Data attribution không phải missing layer của AI economy. Nó là lớp mà OpenLedger đang cố giữ lại, ngay cả khi điều đó làm mọi thứ chậm hơn, khó hơn, và ít “đẹp” hơn trên dashboard.
Đây chính là khoảnh khắc mình phải dừng lại khi đọc docs của OpenLedger. Không phải vì vấp thuật ngữ. Mà vì một giả định quen thuộc bị lật ngược. Output inference vẫn được trả cho người dùng, nhưng reward có thể không được trả cho bất kỳ ai nếu attribution trace không đạt chuẩn. Không có câu giải thích đạo lý. Không có lời hứa tối ưu sau. Chỉ là một luật chơi. Và luật đó nói rất rõ hệ thống này không ưu tiên tốc độ hay cảm giác trơn tru ban đầu. Nó ưu tiên việc nhớ.
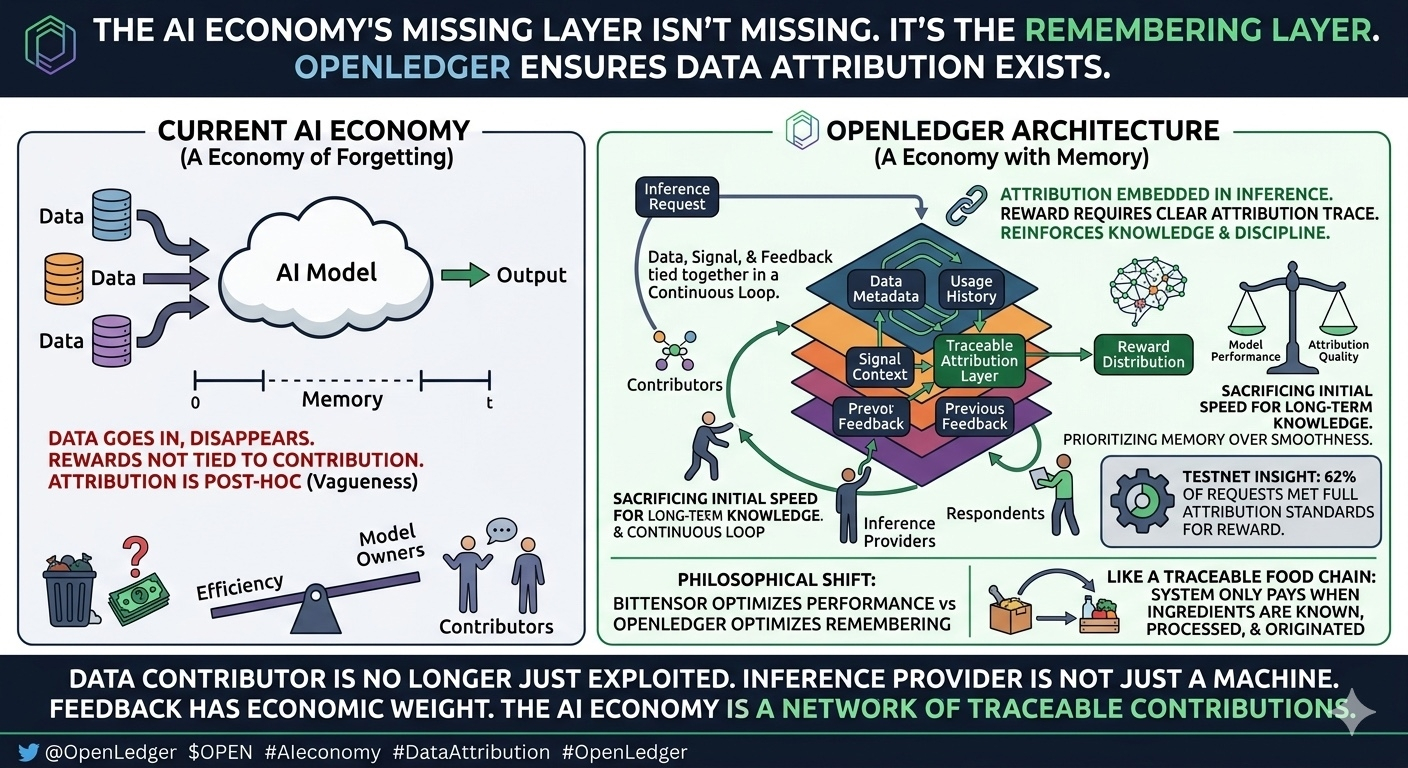
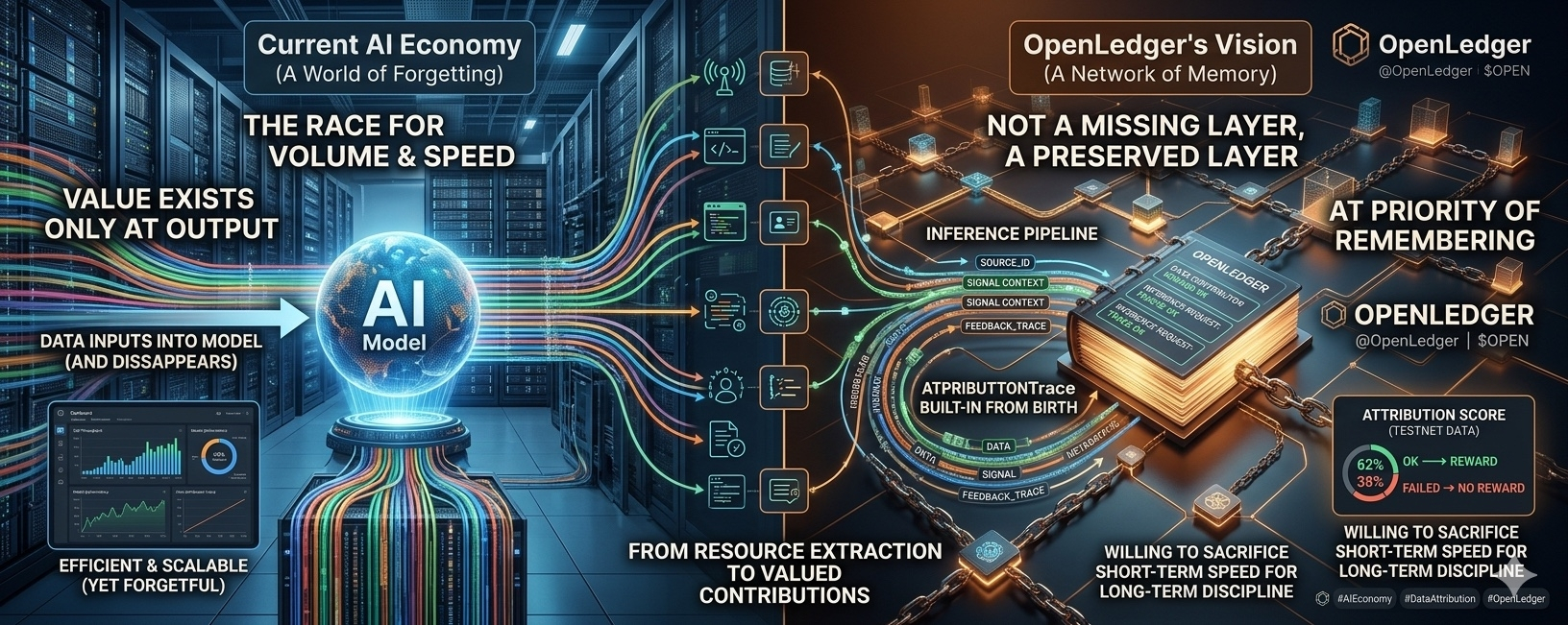
Phần lớn AI economy hiện nay được xây trên một sự quên lãng có chủ đích. Data đi vào model rồi biến mất. Signal giúp model tốt hơn nhưng không để lại dấu. Feedback tồn tại như một hành vi phụ, không gắn với dòng tiền. Giá trị chỉ được nhìn thấy ở output. Và quyền lực tập trung vào nơi sở hữu model. Cách này hiệu quả. Nhanh. Scale tốt. Nhưng nó tạo ra một nền kinh tế không có ký ức. Ai đóng góp điều gì trở thành câu hỏi không cần trả lời.
