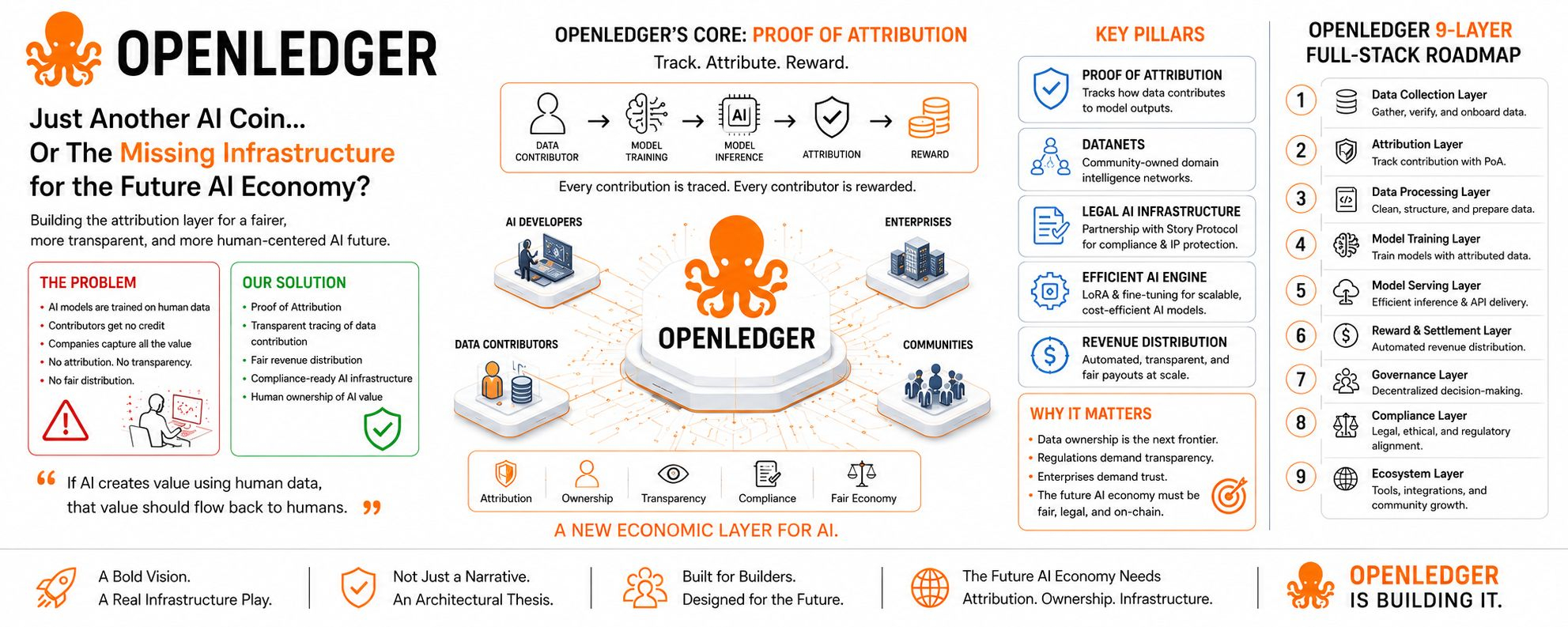
Some projects instantly make you think:
Okay… is this just another AI narrative?
At first, I honestly felt the same way about OpenLedger.
Because right now, whenever you see AI + blockchain together, almost every project tries to sell some futuristic vision:
decentralized intelligence, autonomous economies, AI agents, infinite scalability…
It sounds exciting.
But once you dig deeper, a lot of those narratives start feeling hollow.
There’s hype.
There’s a token.
There’s branding.
But very little real infrastructure thinking underneath.
The more I researched OpenLedger, though, the more one thing stood out to me:
They’re actually trying to solve a real problem.
Today’s AI industry is fundamentally unbalanced.
The people providing the data, creating the content, contributing niche knowledge, and training the ecosystem… usually get nothing.
Meanwhile, companies with infrastructure take that data and build billion-dollar AI models on top of it.
That’s where OpenLedger approaches things differently.
Their core idea is surprisingly simple:
If AI models are trained using human-generated data, then the value created by AI should flow back to humans as well.
Simple in theory.
