with current narratives around AI ownership and decentralized infrastructure. You hear phrases like “on-chain AI execution” and “monetizing data contributions,” and your instinct is to file it under the same category as a dozen similar attempts that tried to turn coordination problems into token economies. So the first reaction is not excitement, but a kind of tired skepticism shaped by experience.
And yet, the more you sit with it, the harder it becomes to dismiss it outright.
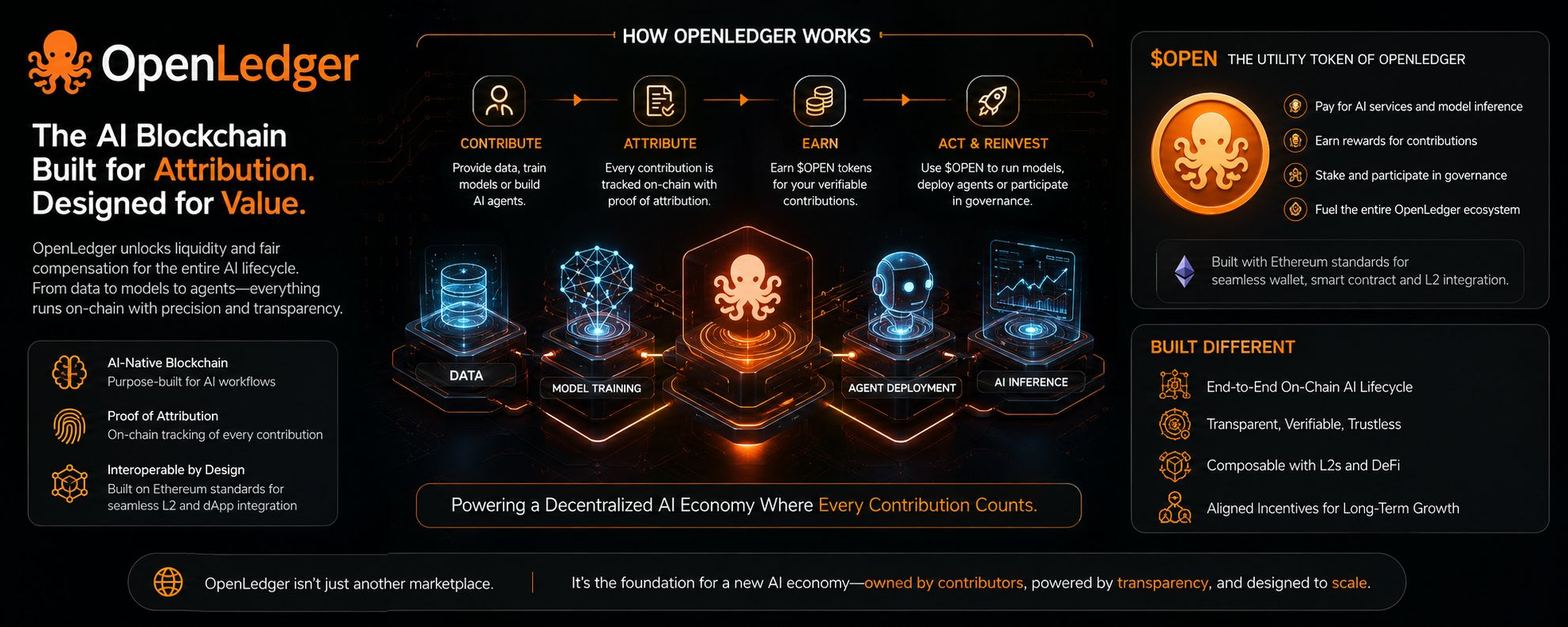
There is at least an attempt here to do something structurally different from the usual “AI token” play. The core idea isn’t just to decentralize compute or create another marketplace for models. It is to make the entire AI lifecycle—data input, model training, and inference—not just traceable but economically accountable. In theory, every meaningful contribution inside the system leaves a footprint that can be measured and rewarded. Data isn’t just consumed; it is attributed. Models aren’t just endpoints; they are composites of measurable inputs. Even AI agents become participants in a system where usage is not abstract, but recorded as value exchange.
