

Alright so... I keep getting stuck on the word "quality" with @OpenLedger .
Not because it is wrong.
Because it sounds too calm. Actually...
Quality sounds calm until I imagine the validation tab open at 2am, one OpenLedger Datanet row flagged, and nobody sure if it is noise or the only useful ugly thing in the batch.
People say better AI needs better data like that sentence solves anything. Better data. Cleaner data. Verified data. Domain-specific data. Fine. Lovely. Now put that sentence inside a Datanet and ask someone to decide what actually deserves to train a model.
That is where the nice version starts sweating.
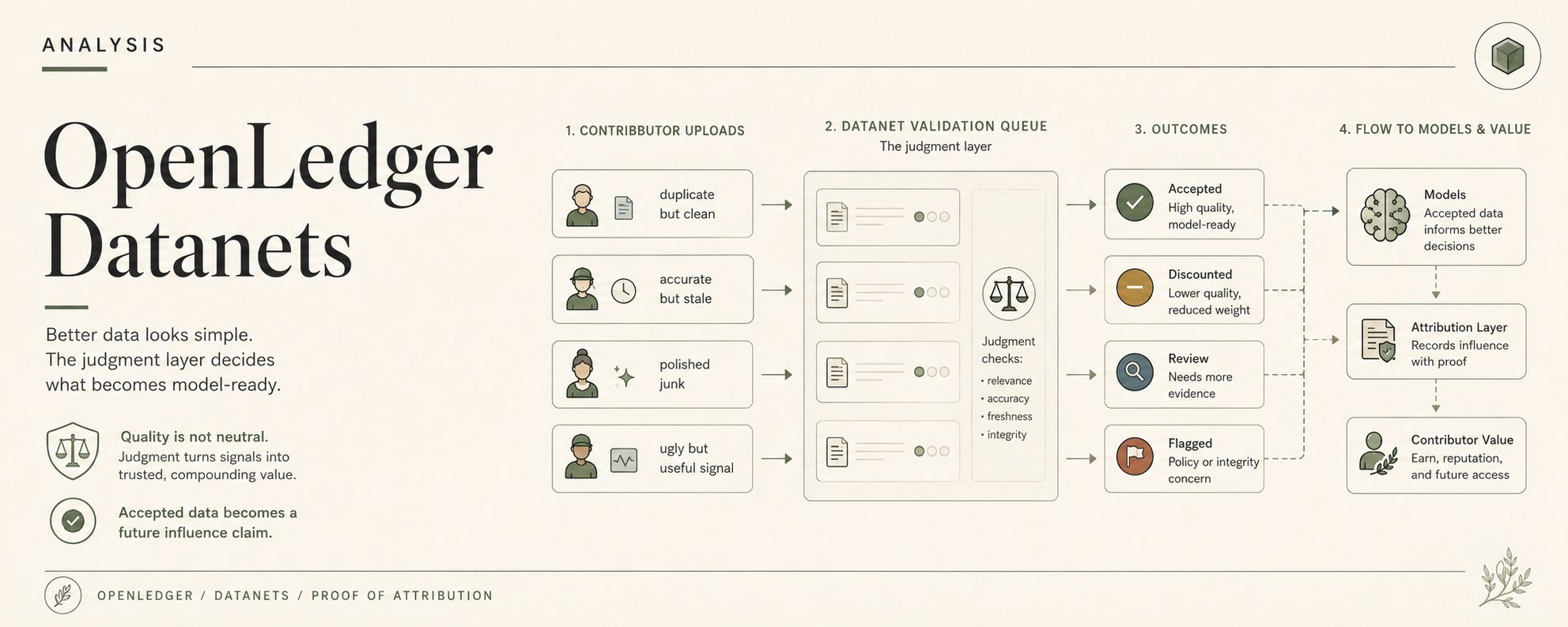
A Datanet is not just a folder with ambition on OpenLedger. It collects domain data, yes, but then the ugly parts start. Validation. Contribution history. Contributor reputation. The question of whether this row should ever reach training, retrieval, fine-tuning, or later inference.
