
说实话,我也算是个老韭菜了,平时闲着没事就喜欢翻翻各种项目的白皮书。说真的,大多数项目的白皮书真的是让人看得昏昏欲睡。那厚厚的一沓PDF文档,动不动就五六十页,打眼一看全是高大上的愿景和各种看不懂的技术路线图。给人的感觉就是,作者好像什么都说了,把能吹的牛都吹遍了,但你耐着性子全部看完之后,脑子里又是一片空白,完全不知道这个项目到底想干嘛,能干嘛。

不过,最近我看到#OpenLedger 抛出来的白皮书,倒是让我眼前一亮。他们这次玩了点不一样的花样,直接摒弃了那种老掉牙的静态PDF格式,而是换成了GitBook这种模块化的网页形式。我大概翻了一下,体量其实也不小,折算下来估计也有个五六十页的样子。但不得不说,这种GitBook的阅读体验,比起那些老派的白皮书真的要舒服太多了。你可以像浏览网页一样,想看哪块就点哪块,结构清晰,逻辑顺畅,让人很有读下去的欲望。
第一次看OpenLedger白皮书的时候,最抓我眼球的倒不是他们白皮书排版有多精美,排版再好那也是虚的。真正吸引我的是,他们开篇就极其直接地把矛头对准了一个行业痛点。他们在白皮书里甩出了一个数据,说是现在全球AI数据市场规模大概已经达到了五千亿美元。这确实是个天文数字,但紧接着他们就指出,现在这个庞大的市场资源分配完全是失衡的。我觉得这就很有意思了,直接点破了巨头垄断,数据贡献者却拿不到好处的现状。
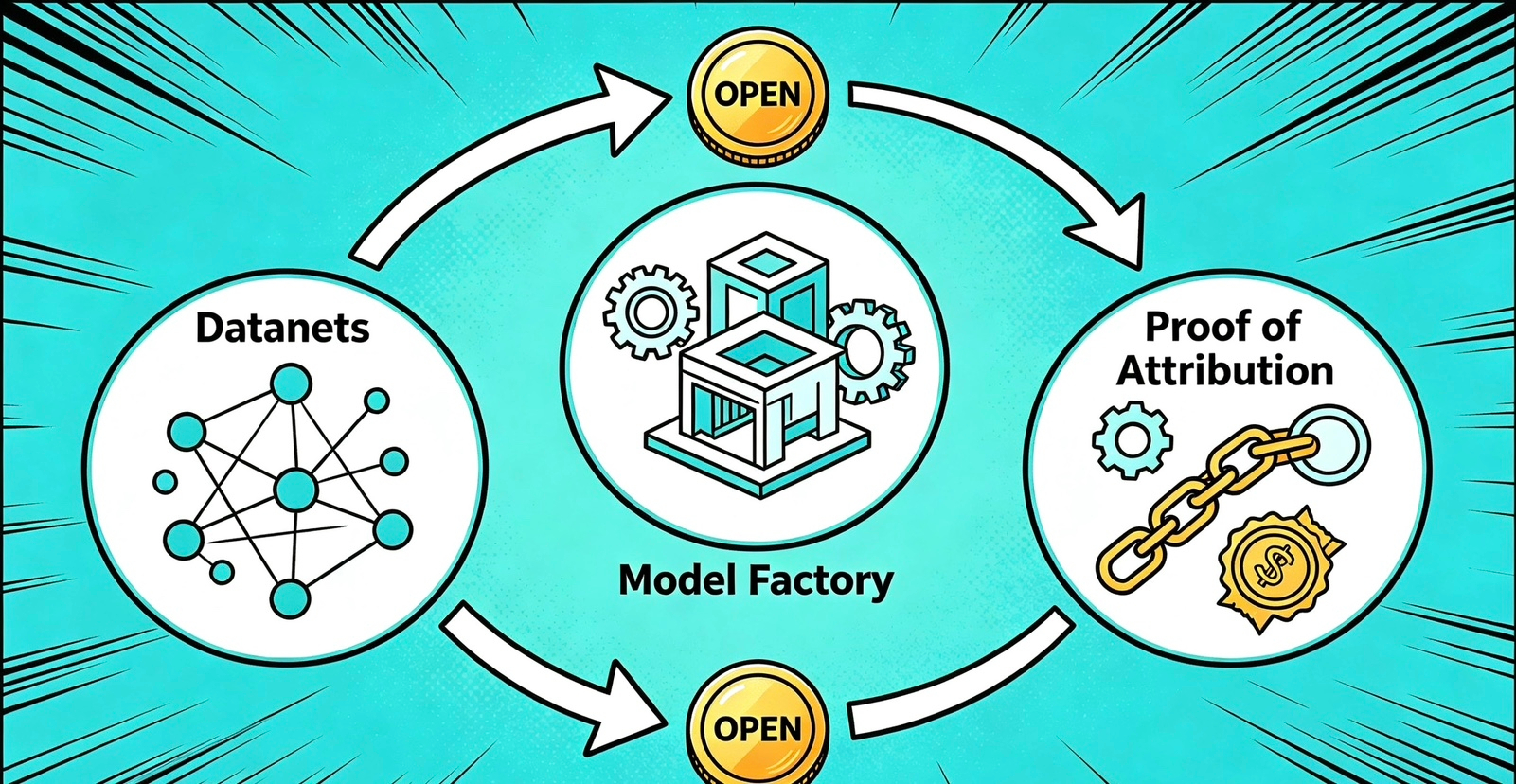
那么OpenLedger到底是想怎么解决这个问题的呢。我在白皮书里仔细扒了扒,他们提出了三个硬核的技术模块,这三个模块构成了他们整个生态的底层逻辑。首先是一个叫Datanets的模块,它主要负责数据的采集和整理。说白了,就是把散落在各处的脏数据变成AI能用的好数据。然后是Model Factory,顾名思义就是模型工厂,它负责模型的训练和部署。最后还有一个Proof of Attribution,我把它翻译成归因验证。这个东西非常关键,它是用来证明某份数据对某个模型的训练到底做出了多少贡献的。OpenLedger把这三个环节有机地串联在了一起,形成了一个完整的闭环。从最初的数据采集,到中间的模型训练,再到最后的收益分配,全流程都是可以追溯的。我觉得这个逻辑是非常严密的,它不是在空喊口号,而是真的想从技术层面去重构AI数据的供应链。