In that sense, the flow of the system is deceptively simple. People contribute data or participate in model training or related AI workflows. Those contributions are recognized by the system and rewarded in a native token. That token is then used again inside the ecosystem to access AI services, deploy models, or participate further in the network. It creates a loop where participation feeds consumption and consumption feeds further participation. On paper, it is an internally coherent cycle, almost elegant in its symmetry. It tries to avoid the obvious trap of external dependence by ensuring that value generation and value consumption live in the same environment.
But elegance in design does not always translate into stability in reality.
The real claim OpenLedger is making is not just technical, it is economic. It is suggesting that attribution in AI systems can be precise enough to underpin an economy. That is a much stronger claim than it initially appears. AI training data is messy, interdependent, and deeply nonlinear in how influence propagates through models. Even in controlled environments, tracing exact contribution weight is notoriously difficult. So when a system says it can reward users based on their impact on model outputs, the immediate question is not whether it sounds innovative, but whether it can survive contact with ambiguity, noise, and adversarial behavior.
This is where curiosity starts to replace skepticism, not because the doubts disappear, but because the ambition becomes more specific than the usual vague promises. If OpenLedger is serious about building what it describes, then the challenge is not marketing or token design, but measurement itself. The entire system depends on whether “proof of attribution” can be made robust enough to resist gaming, dilution, and simplification by users who will inevitably try to maximize rewards with minimal real contribution. History suggests that any reward system in crypto eventually becomes a game of optimization rather than participation, and the gap between those two determines whether the economy stays meaningful or collapses into extraction behavior.
The token at the center of this design, often framed as a universal utility unit across the ecosystem, carries that same tension. It is meant to function simultaneously as reward, payment, and access mechanism. That kind of multi-role token design is common in ambitious ecosystems, but it also tends to blur the boundary between real demand and internal circulation. If users earn the token for contributing and then spend it within the same system for access, the question inevitably arises: how much of the demand is external and how much is simply recycled incentive flow? This is not necessarily a flaw in early-stage systems, but it becomes a structural risk if external consumption never grows beyond internal activity.
Still, there is something conceptually stronger here than in many previous attempts at “AI + crypto” convergence. Most projects in that category focus on ownership narratives without solving the harder problem of accountability. OpenLedger at least tries to connect the two by suggesting that ownership without attribution is incomplete, and that AI systems become economically meaningful only when influence can be tracked with enough fidelity to justify reward distribution. If even partially successful, that shifts the conversation away from speculation and toward infrastructure-level valuation of data and model contribution.
But it would be irresponsible to ignore how fragile that idea is when exposed to real-world dynamics. Incentive systems rarely behave as intended once scale and money enter the picture. Users adapt quickly. Patterns of exploitation emerge faster than governance can respond. What looks like participation can easily become simulation. And when simulation becomes profitable, the line between genuine contribution and optimized behavior starts to disappear.
So the tension at the heart of OpenLedger is not whether the vision is interesting—it clearly is—but whether the system can maintain integrity under pressure. Can attribution remain meaningful when participants are incentivized to maximize output? Can AI contribution be measured without oversimplifying it to the point of distortion? Can a closed-loop economy avoid becoming self-referential without external demand anchoring its value?
There is no easy answer to those questions, and the project itself does not appear to offer one yet. What it offers instead is an experiment framed as infrastructure. An attempt to turn AI development into something that behaves more like an economy than a platform. Whether that distinction holds in practice is still unknown.
The most reasonable way to view OpenLedger, then, is neither as a breakthrough nor as another overhyped cycle entry, but as something closer to a controlled stress test of an idea that has been discussed for years but rarely implemented seriously: that AI value creation can be decomposed, tracked, and redistributed in a way that is both fair and scalable. It might work in narrow conditions, or it might collapse under its own complexity once real usage patterns diverge from theoretical design.
Either outcome would still be informative.
For now, it sits in an uncomfortable middle space where the concept is stronger than the evidence, but more grounded than typical narratives suggest. It is not a finished system, and it does not behave like one. It is an attempt to build an economy around attribution in a field where attribution itself is still an unsolved problem.
And like most real experiments, its outcome will depend less on how convincing it sounds today and more on what happens when actual users start trying to push it in directions its designers did not anticipate.