
i keep getting stuck on the adapter part inside @OpenLedger .
not the big model, not the whole AI chain pitch, not even the Datanet first. the adapter. that little temporary thing.
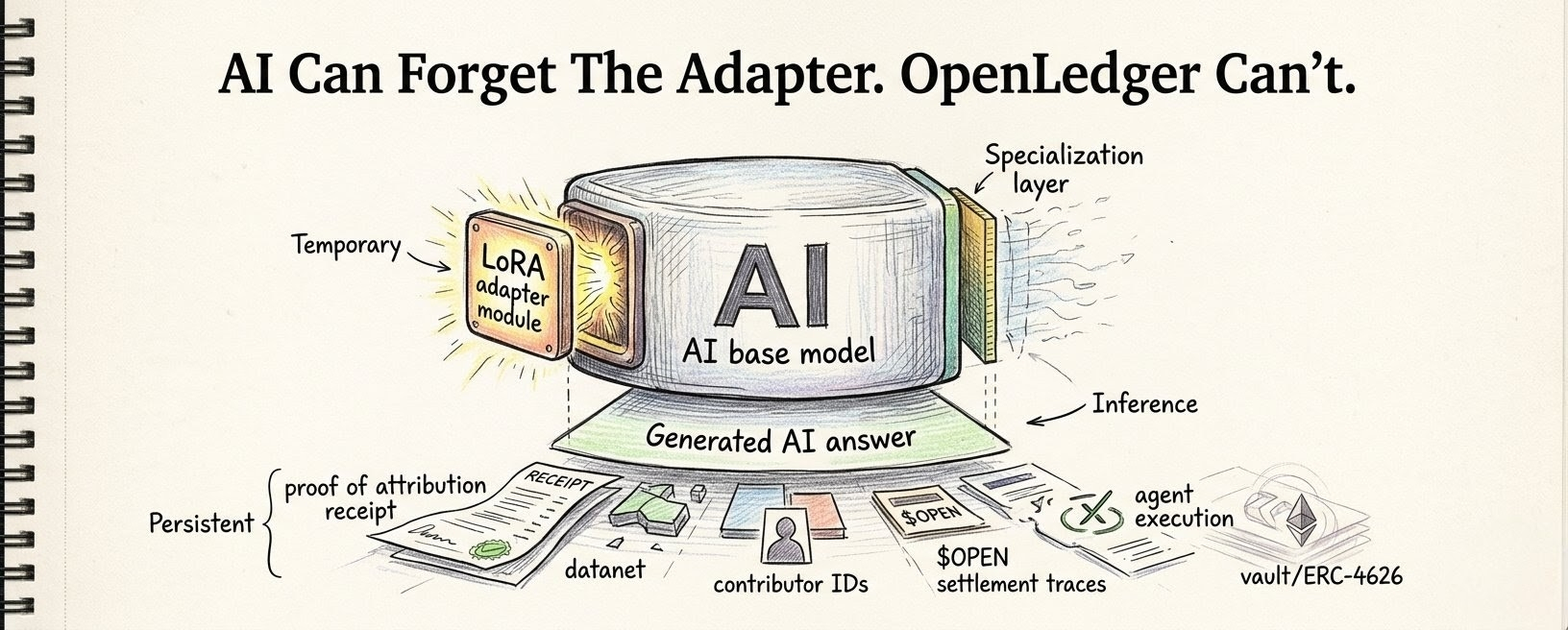
a base model is sitting there, too general to be useful for every specific job, and then a LoRA adapter gets pulled in through OpenLoRA like a borrowed shape. for one request, one narrow task, one moment where the model needs to become something else without becoming that thing forever.
that feels weirdly important because the openLedger adapter can leave, but the effect cannot.
that is the part my brain keeps circling around openLedger some ugly hour when everything starts looking more honest than it should. if a model only becomes specialized for a moment, and that moment produces value, then what exactly disappears when the adapter unloads? just the memory from the machine? the active weights? the compute pressure? or does the economic trail also get treated like it never happened?
it should not.
because if OpenLoRA lets a model temporarily wear specialization, then OpenLedger has to care about what that temporary shape did. the adapter may not stay in memory, but the answer still came through it. the inference still happened. some Datanet somewhere may have helped build that fine-tune. some contributor’s data may have sat underneath the behavior. some model creator may have packaged that specialization into something useful enough to be called when the query arrived.
temporary compute, permanent question.
