
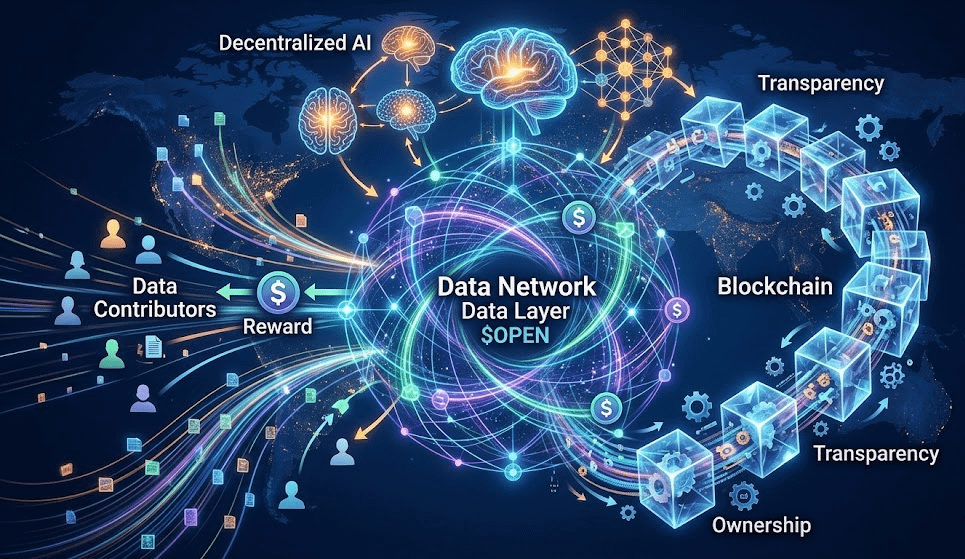
Các mô hình AI mạnh nhất thế giới được huấn luyện từ dữ liệu của cộng đồng, nhưng phần lớn người đóng góp dữ liệu lại không nhận được bất kỳ giá trị nào. Đây chính là lý do mình bắt đầu chú ý đến @OpenLedger — một dự án đang xây dựng hạ tầng dữ liệu phi tập trung cho AI economy.n người đóng góp dữ liệu lại không nhận được bất kỳ giá trị nào. Đây chính là lý do mình bắt đầu chú ý đến @OpenLedger — một dự án đang xây dựng hạ tầng dữ liệu phi tập trung cho AI economy.
VẤN ĐỀ CỐT LÕI CỦA AI HIỆN TẠI
AI hiện nay tồn tại 4 vấn đề lớn:
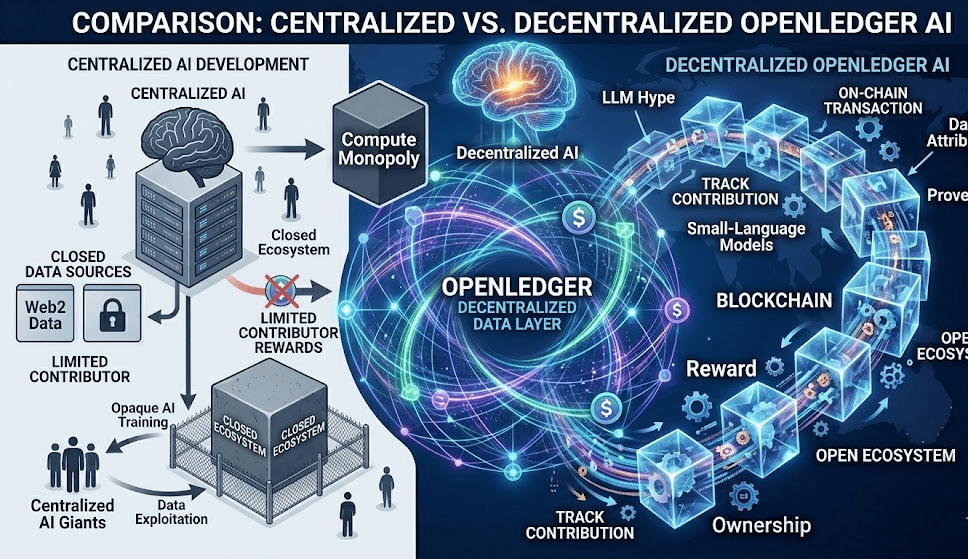
1. Data Centralization
Các công ty AI lớn đang kiểm soát gần như toàn bộ dữ liệu training. Người dùng tạo ra dữ liệu nhưng không sở hữu cũng không được chia sẻ giá trị.
