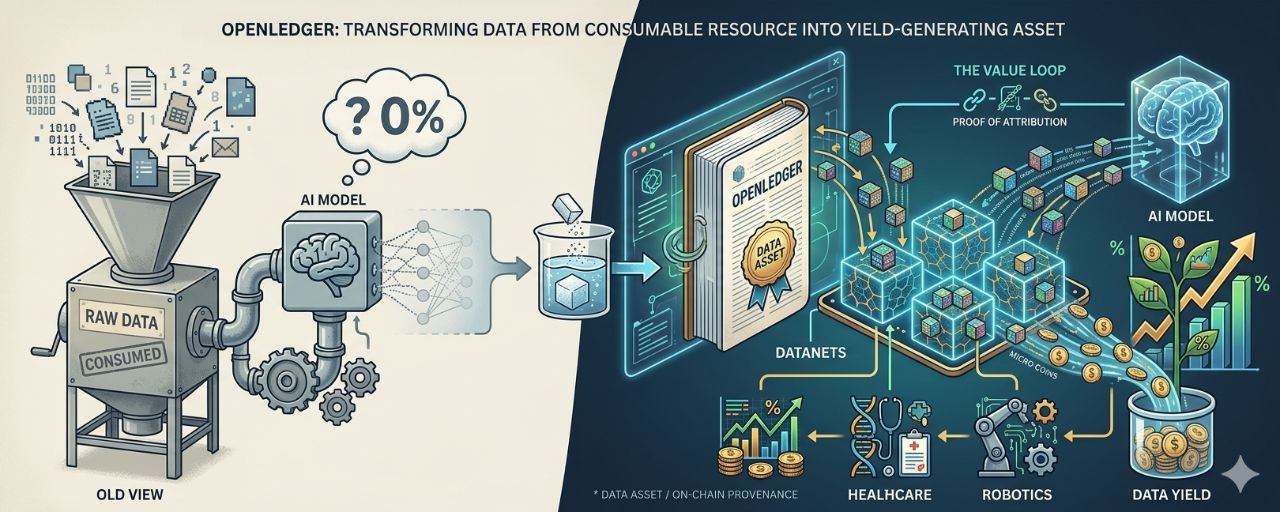
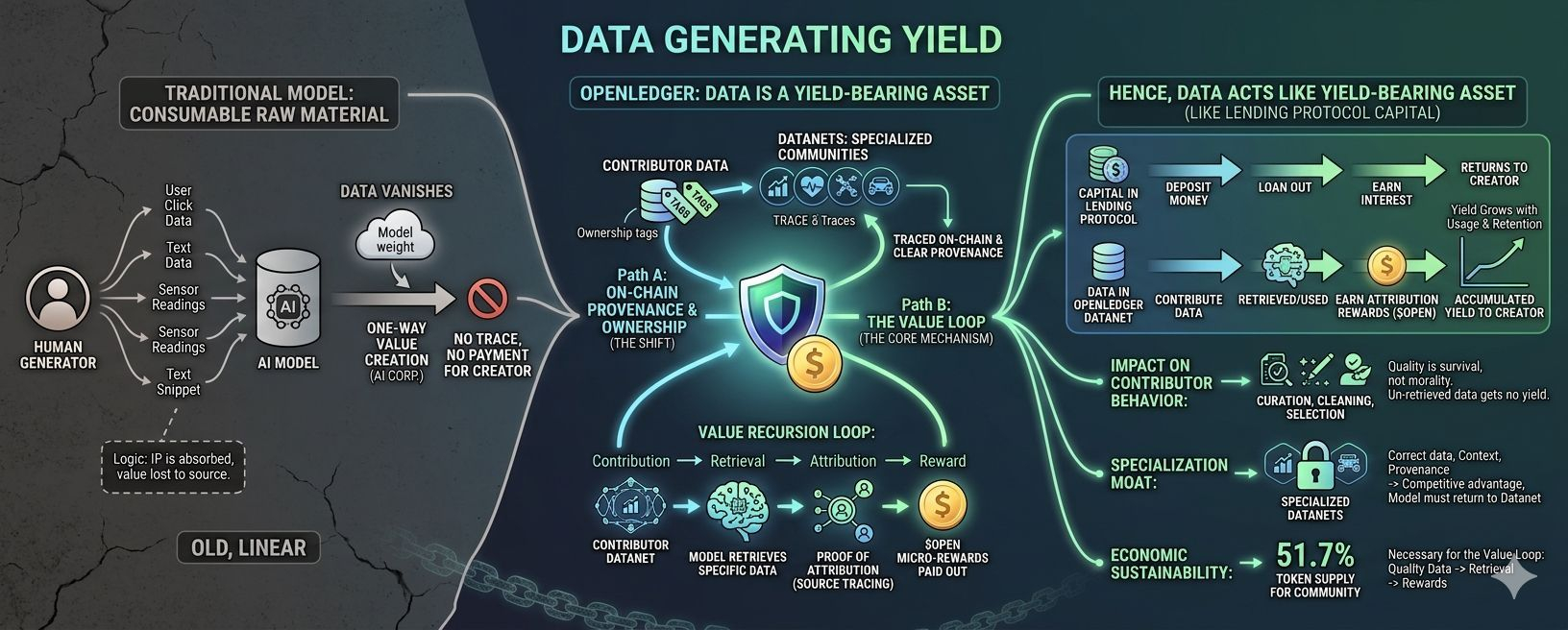
Mình từng hiểu data theo cách đơn giản nhất: đó là nguyên liệu. AI Model cần data để học, học xong thì data không còn xuất hiện ở đâu nữa. Nó biến mất vào bên trong weights của model như muối tan vào nước. Bạn không nhìn thấy nó, không trace được nó, và chắc chắn không ai nghĩ đến chuyện trả tiền cho người đã tạo ra nó.
Cái logic đó cực kỳ phổ biến. Và cực kỳ có vấn đề.
Tổ chức WIPO ước tính thị trường IP toàn cầu, bao gồm digital rights và data, đang tiến gần mốc 80 nghìn tỷ đô. Phần lớn giá trị đó đang bị hấp thụ bởi các công ty AI mà không có cơ chế nào để distribute ngược lại cho người tạo ra nó. Data đang tạo ra value khổng lồ, nhưng theo một chiều.
OpenLedger xuất phát từ một giả định khác hẳn: data không phải nguyên liệu tiêu hao. Nó là tài sản. Và tài sản thì có thể sinh yield.
Để hiểu tại sao, mình cần nói về Datanets trước. Trong hệ thống OpenLedger, khi bạn đóng góp dữ liệu, nó không đi vào một kho tập trung vô danh. Nó đi vào Datanets, là các mạng dữ liệu cộng đồng được dùng để train các model chuyên biệt. Tại thời điểm đó, data của bạn có chủ sở hữu rõ ràng. Có vị trí. Có provenance được ghi on-chain. Đây là cú lệch đầu tiên trong cách hệ thống nhìn nhận không còn là input vô danh, mà là contribution có thể trace.