on openLedger, the machine can call it efficient. fine. but efficiency is not the part that keeps bothering me. the part is what remains after the adapter is gone. OpenLoRA can make specialized model serving lighter, sure, but once lightweight specialization becomes normal, the model is no longer one stable thing in the way people casually imagine. thousands of adapters can exist around a base model, different tasks can pull different narrow capabilities on demand, and suddenly the answer is not coming from one clean place anymore.
so what answered me?
the base model? the adapter? the Datanet behind the adapter? the fine-tuning path? the person who uploaded a small chunk of useful data three weeks ago and forgot about it? or all of them, just unevenly?
that unevenness is where OpenLedger starts to feel less like an AI product and more like an accounting problem that refuses to go away. not accounting in the boring spreadsheet way. accounting as in, the system cannot let influence dissolve just because the response looked seamless.
a query comes in openLedger, and the model does not need to become permanently specialized. it just loads the LoRA adapter, bends itself toward the requested task, produces the answer, then the adapter can be released. from the user side, nothing dramatic happened. maybe they saw a better answer. maybe faster. maybe more domain-specific. maybe they never even knew an adapter was involved.
but under OpenLedger, that invisible adapter path matters. it has to matter.
because if the adapter changed the output, then it touched value. and if it touched value, Proof of Attribution cannot just shrug and say, well, the adapter is gone now. that would be stupid. that would be the same old AI problem wearing a more efficient jacket.
the adapter leaving memory should not erase the debt it created.
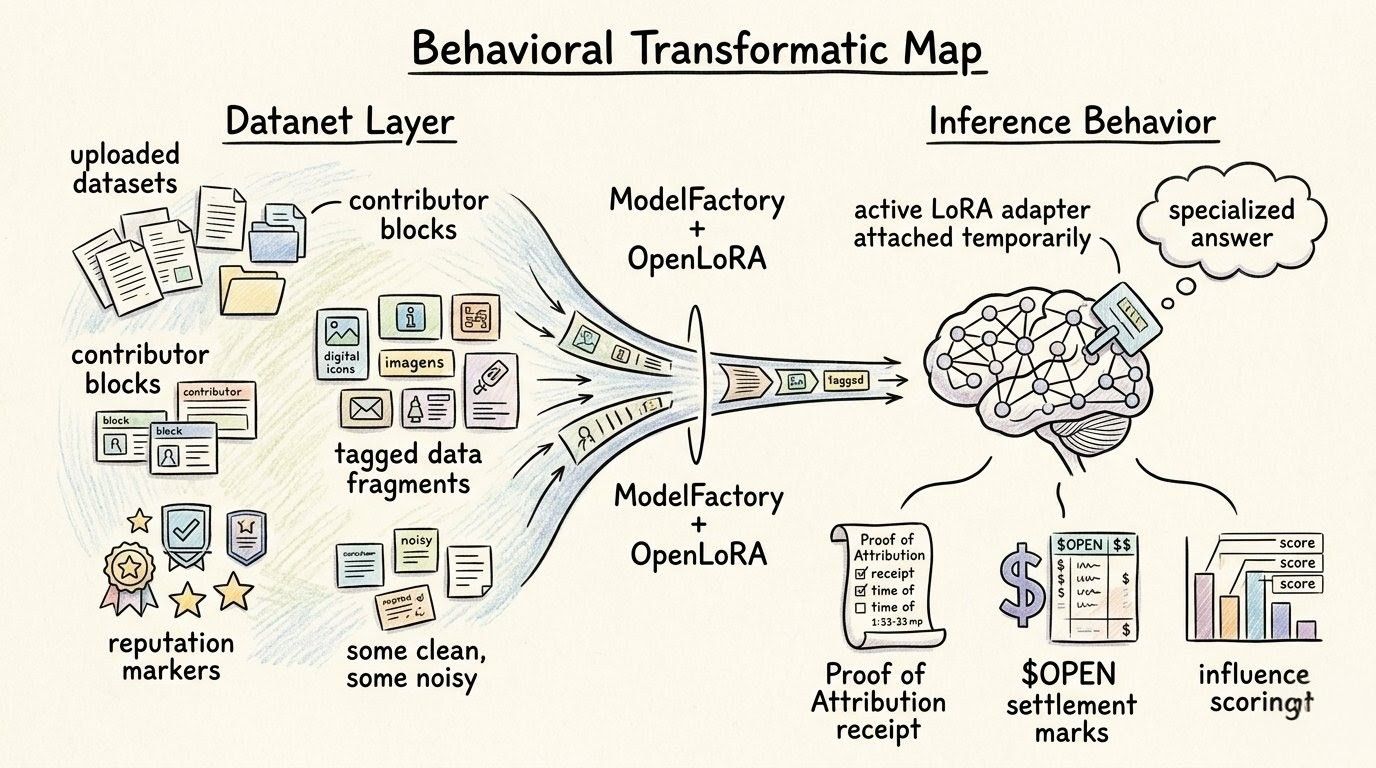
and once i think about openLedger like that, ModelFactory starts looking different too. not as a nice builder panel or some friendly tool where people make models because buttons are easier than infrastructure. but the longer i sit with it, ModelFactory feels less like a builder panel and more like the place where approved Datanet material starts getting pressed into behavior. data stops being a file, or a contribution, or some nice clean entry in a openLedger, and starts becoming part of a model’s habits.