That sounds practical.
It is practical.
That is the problem.
Because once the data becomes usable, OpenLedger has to stop treating it like a file and start treating it like a future influence claim.
Not in the cute community sense.
In the "this contribution may shape model behavior and maybe earn through Proof of Attribution later' sense.
Different mood.
anyways.
I keep picturing a Datanet built for DeFi risk data. Contributors start sending in protocol incident notes, liquidation history, exploit labels, bad debt cases, market stress examples, oracle failure records, maybe governance-risk annotations if everyone wants to suffer properly. The uploads look useful. Metadata clean enough. Categories filled. Timestamps there. Maybe a contributor reputation line already sitting beside the submission like a quiet threat.
The validation queue does that little thing dashboards do. Green fields, pending checks, one warning nobody wants to click because clicking means the day gets longer.
Good.
Now sort it.
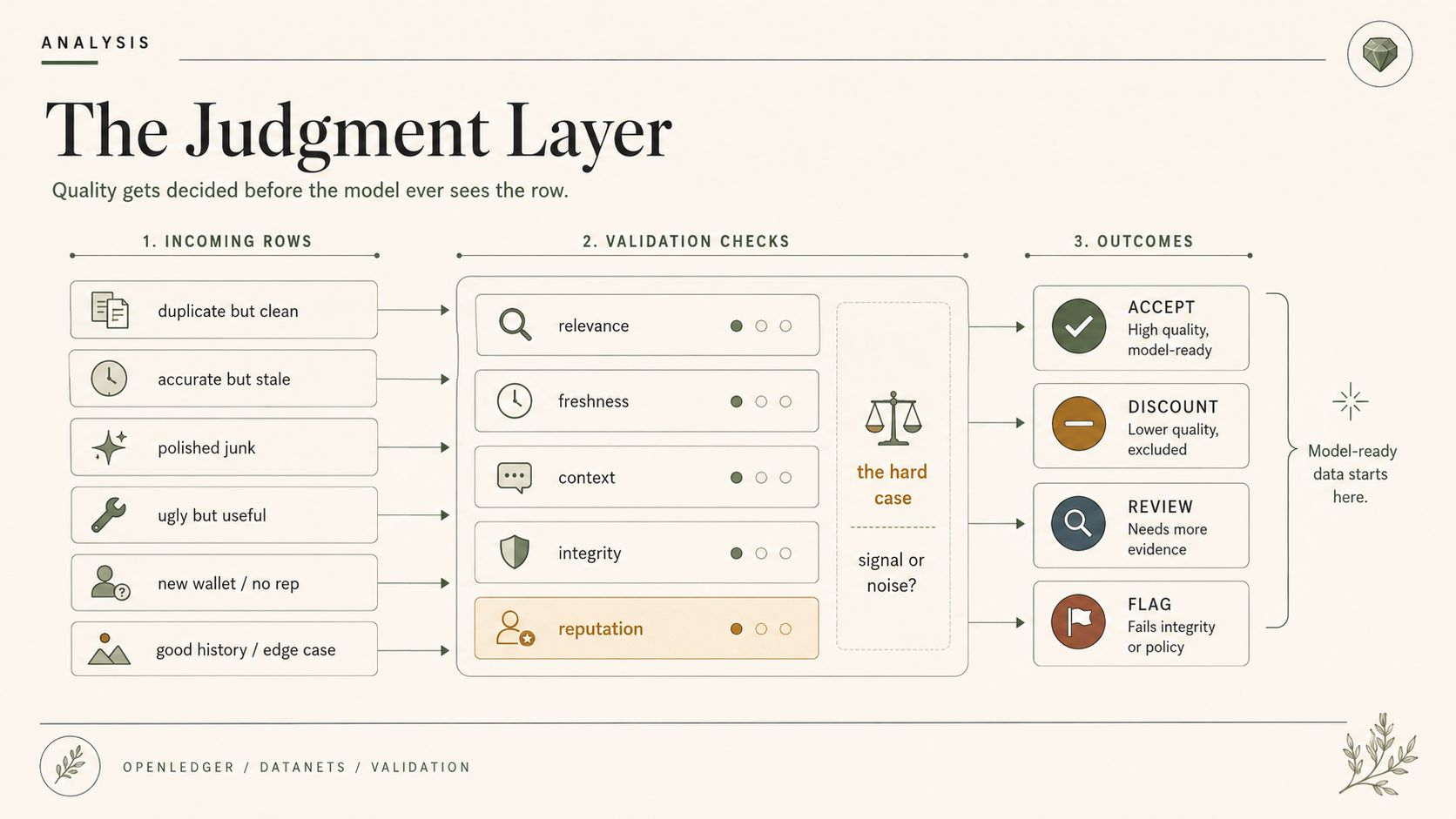
Not philosophically. In the OpenLedger's Datanet contribution flow. Accept, discount, flag, penalize, route to review, maybe let reputation tilt the first read. All very clean until one ugly submission is the only one that actually captured the real edge case.
One entry is useful but duplicated. One is accurate but stale. One is technically correct but missing the market context that made the event matter. One looks polished and is basically garbage with better formatting. One has real signal buried under ugly notes. One came from a contributor with a good history. Another came from a new wallet with no reputation trail. Good. Great even. Better data, apparently. Good morning.
This is the Datanet pressure on OpenLedger people flatten too quickly.
OpenLedger is trying to avoid the usual AI mess where models eat half the internet and nobody knows what got inside them. Datanets push the opposite direction: narrower data, stronger provenance, more contributor accountability, cleaner usage paths. That is useful.
