

OpenLedger didn’t grab me instantly.
Maybe that is because I have become careful with anything that puts AI and blockchain in the same sentence. The market has heard that combination too many times now. A lot of projects arrive with big claims, polished pages, and words that sound important until you try to understand what is actually being built.
At first, I looked at OpenLedger with that same caution.
OpenLedger became more interesting only when I stopped paying attention to the label and started looking at the question behind it.
Who gets rewarded when AI becomes valuable?
That question is simple, but it opens up a much bigger problem.
AI models are not created in isolation. They are shaped by data, examples, corrections, open-source work, domain knowledge, user feedback, and many invisible contributions. But once a model becomes useful, most of that history disappears. The platform gets attention. The model becomes the product. The contributors who helped create the value often remain in the background.
That is where OpenLedger started to make sense to me.
It is not just trying to place AI beside blockchain for the sake of narrative. The project is trying to build an economic layer around data, models, and agents, where contribution can be tracked and rewarded instead of being absorbed silently into the system.
That is what made me continue researching it.
Not hype.
Not the token.
The attribution problem.
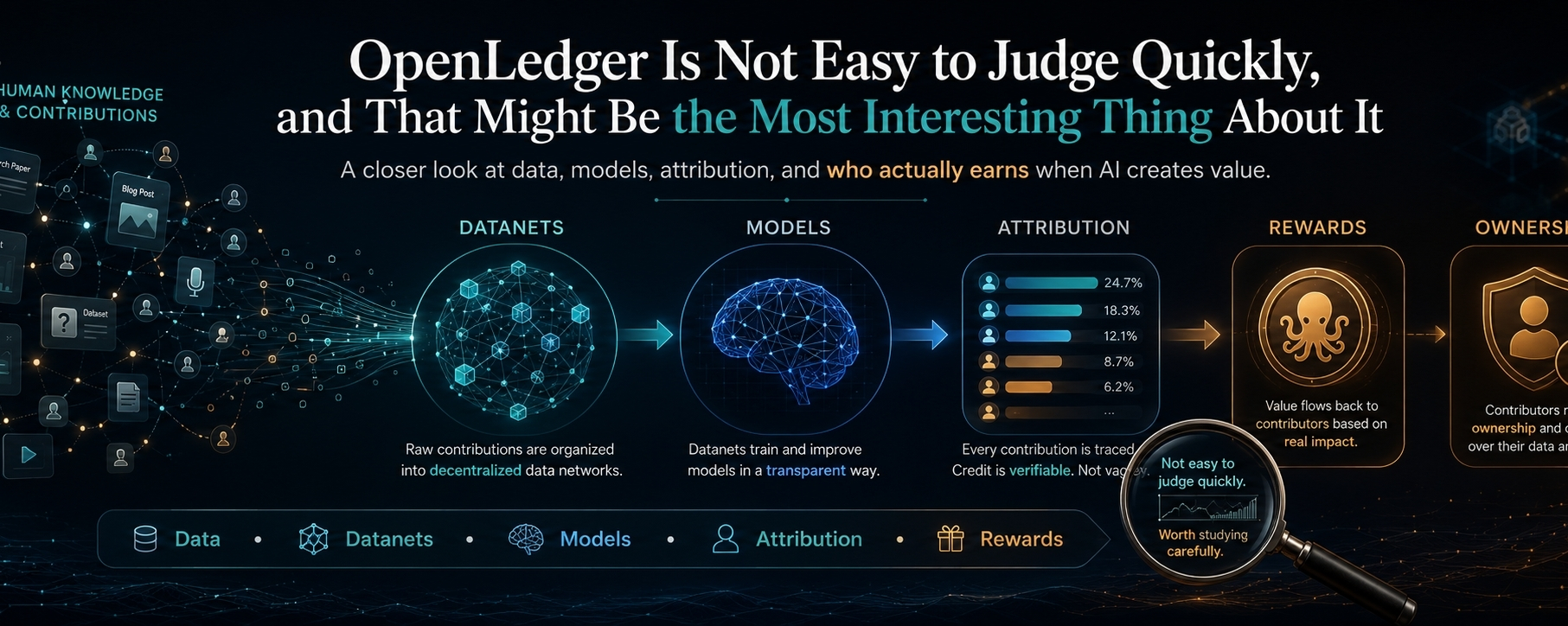
OpenLedger is built around the idea that data should not be treated as a one-time input that loses its identity after being used. If a dataset helps train a model, and that model later creates value, the original contribution should not completely disappear from the economic picture.
