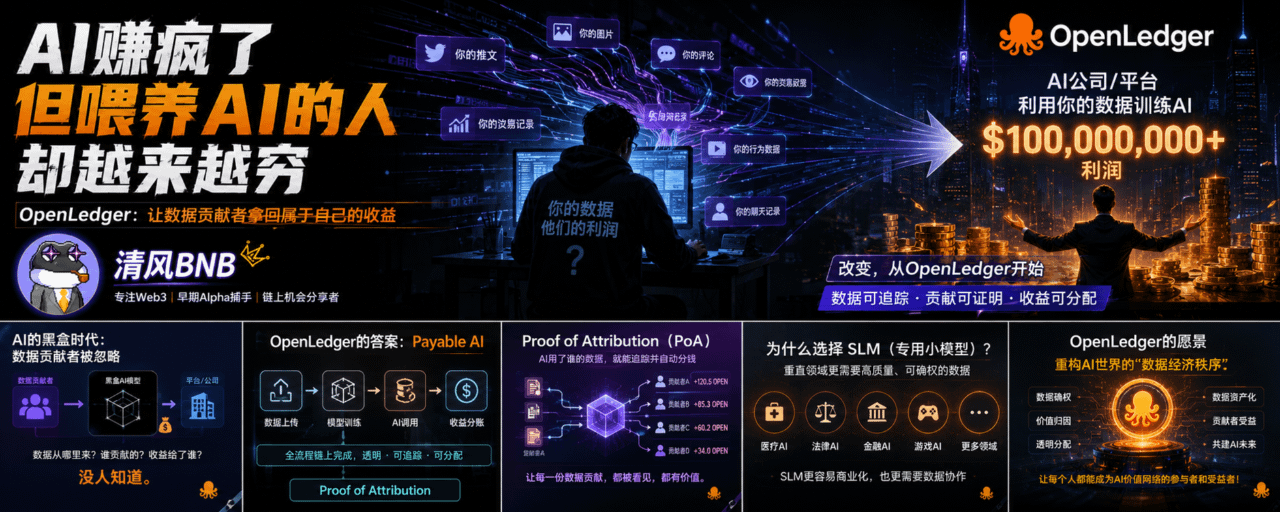

AI赚疯了,但喂养AI的人却越来越穷,反而那些做空BTC 和ETH的人盈利了
最近我越来越强烈地感觉到一件事:
AI正在改变世界。
但普通人, 可能正在变成AI时代里最廉价的“燃料”。
你每天发的推文、图片、交易记录、评论、聊天内容, 甚至你刷视频停留的那几秒, 都在被平台默默记录。
这些数据最后去了哪里?
大概率: 进了AI模型。
然后训练出新的AI产品, 再被大公司卖给全世界赚钱。
最离谱的是:
真正贡献数据的人, 几乎拿不到任何收益。
说白了, 整个AI行业现在最核心的问题, 根本不是模型够不够强。
而是:
“谁拥有数据创造的价值?”
我以前一直没认真思考过这个问题。
直到最近研究OpenLedger, 我才发现:
原来已经有人开始试图重构AI世界的“生产关系”了。
很多人第一次看到OpenLedger, 会以为它只是又一个:
“AI + 区块链”
项目。
但我越看越觉得, 它真正想解决的, 其实是AI行业里一个非常底层的问题:
AI用了谁的数据?
以及:
这些人该不该赚钱?
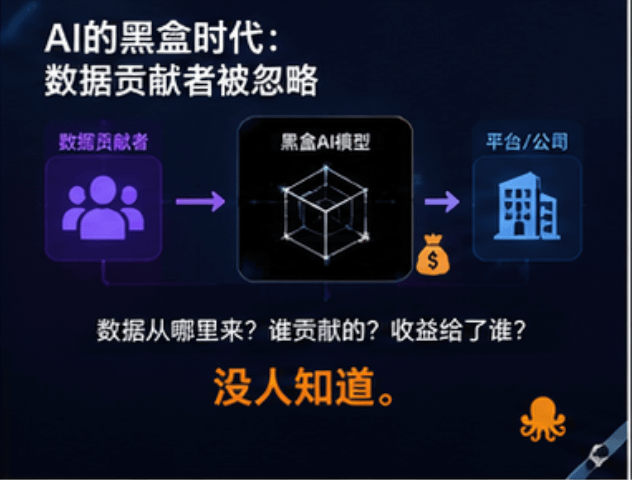
现在的大模型, 本质上都像黑盒。
你根本不知道:
数据来自哪里
哪些内容参与了训练
谁贡献了价值
收益又流向了谁
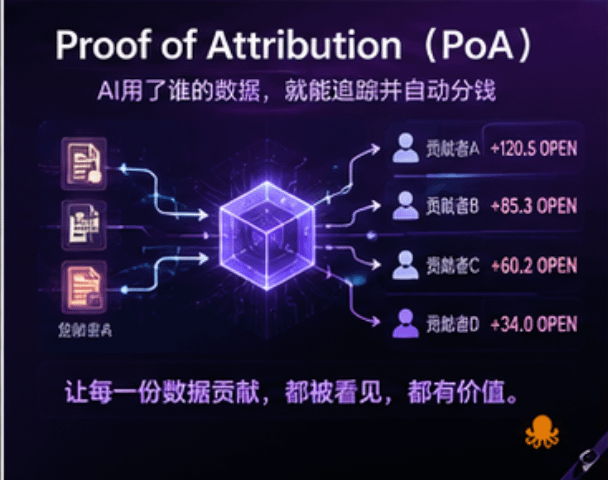
但OpenLedger提出了一个很有意思的概念:
Proof of Attribution。
简单理解:
AI如果用了你的数据, 系统就能追踪。
然后自动分账。
第一次看到这个机制的时候, 我脑子里冒出的第一个词其实是:
“AI版权系统”。
以前互联网时代, 平台最赚钱。
后来短视频时代, 内容创作者开始赚钱。
而AI时代, 真正值钱的东西, 可能会变成:
数据。
因为AI不是凭空诞生的。
每一个模型背后, 都需要海量数据喂养。
医疗AI需要病例数据。
金融AI需要交易数据。
游戏AI需要玩家行为数据。
法律AI需要判例数据。
问题是:
这些数据, 过去一直没有真正属于数据贡献者。
OpenLedger想做的, 其实是把这些“隐形贡献者”重新拉回价值分配体系。
这一点我觉得特别重要。
因为现在很多AI项目, 都在卷:
