
OpenLedger is showing up at an interesting time.
AI is booming again. Every week there’s a new model, a new API layer, a new startup promising “agent economies” and infinite automation. Underneath all of that hype sits the same uncomfortable reality: most of the people feeding these systems never actually own anything they help create.
Data gets scraped. Models get trained behind closed doors. Companies monetize the outputs. Contributors disappear into the background.
That’s the part OpenLedger is trying to attack.
Not with vague “AI + blockchain” branding either. The project is going after something much more mechanical: attribution. Who contributed data? Which datasets trained the model? Who should get rewarded when that model gets used?
Sounds obvious. It isn’t.
Most AI infrastructure today has almost no transparent accounting layer. Once data enters the pipeline, visibility dies. Even developers working directly with models often have no clean way to trace value back to the people or datasets that shaped the output.
OpenLedger wants to put that accounting system on-chain.
The core idea revolves around something they call Datanets. Think of them less like static datasets and more like collaborative data economies. Communities contribute, organize, validate, and maintain domain-specific data that can later feed AI training pipelines.
That distinction matters.
Raw data alone is cheap. Clean, structured, continuously maintained data is not. Anyone who has worked around machine learning knows this already. Training models is expensive, sure. But preparing useful data is where a lot of the real friction lives.
OpenLedger is basically trying to turn that invisible labor into an actual economic layer.
A Datanet could revolve around financial markets, legal archives, gaming telemetry, language datasets, medical research, whatever. Contributors upload data, validators check quality, and activity gets recorded on-chain. Not for decoration. For attribution.
That attribution becom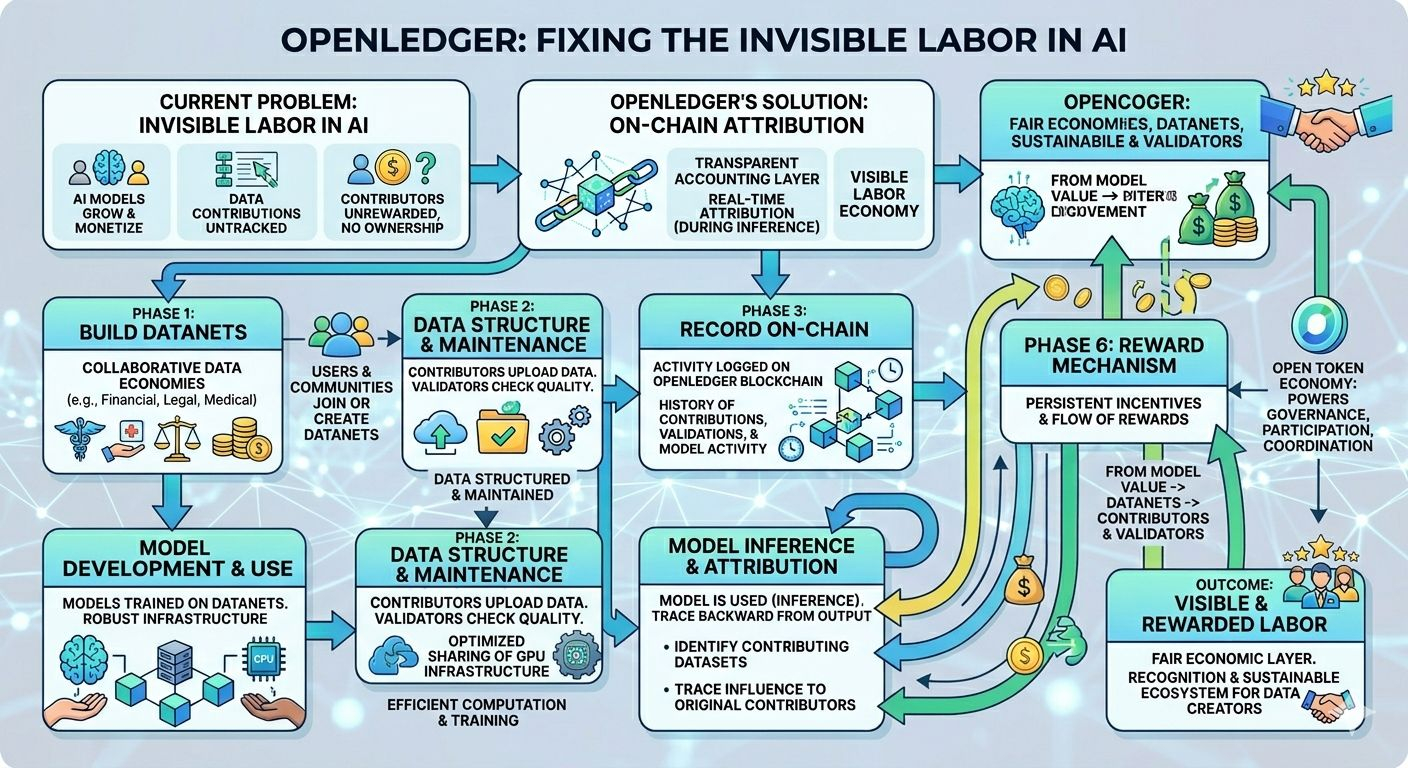 es economically important later when models start generating outputs tied to those datasets.