That sounds fair.
It is also very hard to execute.
AI needs data, but not all data has the same value. A general model can answer broad questions, summarize text, write basic code, and handle everyday tasks. But specialized fields are different. Healthcare, finance, law, cybersecurity, research, trading systems, on-chain analysis, and technical support need better information. They need accurate data. They need context. They need expert input.
OpenLedger focuses on that specialized layer.
Instead of treating all data as equal, it introduces Datanets. These are basically specialized data networks built around specific topics or use cases. Contributors can add data, and that data can later be used to train or fine-tune models.
This part is important because the future of AI may not only depend on larger models. It may depend on better smaller models trained on cleaner, more relevant data.
That is where OpenLedger has a real angle.
The project seems to understand that specialized AI needs more than compute. It needs an incentive system for people who hold useful knowledge. If contributors have no reason to share high-quality data, then the system struggles before it even starts.
OpenLedger tries to solve this with Proof of Attribution.
This is the part I kept coming back to while studying the project. Proof of Attribution is meant to connect model outputs back to the data that influenced them. If a model becomes useful, the system should be able to identify which contributions mattered and reward those contributors.
That is the theory.
In practice, this is probably the hardest part of the entire design.
AI models do not behave like simple databases. They do not always pull one exact piece of data and return it. They generalize. They combine patterns. They compress information. They produce outputs based on many signals at once.
So attribution is complicated.
If ten people upload similar data, who deserves the reward? If one dataset improves the model generally, but another helps with a specific output, how is that measured? If someone uploads low-quality data just to farm rewards, how does the system detect that?
These are not side questions.
They are central to whether OpenLedger works.
OpenLedger also has ModelFactory, which is designed to help users create specialized models from approved datasets. I liked this part because it makes the project feel less abstract. Instead of only talking about data ownership, it gives builders a way to actually use that data.
That matters.
A contribution economy is not useful if nothing meaningful gets built from the contributions.
ModelFactory gives OpenLedger a practical layer. It allows the data side and model side to connect. Contributors bring data. Builders use that data to fine-tune models. Users can later interact with those models. Rewards are supposed to flow back based on attribution.
That loop is the heart of the project.
OpenLedger also includes OpenLoRA, which is more technical but still important. If the ecosystem eventually has many specialized models, serving all of them separately would become expensive and inefficient. OpenLoRA is meant to make it easier to serve many fine-tuned models without needing a completely separate infrastructure setup for each one.
This is one of those details that may not sound exciting, but it matters in practice.
Good infrastructure often looks boring from the outside.
OpenLedger seems to be making a practical decision here. It is not pretending that every part of AI should happen on-chain. Training and inference are heavy processes. Putting everything directly on-chain would be unrealistic.
The blockchain layer is more useful for coordination, records, ownership, payments, and rewards.
That makes sense to me.
A chain should not pretend to be a GPU cluster. It should handle the parts where transparency and economic settlement matter.
OpenLedger feels more grounded when viewed from that angle.
It is not only asking, “Can AI use blockchain?”
It is asking, “Can blockchain help track who contributed value to AI?”
That is a better question.
What separates OpenLedger from many AI crypto projects is not simply that it mentions AI. Everyone does that now. The difference is that OpenLedger is focused on contribution economics.
Who supplied the data?
Which data improved the model?
Who should earn when that model is used?
Can data become a productive asset instead of disappearing after upload?
These are specific questions. I prefer that over broad promises.
Still, a specific idea does not automatically become a working system.
The biggest challenge is quality.