OpenLedger không chấp nhận điều đó. Và điểm tích cực của họ nằm ở chỗ này. Họ không cố vá attribution vào cuối pipeline. Họ đặt nó ngay trong kiến trúc inference. Data, signal và feedback không được coi là ba lớp độc lập. Chúng bị buộc phải đi cùng nhau trong một vòng lặp liên tục. Mỗi inference request mang theo metadata về nguồn dữ liệu, lịch sử sử dụng, ngữ cảnh signal và phản hồi trước đó. Attribution xuất hiện từ lúc inference được sinh ra, không phải lúc chia tiền.
Điều này làm hệ thống nặng hơn. Nhưng đổi lại, nó tạo ra một loại kỷ luật mà AI economy hiện tại rất thiếu. Khi reward chỉ được phân phối nếu trace đủ rõ, hành vi của người tham gia tự động thay đổi. Contributor có động lực cung cấp data có bối cảnh, không chỉ số lượng. Inference provider buộc phải quan tâm tới chất lượng attribution, không chỉ throughput. Người phản hồi không còn là vai phụ vô hình. Feedback trở thành một thành phần có trọng lượng kinh tế.
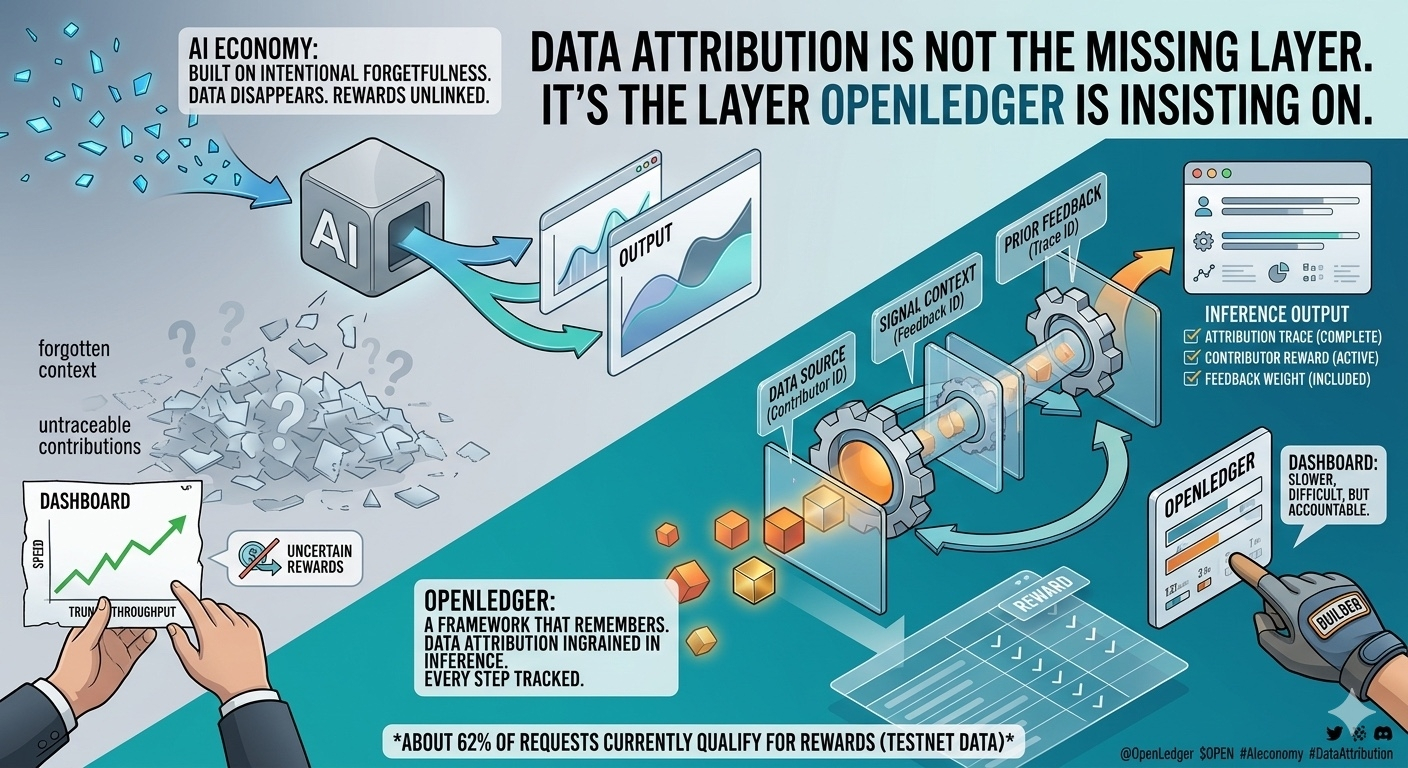
Có một con số trong tài liệu testnet mà mình cho là mang tính xây dựng, dù không hề “đẹp”. Chỉ khoảng 62 phần trăm inference request đủ điều kiện attribution hoàn chỉnh để kích hoạt reward distribution. Nghĩa là gần 4 trên 10 request bị loại khỏi vòng chia thưởng. Nhìn từ bên ngoài, đây có thể bị xem là kém hiệu quả. Nhưng nhìn từ bên trong, đây là tín hiệu cho thấy hệ thống đang thực sự lọc. Nó cho thấy OpenLedger sẵn sàng hy sinh tăng trưởng ngắn hạn để thiết lập một chuẩn hành vi dài hạn.
Khi đặt cạnh Bittensor, sự khác biệt không nằm ở việc ai tốt hơn. Mà ở triết lý nhớ. Bittensor tập trung tối ưu model performance và alignment giữa miner với validator. Data contributor hoàn thành vai trò khi model được huấn luyện xong. OpenLedger thì kéo contributor quay lại vòng inference. Data không chỉ huấn luyện. Nó tiếp tục tạo giá trị trong từng output. Đây là một lựa chọn có tính xây dựng cho một nền kinh tế mở, nơi nhiều lớp giá trị có thể cùng tồn tại.