But narrower data also makes judgment sharper.
Because a general scrape can hide bad inputs in the swamp. A Datanet cannot hide as easily. If the Datanet is supposed to feed a specialized model, then every accepted contribution starts feeling more responsible. Not morally. Operationally. The model may train on it. A OpenLedger ModelFactory workflow may select it. An OpenLoRA adapter may later specialize around outputs shaped by it. Proof of Attribution may eventually connect that data to value.
Which means the accept button is not just saying “good enough for the dataset." It is quietly creating a possible future claim on influence.
Fine.
Some builder in ModelFactory does not see the whole argument either. They see an approved dataset, maybe a Datanet label, maybe enough confidence to click forward. Lovely. The intake fight just became training material.
So the validation step on OpenLedger stops being administrative.
It starts looking like model behavior before the model even runs.
That part bothers me.
I have seen this mood in data rooms. Nobody says “we are shaping the model’s future mistakes.” They say “this row is cleaner,” and somehow that sounds responsible enough.
A contributor thinks they are submitting data. The Datanet is actually deciding whether that data deserves to become part of the future answer space. That sounds dramatic. It is not. It is just what happens when data is not dead storage anymore.
If a bad submission gets rejected, fine. Easy.
If a malicious submission gets penalized, fine. Cleaner.
The harder cases are the normal ones. Data that is half-useful. Data that is useful only in one narrow context. Data that repeats an existing pattern but confirms it well. Data that conflicts with another source and forces the OpenLedger's Datanet to choose which version becomes “model-ready.” That is not garbage collection. That is curation with economic consequences.
And on OpenLedger, those consequences do not stay inside the upload screen.
That is the part that makes the Datanet feel heavier.