that is not a small transition.
because people talk about data like it becomes valuable the second it is uploaded. but OpenLedger’s structure makes that feel too easy. a Datanet contribution can sit there looking neat, tagged, validated, maybe useful, maybe not. but until it moves into training, until it shapes a fine-tune, until that fine-tune becomes an adapter path that actually gets used during inference, what did it really do?
maybe nothing yet. maybe it is waiting.
that waiting is important because it stops the whole openLedger system from pretending every contribution is equal just because every contribution arrived. the adapter is like a stress test for that lie. when OpenLoRA pulls in specialization for a specific task, it quietly asks which earlier inputs made this specialization worth loading at all.
which openLedger Datanet made it sharper? which data polluted it? which contributor helped and which one just added weight?
not every contribution deserves to follow the adapter into reward.
that sounds harsh, but a real openLedger AI economy probably has to be harsh somewhere. otherwise Datanets become junk drawers with incentives. everyone uploads, everyone expects credit, everyone calls it ownership, and the model gets worse while the dashboard looks busy. OpenLedger cannot afford that if Proof of Attribution is supposed to mean anything beyond polite reward distribution.
the useful data has to stand out. the weak data has to lose gravity.
and maybe that is why contributor reputation, influence scoring, penalty logic, and future reward reduction are more interesting than the nice “get paid for your data” line. rewards are easy to sell. judgment is harder. but without judgment, attribution becomes charity. and AI does not need charity inside its infrastructure. it needs a memory that can say yes, no, less, more, not again.
i keep thinking about the openLedger moment after inference.
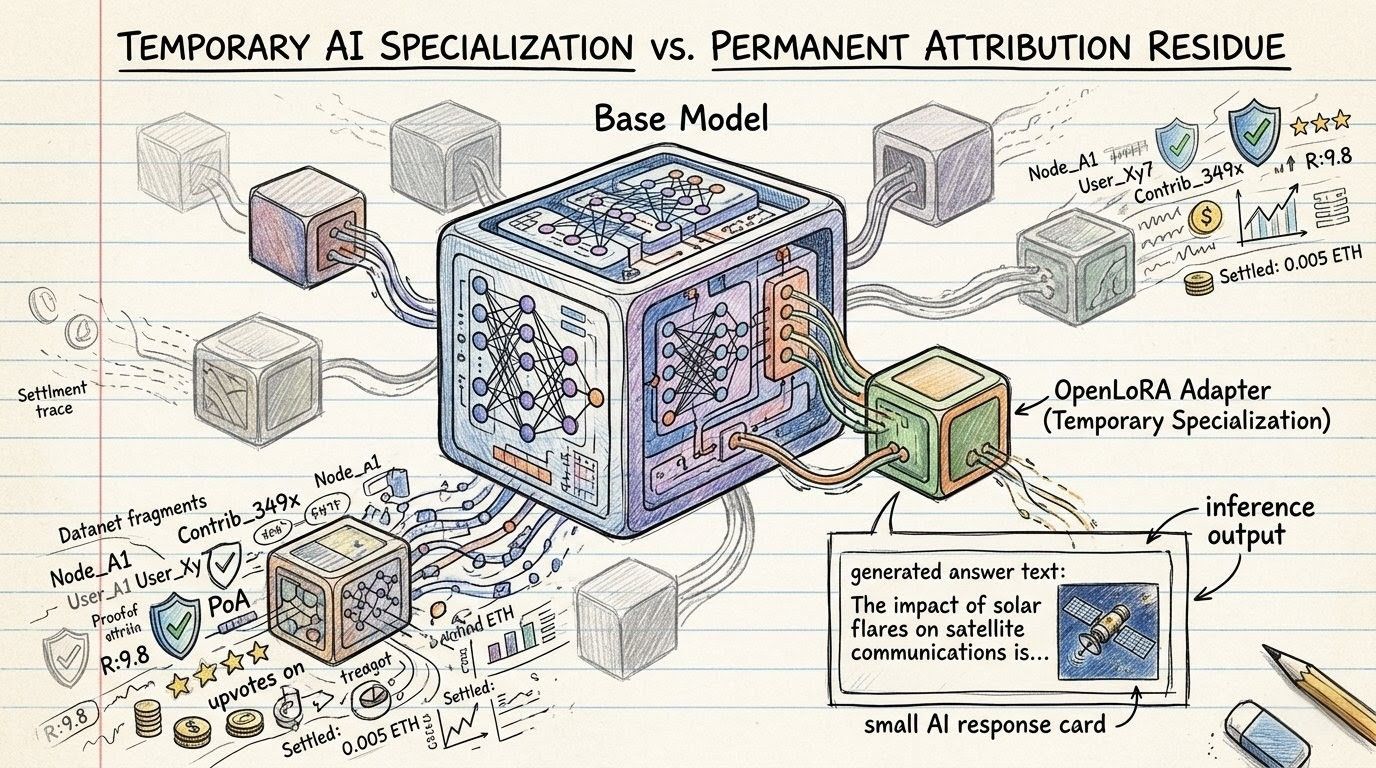
the answer is already out. the user is done reading. the adapter may already be unloaded. the GPU memory is freed for something else. clean from the outside. quiet. no drama.