OpenLedger depends on useful data. If Datanets are filled with strong, verified, domain-specific information, the network becomes more valuable. If they are filled with copied, outdated, weak, or spammy data, the whole system becomes noisy.
Crypto incentives make this even harder.
Whenever rewards exist, people optimize for them. Some contributors will bring real value. Others will try to farm the system. That is not an insult to OpenLedger. It is just how incentive systems work.
So the project has to prove that it can reward quality better than quantity.
That is a difficult balance.
One strong dataset from a serious contributor should matter more than thousands of weak uploads. But measuring that fairly requires strong validation, clear rules, and attribution that contributors can trust.
If OpenLedger gets this wrong, the reward layer could attract noise instead of expertise.
That is my biggest concern.
The second concern is transparency.
If people are contributing data and expecting rewards, they need to understand how those rewards are calculated. They do not need every technical detail hidden behind complex math. But they do need enough visibility to believe the system is fair.
Trust matters here.
If contributors feel rewards are random, delayed, or controlled by unclear processes, they will not stay.
OpenLedger’s whole model depends on people believing that contribution can be measured honestly.
The token also needs real demand behind it.
OPEN has a role inside the ecosystem. It is used for fees, rewards, governance, and network activity. That gives it more purpose than a token that exists only for market attention.
But utility on paper is not the same as sustainable demand.
OpenLedger needs real usage. Builders need to create useful models. Contributors need to provide valuable data. Users need to pay for outputs that actually matter. Communities need to participate in governance for reasons beyond speculation.
Otherwise, activity can become circular.
People farm rewards. People chase campaigns. People trade the token. The numbers move, but the actual product does not become essential.
That is a risk for every tokenized infrastructure project.
OpenLedger is not exempt from it.
The healthiest signal would be simple: useful models built from useful datasets, with contributors earning because their data genuinely improves the system.
That is the loop I would want to see grow.
There are still areas that feel unfinished.
I would like to see more clear examples of Datanets producing better models. I would like to see more transparency around bad data filtering. I would like to see how attribution works in real-world cases, not only in theory. I would also like to see whether serious builders continue using the platform after early incentives cool down.
That last part matters a lot.
A project can look active during reward campaigns and still struggle later.
Real adoption is different.
It shows up when people use the system because it solves a problem, not only because there may be a reward attached.
OpenLedger also has governance questions to answer over time. Governance in this kind of project is not just about small upgrades. It can affect data standards, reward formulas, model rules, ecosystem incentives, and disputes between contributors.
That is a lot of responsibility.
If governance becomes dominated by short-term token holders, it could create problems. If it becomes too centralized, it weakens the open contribution story. Finding the right balance will not be easy.
There is also the issue of off-chain trust.
Even if ownership and rewards are recorded on-chain, many parts of AI still happen elsewhere. Training, storage, inference, validation, and interfaces all introduce trust assumptions. That is normal, but it should be acknowledged clearly.
OpenLedger does not need to be perfectly decentralized from day one.
But it does need to be honest about which parts are transparent, which parts are controlled by infrastructure operators, and which parts still require trust.
My opinion changed while researching it.
At first, I expected another AI token project with a strong narrative and not much underneath. But the more I looked at OpenLedger, the more I saw a project trying to work on a real structural issue.
AI needs better data.
Better data needs better incentives.
Better incentives need attribution.
Attribution needs infrastructure that people can inspect and trust.
That logic makes sense.
What I am not ready to say is that OpenLedger has solved the problem. The design is thoughtful, but execution will decide everything. The project has to prove that contributors will bring valuable data, builders will create useful models, users will pay for them, and rewards will feel fair enough to keep people involved.
That is a lot to prove.
But I would rather follow a project with hard unanswered questions than one with easy slogans.
OpenLedger sits in an interesting middle ground. It is not just a data marketplace. It is not only a model platform. It is not only an AI chain. It is trying to connect these pieces into an economy where contribution does not disappear once the model becomes useful.
That is why I find it worth watching.
Not because it guarantees anything.
Not because the token exists.
Not because the branding sounds advanced.
OpenLedger is interesting because it asks a question the AI industry still has not answered properly: