I was thinking about this the other day while clearing old photos from my phone. Some pictures looked useless at first. A blurry receipt, a random screenshot, a half-written note. Then I realized some of them only became valuable later because they helped me remember context. Memory often works like that. Its value is not obvious when it is created. It becomes useful when something later depends on it.
That is partly why OpenLedger caught my attention.
Most people look at AI infrastructure projects and immediately focus on models, compute, or speed. Fair enough. Those are visible parts of the system. But OpenLedger seems to be asking a slightly different question. What if the scarce thing in AI is not just processing power, but memory that can be traced, verified, and economically recognized?
That changes the framing.
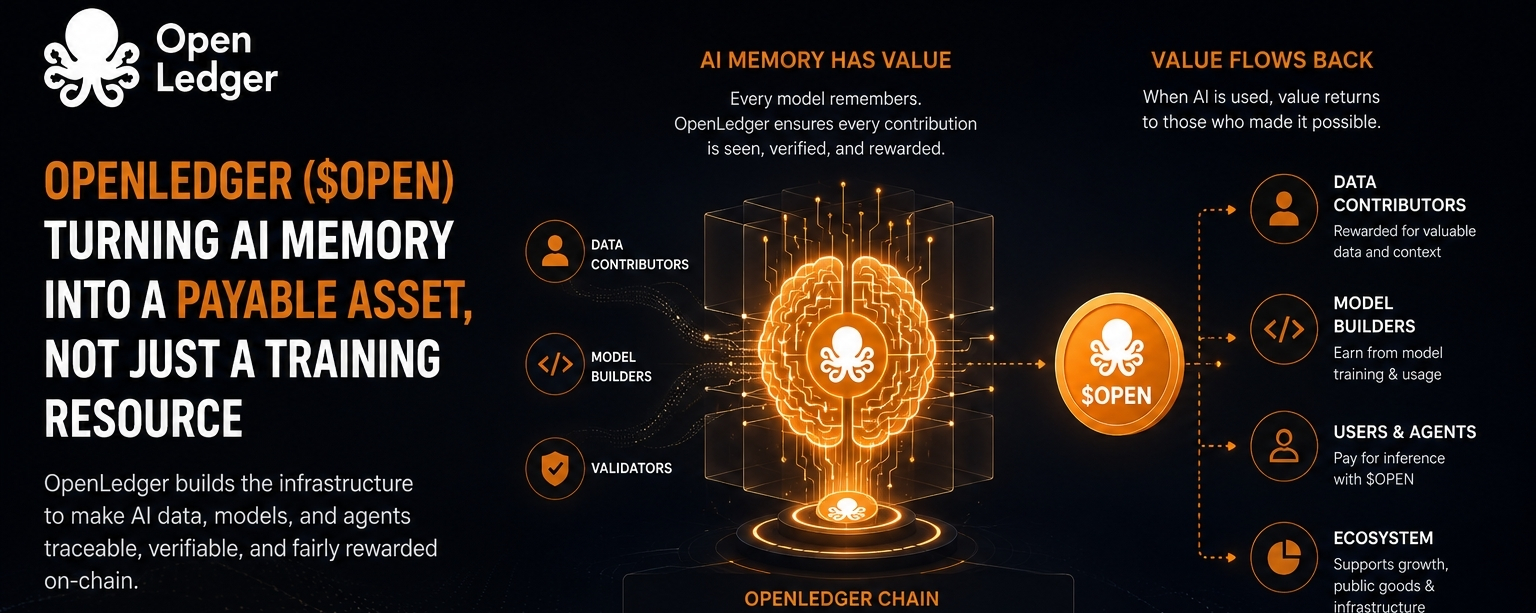
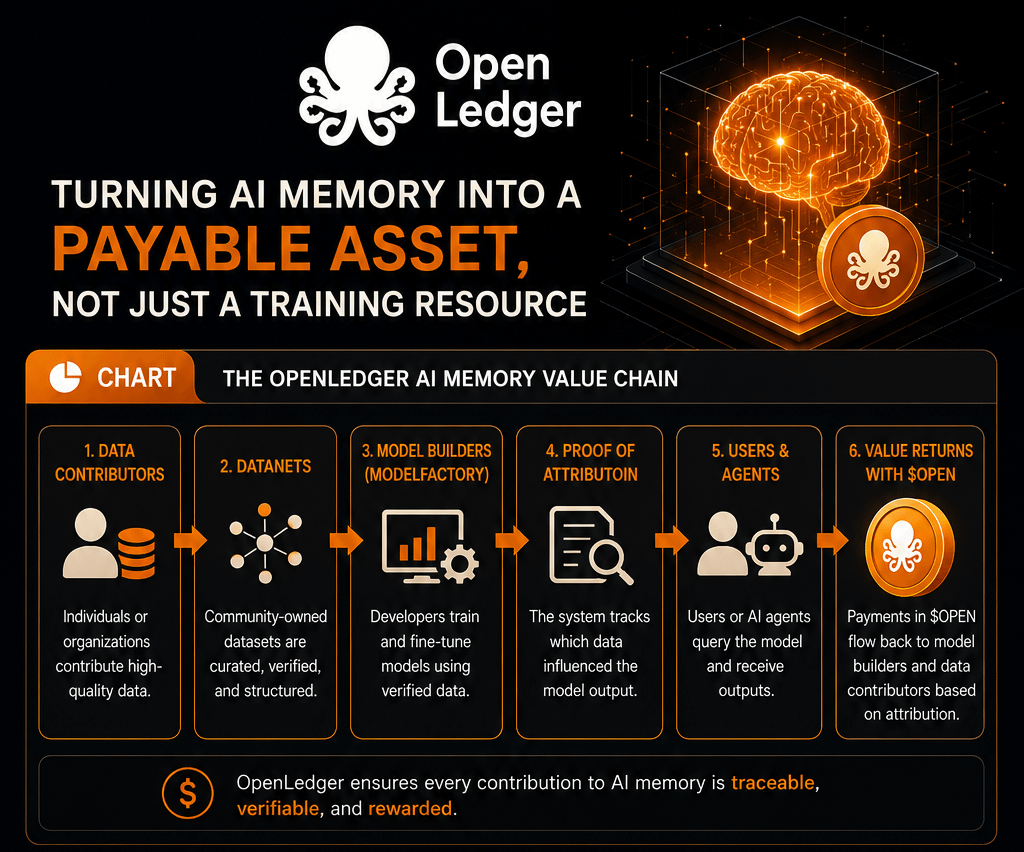
In most AI systems today, data goes in, models get trained, outputs come out, and the origin story gets blurry fast. The model remembers patterns, but the people or systems that shaped that memory usually disappear from view. OpenLedger’s idea around Proof of Attribution tries to challenge that by making contribution traceable. In simple terms, it attempts to track what data influenced a model’s behavior and connect economic rewards back to that influence.
That sounds straightforward until you think about what “memory” means in AI.
A trained model is basically compressed experience. It does not remember like a human does, but it carries statistical traces of what it learned from. If OpenLedger can reliably map those traces back to contributors, then AI memory stops being a black box and starts looking more like an economic asset.
That is where the idea gets more interesting than the usual “AI blockchain” label.