but OpenLedger still has to ask the annoying questions.
which adapter carried this? which model path served it? which Datanet influenced it? did ModelFactory turn that source material into the fine-tune? did some contributor deserve a piece of the value? did some input deserve less trust next time? where does openLedger ($OPEN ) move if usage became something billable, rewardable, or worth settling?
this is the part that makes “temporary specialization” feel less temporary.
because openLedger OpenLoRA may reduce the cost of serving specialized intelligence, but Proof of Attribution has to make sure the economic residue does not evaporate with the adapter. otherwise the system gets the efficiency but loses the point.
and once usage turns into reward, cost, fee, or participation, openLedger is where that residue stops being abstract. it moves. not magic. not moon math. just the settlement language sitting where AI usage stops being a clean output and becomes something the system has to account for.
and then agents make it worse.
not worse as in bad. worse as in harder to ignore.
if OctoClaw or some OpenLedger agent uses that adapter-shaped answer to research, configure a workflow, prepare a trading action, maybe touch vault logic later, then the answer is no longer just an answer. it becomes part of a decision path. one adapter-shaped inference can push an agent toward an action. one Datanet-shaped inference can affect what gets executed. and once execution enters the room, especially around capital, the architecture cannot be casual anymore.
an agent does not get to say “the model felt right.”
what model, what adapter, what source trail, what settlement path?
on openLedger, ERC-4626 becomes less boring in that frame. if an agent moves around vault logic, deposits and shares and withdrawals cannot be treated like loose ideas floating around a prompt. they need accounting. they need standards. and if the agent’s decision was shaped by a temporary adapter, then even that temporary path becomes part of the capital story.
same with the openLedger EVM bridge. not because bridging sounds nice. more like… attribution cannot stay in one room while capital settles in another. OpenLedger’s AI work cannot stay sealed inside its own little place if agents, vaults, contracts, and liquidity are going to matter. attribution may begin around data and models, but settlement needs rails. otherwise the system proves influence in one place while value moves somewhere else pretending nothing happened.
that split would be ugly.
maybe that is why the openLedger adapter keeps bothering me. because it is small enough to look technical, but it exposes the whole OpenLedger problem. AI keeps becoming more modular, more temporary, more composable. models borrow capabilities. agents borrow context. workflows borrow liquidity. everything is moving through something else for a moment.
but value still needs a place to land.
maybe the whole bet is not only data, models, and agents becoming monetizable. it is whether these short-lived interactions can leave enough trace to be priced. a Datanet contribution can matter later. a ModelFactory fine-tune can become a usable adapter. an OpenLoRA call can shape one inference. an agent can act on top of that. openLedger can sit inside the cost, fee, reward, or participation layer when usage needs settlement.
small actions, long shadows.
and the funny thing is, users may never care about most of this. they will ask for the thing, receive the thing, move on. that is normal. nobody wants to inspect the plumbing every time water comes out.
but openLedger infrastructure is exactly the stuff that matters when nobody is looking.
the adapter loads, answers, leaves.
the attribution should stay.
inside openLedger (#OpenLedger ), that tiny sequence is not just optimization. it is the thing i keep coming back to: AI can borrow intelligence for a moment, but it should not be allowed to forget who made that moment valuable.