除了技术架构,我作为投资者,最关心的肯定还是代币经济学这块。说实话,这部分的内容倒是让我挺意外的。OpenLedger的代币总供应量设定为十亿枚。根据白皮书披露的数据,项目上线的时候,初始流通量大概只有二点一五五亿枚,占总量的百分之二十一点五五。说真的,这个初始流通比例在一大堆新上线的项目里,算是控制得比较克制的了,没有那种一上来就巨量流通砸盘的风险。在具体的代币分配结构上,社区占了很大头,达到了百分之五十一点七。投资人占了百分之十八点二九。团队占了百分之十五。剩下的份额则用于生态建设和提供流动性。最让我看重的是他们的解锁机制。社区和生态的份额是整整四十八个月线性解锁。团队和投资人则有一年的锁仓期,之后还要分三十六个月线性释放。我以前真的看过太多项目,一上线代币价格就崩盘,原因几乎都一模一样。那就是团队解锁太激进,早期投资人又急着套现,结果就是苦了我们这些二级市场的接盘侠。但OpenLedger这套解锁机制,不管是团队还是投资人,都被长长地锁在里面,这怎么看都是在往长期发展的方向上走,至少看起来没有什么短期割一把就跑路的味道。@OpenLedger
白皮书里还有一个提法挺有意思的。他们说自己尝试解决的不仅仅是单纯的技术难题,更是一种行业的信任危机。这话说得挺深刻的。大家都知道,现在的AI决策过程就像是个黑箱,谁也不知道它为什么会得出这个结果。而且用来训练AI的数据都封闭在巨头的服务器里,我们这些数据的贡献者,我们的努力根本没人认领,也拿不到半点好处。这些话听起来可能有点虚,但我看OpenLedger确实是在尝试用链上记录的方式来解决。他们要把每一次数据的贡献,模型的每一次微调,甚至是模型推理的每一次调用都上链存证,就是要通过这种技术手段,确保所有的过程都是可追溯的,所有的贡献都是可分润的。
如果非要说白皮书给我留下最深刻的印象是什么,我想应该是他们试图把两件很难融合的事情强行放在一起做。大家都知道,区块链的技术底色需要透明,需要可验证,但AI的技术特性又需要大规模的数据,这两者之间天然就存在着矛盾。你想想看,如果把全部的原始数据都上链,那存储成本得有多高,那是根本不可接受的天价。但如果把数据放在链下,不上链,那区块链又没法验证数据的真实性和贡献。针对这个两难的困境,白皮书给出了一个非常有创意的方案,他们设计了一个三层存储架构。最核心的链上存证层,只存储数据的哈希值和元数据,这就把上链的数据量压到了最低。然后他们引入了EigenDA这种数据可用性存储技术,用来做大规模数据的存储。在这两层之上,还加了一层分布式节点缓存。我觉得可以举个具体的例子来说明,比如有一个医疗科研团队,他们上传了十GB的病例数据。OpenLedger的系统并不会把这十GB的原始数据直接懟上链,链上只记录这份数据的哈希值,上传者的地址,还有相关的权限规则这些关键信息。原始的数据则被妥妥地放在EigenDA存储层和节点缓存层。我觉得这种分层的存储策略是非常高明的,它既利用了区块链保证了数据的可追溯性和不可篡改性,又完美地避开了把大量原始数据直接怼上链所导致的Gas成本爆炸问题。这种在技术层面的妥协和创新,我觉得是非常接地气的工程化思维。