Agent
Meme
模型能力
推理性能
但很少有人去解决:
“数据到底属于谁”
这个问题。
而这恰恰可能是未来AI世界最大的矛盾。
你会发现:
AI越强, 数据越贵。
但现实却是:
普通人的数据, 正在越来越廉价。
甚至很多人根本不知道, 自己正在免费帮AI打工。
你发的内容, 你浏览的习惯, 你留下的评论, 都可能已经成了AI训练的一部分。
但收益和你没有任何关系。
这也是为什么, 我觉得OpenLedger的方向其实挺聪明。
它没有继续去和OpenAI那种巨头硬拼“大模型”。
而是选择了另一条路:
SLM。
也就是专用小模型。

比如:
医疗AI
法律AI
金融AI
游戏AI
这些垂直模型, 未来其实更容易真正商业化。
因为它们解决的是具体行业问题。
而这些行业最缺的, 恰恰就是:
高质量、可追踪、可确权的数据。
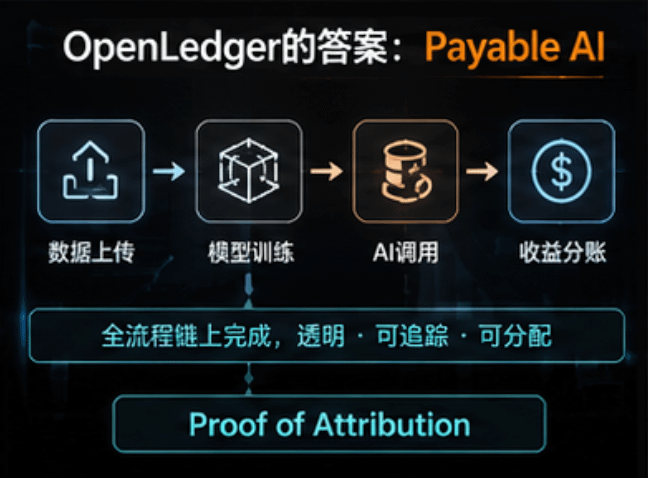
所以OpenLedger做了一个叫Datanet的东西。
你可以理解成:
“AI数据市场”。
不同领域的数据, 形成不同的数据网络。
模型开发者来这里获取数据。
AI应用调用模型。
而收益, 通过Proof of Attribution自动回流给贡献者。
这套逻辑最有意思的地方在于:
它第一次试图让AI世界里的“数据劳动”变得可计价。
以前的数据贡献, 是隐形的。
未来的数据贡献, 可能会变成一种资产。
这一点其实很像互联网早期。
最开始, 大家觉得内容不值钱。
后来发现:
流量值钱。
再后来发现:
注意力值钱。
而现在, AI时代可能会进入下一阶段:
数据值钱。
甚至我觉得, 未来最大的AI战争, 都未必是模型战争。
而是:
数据产权战争。
谁拥有数据, 谁就拥有AI时代的话语权。
OpenLedger现在做的事情, 某种程度上, 其实是在尝试建立:
AI世界里的“数据经济秩序”。
这件事最后能不能成, 现在没人知道。
毕竟AI行业变化太快了。
但至少它让我第一次认真意识到:
原来AI真正重要的, 可能不是模型本身。
而是:
那些一直被忽略的数据贡献者。
也许未来某一天, 普通人终于不再只是AI时代的“免费燃料”。
而是能够真正参与AI收益分配的人。
如果那一天真的来了,
那OpenLedger现在做的事情, 可能会比很多人想象得更重要。