es economically important later when models start generating outputs tied to those datasets.
This is where the project gets more ambitious.
OpenLedger doesn’t just want decentralized storage with AI branding slapped on top. The bigger goal is real-time attribution during inference itself — the moment a model actually gets used.
That’s the hard part.
In normal AI systems, you ask a model something and receive an answer. End of story. You don’t know what training data influenced the response. You don’t know which contributors helped shape the model. You definitely don’t know who deserves compensation.
OpenLedger is trying to trace that chain backward.
If a model produces value, the system attempts to identify which datasets contributed to training, which participants improved those datasets, and how rewards should flow back through the network.
At least conceptually, that creates a much more persistent incentive structure than the current “upload data once and disappear forever” model.
Whether that works cleanly at scale is another question entirely.
Because attribution inside AI systems is messy. Really messy.
Even centralized AI companies struggle to explain model provenance in a precise way. Once models become large, layered, fine-tuned, and continuously updated, tracing influence becomes computationally and philosophically complicated fast. OpenLedger is betting blockchain coordination can make that process more transparent and economically usable.
That’s a serious technical bet. Not a marketing exercise.
The onboarding side is surprisingly accessible compared to most crypto infrastructure projects. Users can log into the platform through social authentication instead of immediately dealing with wallets and seed phrases. Small detail, but it matters if the goal is attracting actual contributors instead of only crypto-native users.
Inside the system, users can either join existing Datanets or create their own around specialized niches. The interesting part isn’t the interface though. It’s the reward logic underneath.
Every contribution, validation step, or model-related activity gets recorded. In theory, this builds a transparent history of who improved what over time.
OpenLedger also talks a lot about optimizing model deployment itself. One area they highlight is running multiple specialized models efficiently across shared GPU infrastructure.
That’s not just technical filler.
GPU costs are becoming a genuine bottleneck across AI markets right now. Especially for smaller developers. Everybody wants decentralized AI until the compute bill arrives. If OpenLedger can actually improve utilization efficiency while coordinating incentives around datasets and inference, that becomes materially more interesting than another governance token pretending to be an AI project.
And yes, the OPEN token sits in the middle of everything.
Governance, rewards, participation, network coordination. Standard crypto architecture on the surface, although the token only matters if the underlying attribution economy produces real usage. Plenty of protocols build elegant token systems around ecosystems nobody actually needs.
That’s the real challenge here: adoption.
Not theory. Not whitepapers. Usage.
Can OpenLedger attract valuable datasets? Can contributors consistently provide high-quality information? Can developers build applications on top of it instead of defaulting back to centralized AI APIs that are easier and faster?
Because convenience is brutal. Centralized systems usually win early for a reason.
Still, I think OpenLedger is aiming at a real problem instead of manufacturing one. That already separates it from a huge portion of AI-related crypto projects floating around right now.
Most “AI tokens” today are basically narrative vehicles. Thin infrastructure. Weak utility. Strong marketing.
OpenLedger feels different because it’s focused on the economic plumbing underneath AI systems, ownership, attribution, coordination, incentives. The boring infrastructure layer most people ignore until it becomes critical.
And if AI keeps absorbing more of the internet’s economic activity, that layer starts mattering a lot.