Nhưng quan trọng hơn là điều xảy ra tiếp theo.
OpenLedger đang sử dụng một cơ chế mà mình tạm gọi là vòng hồi quy giá trị: contribution → retrieval → attribution → reward. Đây không phải một transaction một lần. Nó là một vòng lặp. Mỗi lần dữ liệu của bạn được truy xuất và sử dụng trong output của một model, Proof of Attribution của OpenLedger trace ngược về source, và bạn nhận micro-reward tương ứng với mức ảnh hưởng thật của data đó lên output. Điều này có nghĩa là value của data không nằm ở lúc bạn upload. Nó xuất hiện mỗi khi data được dùng lại.
Đây là lý do data bắt đầu hành xử giống một yield-bearing asset hơn là nguyên liệu.
Hãy nghĩ theo cách này. Khi bạn gửi tiền vào một lending protocol, tiền đó không bốc hơi. Nó được cho vay đi, tạo ra lãi, và lãi đó chảy ngược về bạn theo tần suất sử dụng. Data trong Datanets của OpenLedger hoạt động theo cấu trúc tương tự. Data không biến mất sau lần đầu được dùng. Nó tiếp tục nằm trong hệ thống, tiếp tục được retrieve, tiếp tục tạo ra attribution signal, tiếp tục sinh reward. Càng được dùng nhiều thì accumulated yield càng lớn.
Và đây là lúc chuyện trở nên phức tạp theo hướng thú vị.