$OPEN 代币的空投是从去年9月正式开始的。首批代币主要发给了测试网的积极参与者和早期的社群成员。我当时虽然没有赶上这第一批的福报,但我倒是认识几个领到空投的朋友。根据他们的反馈,领取过程挺顺畅的,大家对项目的预期也都还不错。这也从侧面说明,这个项目并不是那种只会写白皮书吹牛的空气项目,它是在按照既定的路线图一步一步推进运作的。
总的来说,OpenLedger给我的感觉不是那种只会高调喊口号,整天蹭热度的项目。从那份GitBook形式的白皮书来看,他们的行文风格和甩出来的数据都比较实在,没有太多的水分。整个技术逻辑也能够做到自洽,最关键的是代币经济学的设计偏向长期发展,团队和投资人都被长长地锁住了。而且项目已经顺利上线,空投也开始发放,这本身就已经足够说明很多问题了。那些平时只喜欢追逐市场热点炒作各种概念的人,可能会觉得OpenLedger这个项目听起来太工程化,太过于枯燥乏味。但依我看,这种在技术路线上稳扎稳打的作风,恰恰是一个项目能够长期发展下去的底气所在。$OPEN
最后我也想谈谈我自己的一些纯主观的个人观点。我总觉的@OpenLedger 这个项目,它是切切实实地踩在了AI和区块链这两个大时代的交汇点上。现在的AI发展离不开高质量的数据,而区块链技术天然就具有让数据流转变得更安全,更公平的神奇功效。OpenLedger尝试搭建的这套底层基础设施,我觉得如果真的能够按部就班地落地,那它将不仅仅是一个区块链项目,更像是未来AI时代的一种新型的数据生产关系。它让我们可以把自己的数据主权重新握在自己手里,而不是像现在这样,我们的数据资产被巨头们肆意收割。虽然说未来的路肯定还很长,中间也会充满各种不确定性,比如技术的实现难度,数据的隐私保护,巨头们的围追堵截等等。但我敢肯定,这种扎实的技术路线,以及对解决信任危机的这种执着尝试,在目前这个充满了泡沫和浮躁的加密市场里,依我看,绝对是一股难得的清流。
我反正觉得这个项目是值得我们去长期关注,去慢慢陪伴它成长。它不是那种让你一夜暴富的短线筹码,更像是一个需要时间慢慢打磨,慢慢散发光芒的长期资产。我甚至觉得它有一种老派的工程化浪漫,就是那种用一行行代码,一个一个技术模块去构筑未来世界的脚踏实地。