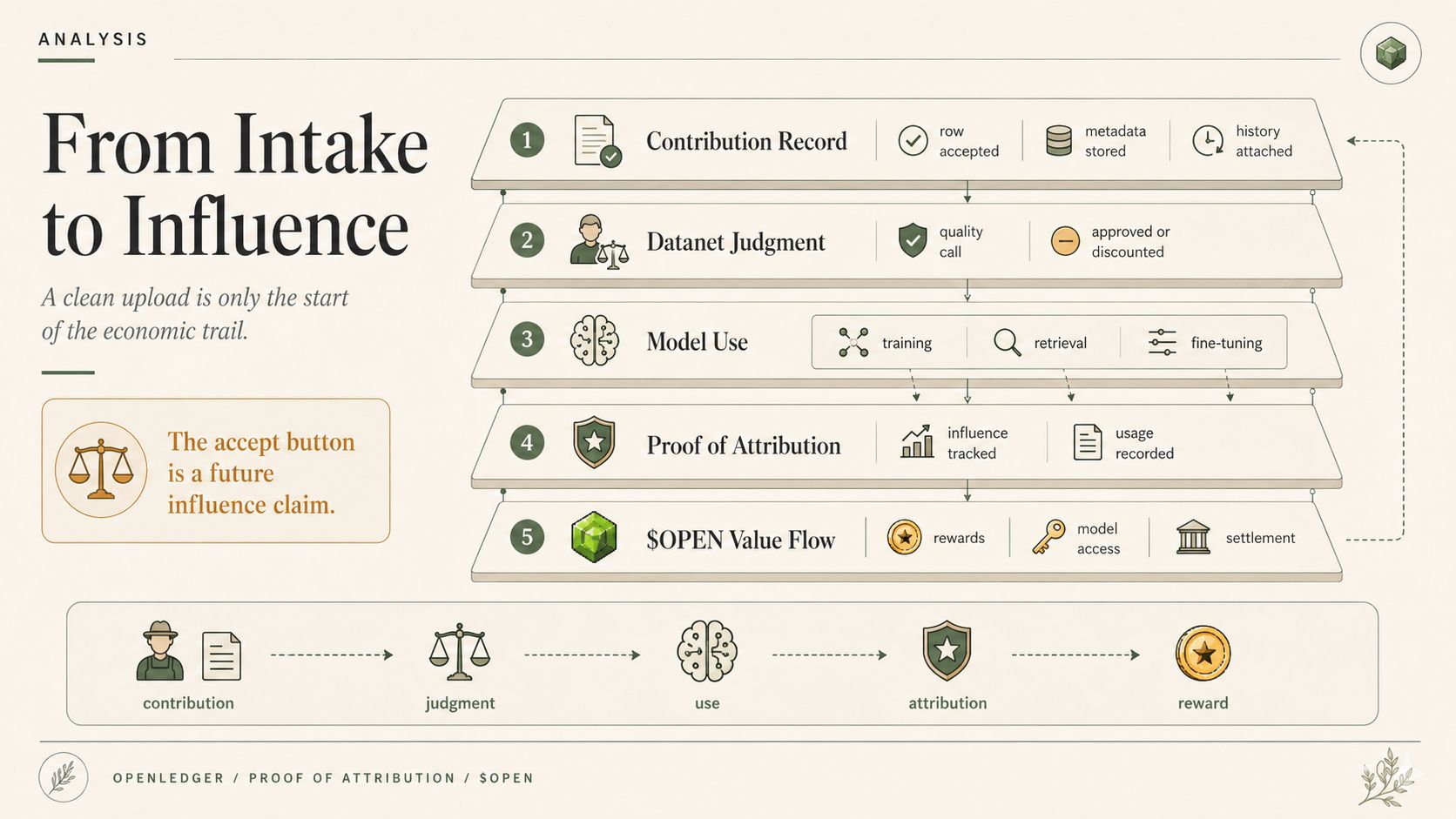
A contribution record can follow the contributor. Reputation can shape how future submissions are treated. Proof of Attribution can later decide whether that accepted data influenced an inference. $OPEN can later move through usage, rewards, model access, gas, and settlement like the intake decision was obvious the whole time. So when a Datanet accepts or discounts data, it is not only cleaning a dataset. It is quietly shaping who gets trusted later, who gets paid later, and which version of reality the model is allowed to learn from.
