
Everyone keeps putting OpenLedger into the same category:
“another AI chain.”
I think that misses what might actually matter here.
Crypto loves simple narratives. AI + blockchain + compute is easy to understand. GPUs are scarce, inference costs money, and investors naturally gravitate toward infrastructure stories because they feel concrete.
But the deeper problem in AI may not be compute.
It may be attribution.
Not social media attribution. Economic attribution.
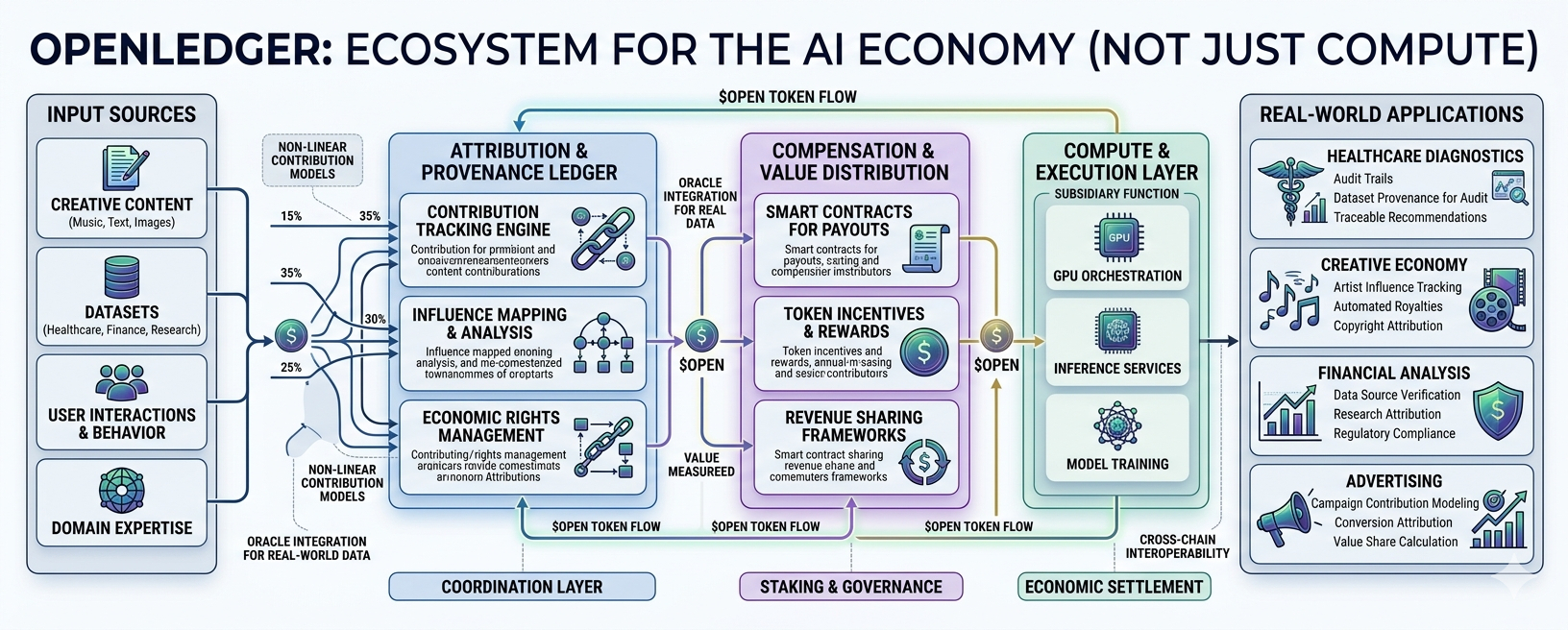
Who contributed the data?
Who influenced the output?
Who should get compensated when AI generates value?
And how do you track all of that once AI becomes embedded into real industries?
That’s the part most people still underestimate.
When I look at OpenLedger, I don’t really see “an AI chain” in the traditional sense. I see a project trying to build something closer to an accounting layer for AI economies.