Because if memory becomes payable, the incentive structure changes. Data contributors are no longer just unpaid inputs. They become economic participants. Model builders are not only shipping software. They are managing memory assets. Even inference, which simply means running the model to generate output, becomes part of a payment loop rather than a one-time technical action.
I think this matters because crypto often misprices where value actually forms.
Markets like obvious stories. Compute is easy to explain. Faster chips, bigger models, more users. But attribution is harder because it deals with invisible contribution. Invisible things often stay ignored until someone builds accounting around them.
Look at social platforms. Likes existed before creator monetization systems became serious. Engagement was visible, but monetization logic came later. Once dashboards started measuring attention, behavior changed. People optimized for what could be counted.
Binance Square works in a similar way. Creator rankings, visibility systems, AI-assisted relevance scoring, all of that quietly shapes behavior. Writers do not just post ideas. They respond to what the system appears to reward. Once measurement exists, incentives follow.
OpenLedger might be trying something similar for AI contribution.
The risk is obvious though.
Once attribution becomes measurable, people will optimize for attribution rather than usefulness. That happens in every ranking environment. SEO did it to websites. Social media did it to content. Creator platforms do it to engagement. AI data systems could easily face the same distortion.
Imagine contributors feeding data designed not to improve models, but to maximize reward eligibility. That would create economic noise instead of genuine memory value.
So OpenLedger’s challenge is not only technical verification. It is behavioral quality control.
And honestly, that is harder.
Technical systems can prove transactions happened. Human incentive systems are messier. Low-quality contribution often looks productive until outcomes degrade.