Khi reward gắn liền với retrieval, hành vi của contributor bắt đầu thay đổi. Họ không còn chỉ upload data cho có. Họ bắt đầu curate. Làm sạch. Chọn lọc. Giữ cho data có khả năng được truy xuất thật, có chất lượng thật, có relevance thật với domain mà model đang phục vụ. Bởi vì data chất lượng thấp không được retrieve nhiều, tức là không có yield. Quality không còn là khái niệm đạo đức mơ hồ. Nó là điều kiện sống còn của dòng thu nhập.
Và từ đó xuất hiện một thứ nghe rất tài chính: moat từ specialization.
@OpenLedger đặc biệt nhấn mạnh Datanets cho các domain chuyên biệt, finance, healthcare, robotics, mobility. Khi data đi vào các domain hẹp đó, giá trị không còn đến từ việc có nhiều data. Nó đến từ việc có đúng data. Data tài chính độc quyền với đầy đủ context và provenance sạch thì không dễ thay thế. Model muốn chạy tốt trong domain đó thì phải quay lại đúng Datanet đó. Contributor trong Datanet đó có một loại moat tự nhiên mà không cần phải xây tường hay patent gì cả.
Mình nghĩ đây là phần ít được nói đến nhất trong câu chuyện về data economy.
Phần lớn discourse hiện tại xoay quanh "ai sở hữu data", ai có quyền dùng data, ai nên được trả tiền. Nhưng câu hỏi sâu hơn là: cơ chế nào khiến việc "được trả tiền" trở thành hiện thực liên tục chứ không chỉ là một lần duy nhất? OpenLedger xây vòng hồi quy giá trị như một cơ chế hạ tầng, không phải như một feature UI. Mỗi interaction trong hệ thống đều là một monetizable event cho contributor. Đó là lý do họ mô tả $OPEN token không phải là governance token đơn thuần, mà là thứ distribute reward dựa trên usage thật trong attribution trail.
Theo thiết kế của họ, toàn bộ 51.7% token supply được phân bổ cho community, gắn với việc đóng góp vào hệ sinh thái thật sự. Không phải vì họ muốn có narrative đẹp, mà vì đó là cách duy nhất để vòng hồi quy giá trị hoạt động được. Nếu reward không đủ, contributor không có động lực duy trì quality. Nếu contributor không duy trì quality, retrieval rate giảm. Nếu retrieval rate giảm, model output kém đi. Cả hệ thống tự sụp.
Nhưng mình không muốn bài này kết thúc ở điểm lạc quan quá.
Có một tension thật sự trong mô hình này. Khi reward trở nên rõ ràng và đo được, rủi ro farming xuất hiện. Người ta có thể tối ưu hóa không phải cho truth mà cho attribution signal. Upload data được thiết kế để được retrieve nhiều, nhưng không nhất thiết phải là data tốt nhất. Đây là bài toán mà mọi incentive system đều phải đối mặt, và OpenLedger không phải ngoại lệ.
Và còn một điểm khác: yield của data không cố định. Data có thể lỗi thời. Domain có thể thay đổi. Model được train trên Datanet đó có thể không còn được dùng nữa. Vậy thì dòng yield đó co lại. Không giống trái phiếu chính phủ với coupon cố định, data yield là thứ phụ thuộc vào một hệ sinh thái mà bạn chỉ kiểm soát được một phần.
Mình nghĩ đây là lý do cách nói "data là tài sản tạo yield" cần được hiểu đúng hơn là "data là tài sản tạo yield trong một hệ thống có traceability và demand thật". Yield không nằm trong data một mình. Nó nằm ở vòng hồi quy giá trị: contribution đúng chỗ, retrieval đủ tần suất, attribution đủ minh bạch, reward đủ để duy trì hành vi curation.
Cái OpenLedger đang xây không chỉ là một blockchain có Proof of Attribution. Nó đang cố tạo ra điều kiện để vòng lặp đó tự sustain được theo thời gian. Còn thực tế nó có làm được không thì phụ thuộc vào những thứ khó đo hơn nhiều: liệu contributor thật sự có động lực curation lâu dài hay không, liệu attribution engine có đủ chính xác để phân biệt data quality thật hay không, và liệu demand cho specialized AI model có đủ lớn để giữ Datanets luôn active?
Câu hỏi đó mình vẫn chưa có câu trả lời.