Nice little sorting machine.
Very democratic until the rejected row belonged to you.
I know the clean answer already. Community governance. Validation flows. Contributor reputation. Penalty logic. Contribution history on OpenLedger. Yes. Fine. Necessary machinery. Without it, Datanets become upload farms with AI branding taped on the door.
Still.
Those same tools create another layer of power.
Because quality control is not neutral once rewards exist. If contributors know Datanets reward useful influence later, they start optimizing for acceptance. They format cleaner. They imitate approved examples. They avoid weird edge cases because weird edge cases look risky. They submit data that looks model-ready instead of data that captures the ugly truth of the domain.
That is where quality starts getting weird.
The Datanet might get cleaner and less honest at the same time.
Not always. Not automatically. But enough to make me stare at the validation layer longer than the upload button.
And yes, I hate that this is where I end up. Not at the model. Not at the agent. At the intake row. Very glamorous work, staring at a row and wondering if it becomes someone’s future answer.
A real domain is messy. DeFi incidents do not arrive as clean labels. Healthcare data does not arrive without caveats. Legal data does not arrive without jurisdictional dirt. Market behavior does not fit neatly because markets are mostly humans creating expensive nonsense in sequence. If the Datanet rewards clean, reusable, easily validated contributions too aggressively, the rough-but-important data starts looking like a bad citizen.
And that is how a dataset can become high quality in a way that makes the model slightly less prepared for reality.
Lovely.
The model later answers with confidence because the Datanet underneath it was curated into confidence.
By the time an OpenLoRA adapter is serving that narrow behavior, the ugly intake decision does not look ugly anymore. It looks like specialization.
That is the scar.
Not bad data entering. Everyone sees that risk.
The worse one is useful mess getting filtered out because it makes the Datanet harder to govern, harder to validate, harder to reward, harder to turn into a clean attribution trail.
OpenLedger’s architecture makes this visible because the data layer is not hidden behind a black box. Datanets, contribution records, reputation, Proof of Attribution, model usage, reward paths. The system is basically saying: show the supply chain. Good. Finally.
But once the supply chain is visible, the judgment layer becomes visible too.
Who called this useful?
Who marked that redundant?
Who penalized the weird source?... Whatever.
Who let the clean-looking junk through?
Who decided that this data was model-ready enough to influence a future inference?
Nobody gets to pretend the model just “learned.”
Okay.
The Datanet taught it what was allowed in.
And on OpenLedger, that is the uncomfortable part. Datanets do not just feed models. They pre-shape what Proof of Attribution can later reward, what ModelFactory treats as safe training material, what OpenLoRA adapters may specialize around, and what $OPEN eventually settles as useful contribution. So the judgment layer is not outside the AI economy. It is sitting before it, quietly deciding what the economy is allowed to count. Great place to hide power. Right at intake.
That is why I do not buy the soft version where Datanets simply solve garbage in, garbage out. They do not solve it like a trash filter. They move the fight earlier. Before training. Before inference. Before the answer. Into the place where contributors, validators, reputation rules, and reward expectations decide what kind of data becomes legitimate.
Maybe that is better.
Probably it is better.
Still not clean.
Because the moment a Datanet starts deciding what counts as quality, it is already curating the model’s future mistakes.
Not just its future accuracy.
Its mistakes too.
And later, when the model says something confident, maybe OpenLedger's Proof of Attribution can show the trail, maybe the reward logic can show who contributed, maybe the Datanet history can show what got accepted.
Fine.
But somewhere before all that, someone looked at an ugly contribution and decided whether the mess was signal or just noise wearing a dirty jacket.
That decision is still sitting inside the answer.
Clean output. Dirty little Datanet decision. Same model.
And if Proof of Attribution pays the trail later, the trail starts from that intake call.
Lovely place for a mistake to become infrastructure.