2. Opaque Training
Chúng ta không biết:
dữ liệu AI lấy từ đâu
có vi phạm bản quyền không
có bị bias hay không
Toàn bộ quá trình training gần như là “black box”.
3. Contributor Không Được Reward
Creator, writer, data labeler hay cộng đồng đóng góp dữ liệu gần như bị bỏ quên trong chuỗi giá trị AI.
4. Compute Monopoly
AI ngày càng phụ thuộc vào các datacenter khổng lồ, khiến quyền lực tập trung vào một vài công ty sở hữu GPU và infrastructure.
Mục tiêu của OpenLedger:
Dự án đang xây dựng một Data Infrastructure Layer cho nền kinh tế AI phi tập trung.
Mục tiêu của OpenLedger:
ghi nhận nguồn gốc dữ liệu
xác minh đóng góp
reward contributor
tạo nền tảng dữ liệu minh bạch cho AI models
Nói cách khác: OpenLedger muốn biến dữ liệu thành một loại tài sản có ownership rõ ràng.
ĐIỂM QUAN TRỌNG NHẤT: DATA ATTRIBUTION
Theo mình, đây là phần đáng chú ý nhất của OpenLedger.
Hiện nay: AI model học từ dữ liệu cộng đồng nhưng không ai biết chính xác dữ liệu nào tạo ra giá trị.
OpenLedger đang cố giải quyết bằng:
provenance tracking
attribution system
reward distribution
Nếu dữ liệu bạn đóng góp giúp AI model tốt hơn: → bạn có thể được reward.
Đây là khái niệm cực kỳ quan trọng nếu decentralized AI thực sự phát triển mạnh trong tương lai.
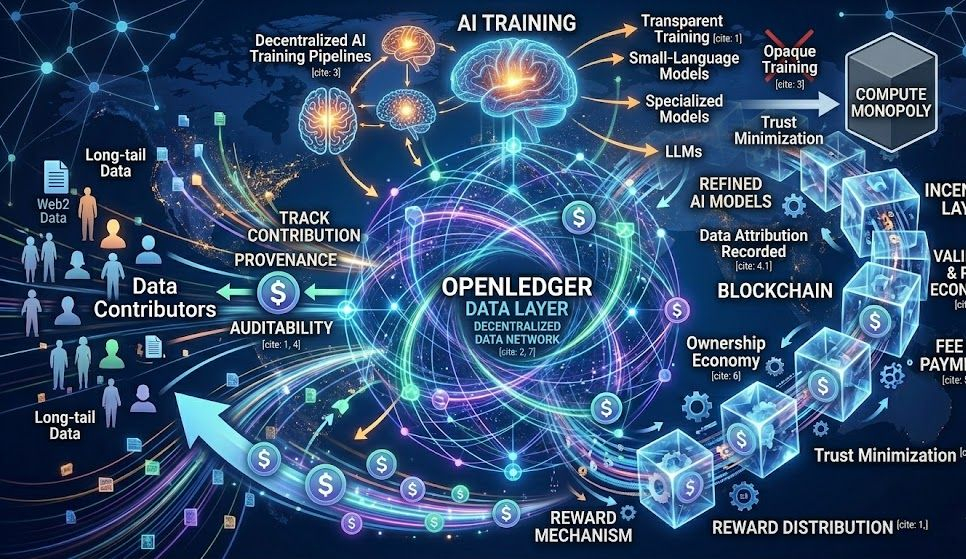
$OPEN không chỉ là governance token thông thường.nance token thông thường.