This is where Datanets become more than just a storage idea. OpenLedger positions them as structured, community-owned datasets for AI training. If that works, Datanets are not simple repositories. They become economic filters deciding what kind of memory enters the system.
But filters introduce another tension.
Who decides what qualifies as useful memory?
That sounds philosophical, but it becomes practical fast. A finance AI values different data than a healthcare AI. A trading agent may prioritize speed and relevance while another model may need long historical depth. Quality is contextual, not universal.
So the marketplace for memory cannot just be about contribution volume. It has to price contextual usefulness.
That is much harder than rewarding uploads.
I also keep wondering whether “memory” is even the right monetization layer.
Because memory alone does not create demand.
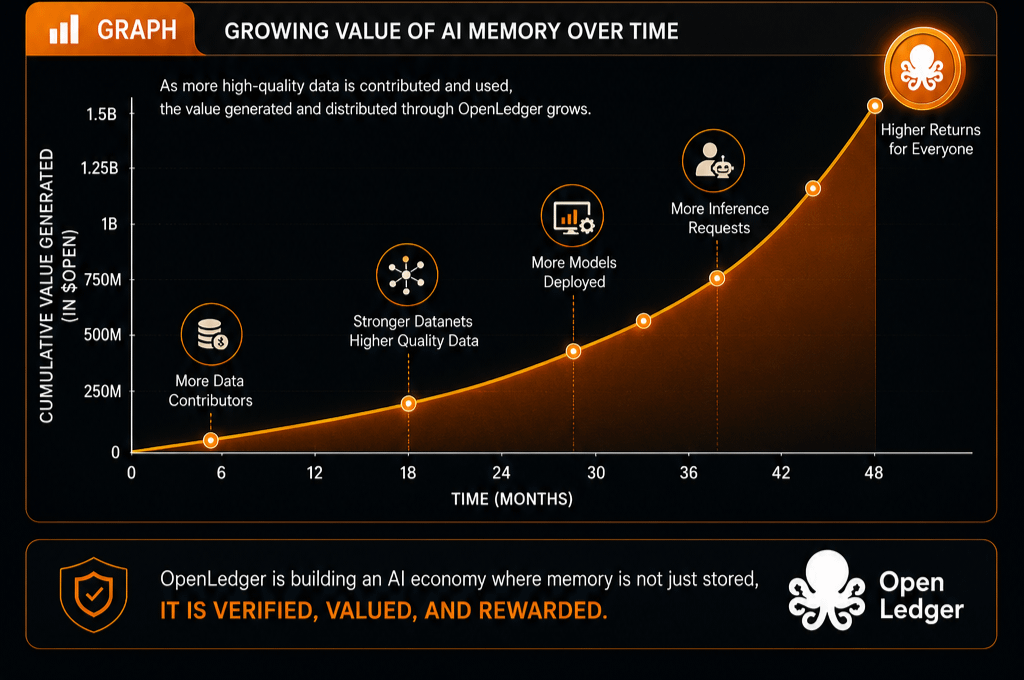
Demand comes when someone repeatedly needs access to useful outputs. If no one is actually querying these models, attribution rewards remain theoretical. Token systems can simulate activity for a while, but markets eventually notice when payment loops depend more on incentives than organic use.
That is where many infrastructure narratives struggle.
Usage and demand are not the same thing.
A project can generate transactions through staking mechanics, rewards, or temporary campaigns. Real demand looks different. It tends to repeat without constant encouragement.
For OpenLedger, that means the real test is inference demand. People or agents must keep using models because the outputs are useful, not because the token system temporarily makes participation attractive.
Otherwise memory becomes an accounting exercise.
There is also an angle most people are not discussing much.
If AI agents begin interacting with other AI agents, verified memory may matter more than raw intelligence. A smart agent using unreliable inputs can still make bad decisions. An average agent using traceable, trusted context may outperform in real workflows.
If that happens, OpenLedger is not monetizing stored data.
It is monetizing trust embedded inside machine memory.
That is a different narrative entirely.
Still, markets tend to get ahead of themselves. A compelling architecture does not guarantee adoption. Token utility on paper often looks cleaner than actual behavior under pressure.
But I do think OpenLedger is asking a more interesting question than most AI tokens.
Not whether machines can think faster.
Whether machine memory itself can become something people are paid for preserving, improving, and proving.