Có thể hình dung OpenLedger như một hệ thống truy xuất nguồn gốc trong chuỗi cung ứng. Món ăn cuối cùng vẫn quan trọng. Nhưng hệ thống chỉ trả tiền khi biết nguyên liệu đến từ đâu, đi qua những ai, và được xử lý thế nào. Không phải vì đạo đức. Vì nếu không làm vậy, không thể xây dựng niềm tin giữa những người chưa từng quen biết.
Điểm tích cực lớn nhất của OpenLedger là họ không né mâu thuẫn nội tại. Permissionless nhưng vẫn cần attribution quality. Decentralization nhưng phải có cơ chế đánh giá signal và feedback. Họ thừa nhận giai đoạn đầu, ngưỡng attribution sẽ do core team thiết lập trước khi chuyển sang governance on-chain. Điều này không được giấu. Nó được nói thẳng. Và chính sự thẳng thắn đó làm kiến trúc này có cơ hội trưởng thành thay vì sụp đổ vì kỳ vọng sai.
Nếu giả định của OpenLedger đúng, hệ quả rất đáng chú ý. Data contributor không còn là nguồn lực bị khai thác một lần. Inference provider không chỉ là máy chạy. Feedback không còn là tiếng nói yếu. AI economy khi đó không xoay quanh model owner, mà xoay quanh một mạng lưới những đóng góp có thể truy vết và định giá.
Nếu giả định này sai, hệ thống sẽ chậm, đắt và khó dùng. Nhưng ít nhất, nó sai một cách rõ ràng. Có trace. Có nguyên nhân. Có trách nhiệm. Điều đó tốt hơn rất nhiều so với một nền kinh tế vận hành trơn tru nhưng không ai biết ai đang tạo ra giá trị.
OpenLedger không hứa hẹn một tương lai dễ chịu. Họ chỉ đặt ra một điều kiện: nếu AI muốn trở thành một nền kinh tế mở, nó phải nhớ. Nhớ dữ liệu. Nhớ signal. Nhớ cả những phản hồi khó chịu.
Không phải cuộc đua về model. Không phải cuộc đua về volume. Là cuộc đua xem ai đủ kiên nhẫn để xây ký ức cho hệ sinh thái của nó.