Token có thể đóng vai trò:
staking
validator incentive
payment cho data access
ecosystem rewards
governance
Điểm mình đánh giá cao là khả năng tạo “token sink”.
Nếu các doanh nghiệp hoặc AI builders muốn truy cập nguồn dữ liệu chất lượng: → họ cần dùng $OPEN.
Điều này tạo demand thực tế thay vì chỉ dựa vào speculation.
TẠI SAO NARRATIVE AI x WEB3 ĐANG BÙNG NỔ?
AI đang tăng trưởng cực nhanh, nhưng dữ liệu chất lượng cao ngày càng khan hiếm.
Đây là lúc Web3 có thể trở nên quan trọng:
ownership economy
data monetization
decentralized infrastructure
creator incentives
Trong tương lai, dữ liệu có thể trở thành tài sản on-chain giống như liquidity hay compute power hiện nay.
Và OpenLedger đang cố xây layer cho điều đó.
OPENLEDGER KHÁC GÌ CÁC AI PROJECT KHÁC?
Nhiều dự án AI Web3 hiện tập trung vào:
GPU sharing
compute power
inference network
Nhưng OpenLedger tập trung vào: DATA LAYER.
Theo mình đây là hướng đi khá thông minh vì: AI cuối cùng vẫn phụ thuộc vào “thức ăn” của nó — chính là dữ liệu.
GÓC NHÌN CÁ NHÂN
Mình nghĩ OpenLedger đang chọn một hướng đi khó nhưng dài hạn.
Điểm mạnh:
đánh vào data ownership
decentralized attribution
incentive economy
Nhưng vẫn còn nhiều challenge:
data quality
adoption
chống spam/synthetic data
cạnh tranh với hệ sinh thái Web2
Dự án sẽ cần:
đủ contributor
đủ AI builder
đủ ecosystem usage
để tạo network effect thực sự.
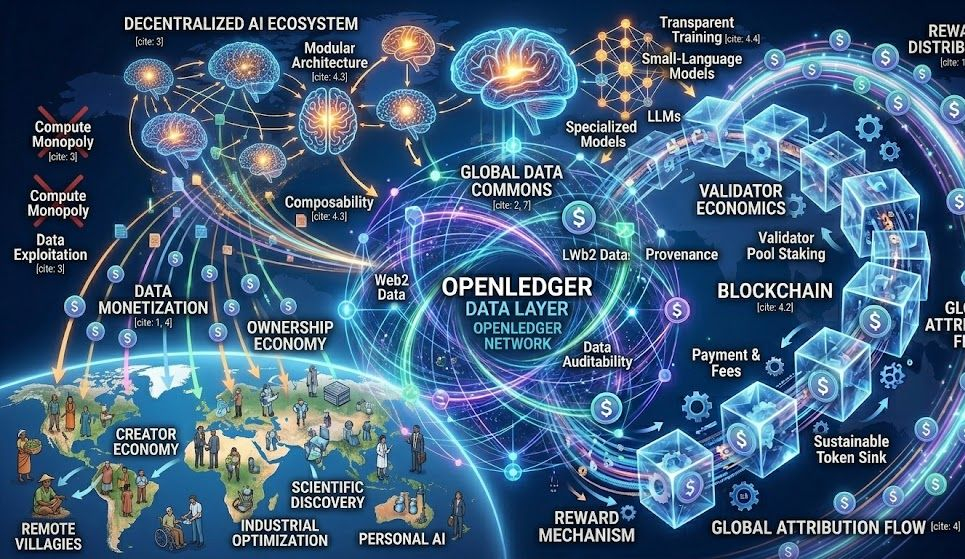
OpenLedger không chỉ là một AI hype token ngắn hạn. ngắn hạn.
Nếu AI economy tiếp tục mở rộng, thì:
ownership
attribution
transparency
data monetization
sẽ trở thành những narrative cực lớn.
Và OpenLedger đang cố xây nền móng cho điều đó.
Đây chắc chắn là một dự án đáng để research thêm trong mảng AI x Web3.
DYOR về @OpenLedger và theo dõi cách dự án phát triển trong thời gian tới.