Extremely difficult in practice.
Because saying “decentralized AI” is easy.
Actually building attribution infrastructure is the hard part.
You need to track:
who contributed the data,
which model used it,
how it influenced inference outputs,
and then automate revenue distribution fairly at scale.
That’s why their “Proof of Attribution” system caught my attention.
Imagine a finance-focused AI model in the future.
You contribute a verified finance dataset.
Later, an enterprise uses that model through an API.
OpenLedger wants the backend infrastructure to trace whose data contributed to the generated output — and potentially reward them accordingly.
Honestly, this attribution layer feels massively underrated right now.
Because the biggest future battle in AI may not be about model performance.
It may be about ownership.
Who owns the data?
Who gave permission?
Who deserves compensation?
And regulators are already moving aggressively in that direction.
Especially after Europe’s AI Act, these questions are becoming unavoidable:
What data trained the model?
Was consent given?
Was commercial usage legal?
Was attribution transparent?
That’s also why the Story Protocol partnership didn’t feel like random marketing to me.
It felt strategic.
Because OpenLedger seems to understand something many projects still ignore:
Open-source AI alone isn’t enough.
Legal AI infrastructure matters.
Compliance matters.
Attribution matters.
Enterprise adoption only happens when trust exists.
And honestly, very few crypto AI projects are thinking about legal infrastructure this early.
Another thing that stood out to me was their “Datanets” concept.
This isn’t just dataset storage.
It’s an attempt to build community-owned domain intelligence.
Because the future AI economy probably won’t revolve around one giant ChatGPT-style model solving everything.
Instead, niche intelligence could become incredibly valuable.
Healthcare AI.
Legal AI.
Biotech AI.
Trading AI.
Scientific research AI.
All of these require highly specialized datasets.
OpenLedger wants to tokenize and structure that niche data economy.
Now the big question is:
Is this technically realistic?
Surprisingly… parts of it already are.
Thanks to LoRA architectures and efficient fine-tuning methods, smaller specialized AI ecosystems are becoming much more practical.
A few years ago, massive GPU infrastructure was mandatory for everything.
Now lightweight adaptation allows highly targeted models to run far more efficiently.
And OpenLedger seems heavily focused on optimizing this direction.
Their broader vision — running thousands of fine-tuned models efficiently — is theoretically very powerful.
But there’s also a serious reality check here.
AI infrastructure is brutally expensive.
Narratives alone don’t create sustainable revenue.
And decentralized AI still has a massive demand-side problem.
Builders will build.
That’s not the issue.
The real challenge is enterprise adoption.
Because enterprise clients care about:
stability,
uptime,
compliance,
latency,
reliability.
They don’t spend millions on experiments.
So OpenLedger’s long-term success probably depends on two things:
First:
Can they actually deliver enterprise-grade AI infrastructure?
Second:
Can their attribution mechanism function at global scale?
Because a small demo and a real-world inference economy are completely different games.
Still… I’ll admit this:
At least they’re attempting to solve something meaningful.
Most AI tokens in crypto today feel more like attention farming than actual infrastructure plays.
Everyone talks about “AI agents” and “autonomous economies.”
But once you look deeper, many projects feel empty.
With OpenLedger, there’s at least a visible architectural thesis behind the vision.
Especially when you look at their 9-layer full-stack roadmap, it becomes clear they aren’t trying to stop at launching a token.
They’re aiming to build an on-chain AI operating layer.
Will it succeed?
No idea.
There’s massive risk involved.
Token economics are difficult to sustain.
Buyback narratives rarely survive long term without real revenue.
Decentralized governance becomes messy in practice.
Enterprise adoption could take years.
Community voting sounds great in theory.
But average token holders usually don’t understand high-level infrastructure decisions.
Even so… from a builder’s perspective, this project isn’t boring.
Because there’s at least an original thesis here.
And if the future AI economy truly becomes massive, then data ownership, attribution, and revenue sharing may eventually become unavoidable parts of the system.
OpenLedger is betting on that future earlier than most.
Maybe it fails.
Maybe it pivots.
Maybe it creates an entirely new category.
But one thing feels clear:
This doesn’t look like just another shallow “AI coin” narrative.
There’s a real infrastructure-level ambition behind it 🚀
Now the real question is:
Can they actually execute?