And honestly, that might end up being more important than compute itself.
Because here’s the uncomfortable truth nobody likes talking about:
AI today is incredibly good at absorbing value, but still terrible at distributing it.
Models are trained on oceans of human knowledge, creative work, behavioral data, research, and domain expertise. Then all of that gets compressed into outputs that look magical on the surface — while the people underneath the stack become increasingly invisible.
Compute helps models run faster.
It doesn’t solve the question of who deserves credit.
That becomes a real issue once AI starts touching industries where accountability matters.
Take healthcare.
People imagine AI doctors and automated diagnostics as a compute problem. Faster models, bigger models, better models.
But hospitals don’t just care about speed. They care about traceability. They care about where recommendations came from, what datasets influenced them, and whether decisions can actually be audited later.
At some point the conversation stops being technical and becomes economic and legal.
Provenance matters.
Advertising has the same problem in a different form.
The entire digital ad industry already revolves around attribution wars. Everyone wants to know what caused the conversion, who influenced the customer, who deserves payment.
Now imagine AI systems generating campaigns, optimizing targeting, writing copy, adapting creatives, and learning from millions of interactions in real time.
Suddenly the question becomes messy:
Whose data created the value?
Whose creativity shaped the output?
Who gets paid?
Without attribution, AI mostly concentrates value into the companies controlling the models.
With attribution, AI starts looking more like an economy.
Finance is similar.
An AI research agent doesn’t create intelligence out of thin air. It pulls from filings, analyst reports, historical patterns, market behavior, and proprietary data. Institutions eventually need to know where insights came from — not because it sounds idealistic, but because regulators and risk teams demand accountability.
And honestly, music might be the clearest example of all.
The internet already broke creative attribution once. Streaming partially rebuilt it. AI is about to stress the system again.
When models generate songs influenced by thousands or millions of existing works, the argument is no longer “can AI make music?”
It becomes:
“How do we think about influence, ownership, and compensation in a world where creativity becomes probabilistic?”
There may never be a perfect answer.
That’s the important part.
I think a lot of people hear “attribution” and imagine some clean mathematical system where every contribution gets measured perfectly and everyone gets paid fairly.
Reality probably won’t look like that.
Human creativity is messy. Data influence is messy. Models are nonlinear. Contributions overlap constantly. Perfect attribution may be impossible.
But imperfect attribution could still matter enormously.
Because right now the default system is basically no attribution at all.
And that usually means value flows upward toward whoever owns the models.
That’s why OpenLedger feels interesting to me.
The project seems to be betting that AI eventually needs infrastructure for tracking contribution, provenance, and economic participation — not just infrastructure for compute.
That also changes how I think about $OPEN.
Most AI tokens are framed around utility:
pay for inference, secure the network, access compute, etc.
But if OpenLedger’s thesis works, $OPEN becomes something different. Less of a compute token, more of a coordination layer tied to attribution, compensation, and ownership inside AI workflows.
That’s a much bigger idea.
But it’s also much riskier.
Because the market may not care.
That’s the part crypto people sometimes ignore.
Just because a problem is important doesn’t mean adoption happens quickly. Most companies optimize for efficiency before fairness. If black-box AI systems remain cheaper and “good enough,” attribution systems could take years to matter commercially.
There’s also the possibility that the infrastructure becomes useful while the token doesn’t capture durable value.
That risk is real.
And honestly, skepticism here is healthy.
Attribution is hard.
Standards are unclear.
Enterprise adoption could move slowly.
Regulation may shape the space before crypto-native systems do.
And perfect transparency in AI may simply never exist.
Still, I keep coming back to the same thought:
The first phase of AI was about building intelligence.
The next phase may be about accounting for it.
Not just who owns the models — but who contributed to them, who influenced them, and who gets paid when they generate economic value.
That’s why OpenLedger feels more interesting than the typical “AI chain” label suggests.
It’s not just trying to scale intelligence.
It’s trying to build a ledger around where intelligence comes from.