The upload screen is misleading.
Not because it lies. It probably does exactly what it says. A contributor selects a dataset, adds the required details, sends it into OpenLedger, and waits for the system to recognize the work. The transaction records. The contribution exists. The file is no longer just sitting on someone’s machine or hidden inside a private folder.
So the first instinct is simple.
Done.
Data added. Contribution made. Value created.
But that is where the mistake starts.
Because in OpenLedger, data does not become valuable at the moment it appears. It becomes visible. It becomes available. It becomes part of a possible path. That is not the same thing as influence.
And this difference matters more than it looks.
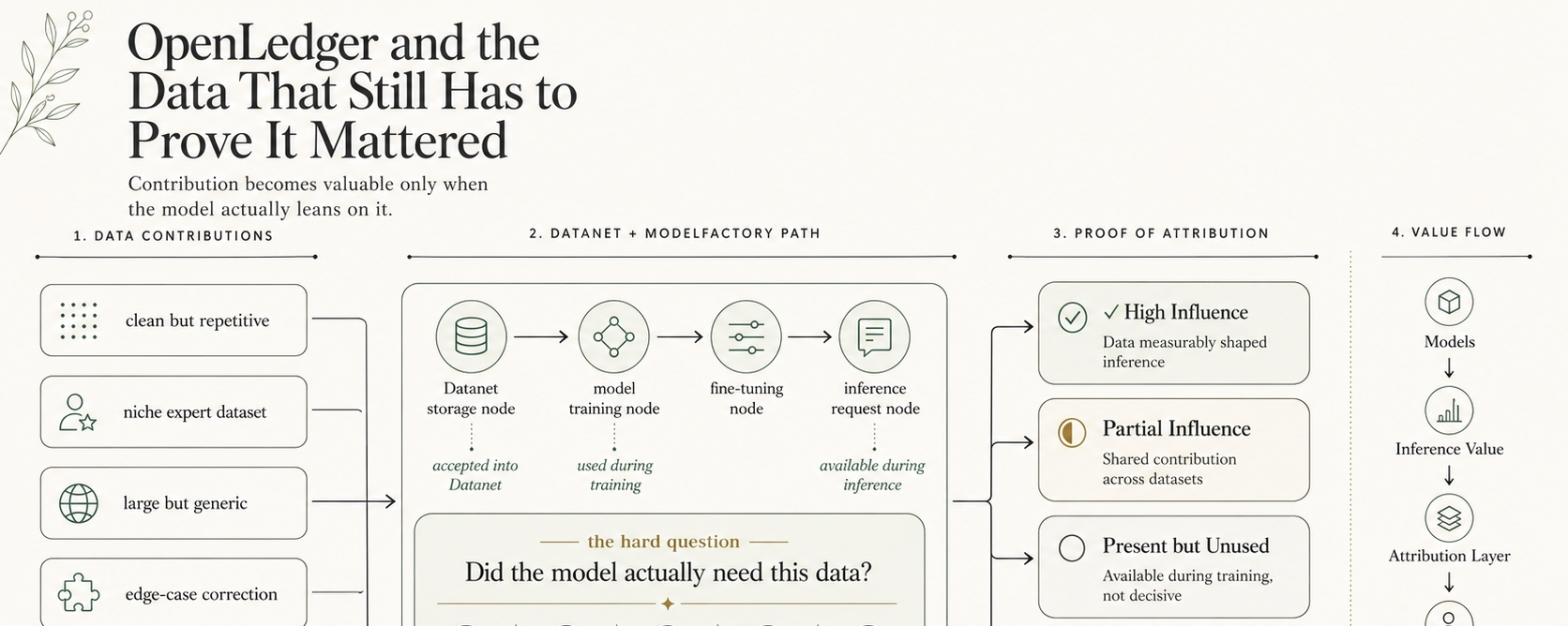
A contributor may upload clean, specialized data into a Datanet and think the important part is over. The dataset has been added to a community-owned data layer. It can be verified, organized, and made available for builders who want to train or fine-tune specialized models. On paper, that already sounds like contribution. OpenLedger’s own documentation frames Datanets as community-owned datasets used for training specialized models, with dataset uploads, model training, reward credits, and governance participation executed on-chain.
But contribution is only the beginning of the route.
The data still has to survive a quieter test.
Does it improve anything?
That question is uncomfortable because most data systems avoid asking it directly. They measure size. They measure participation. They measure whether something was submitted, labeled, tagged, verified, or stored. Those things matter, of course. Bad data should not be treated like good data. Unverified data should not sit beside trusted data as if both carried the same weight.
Still, quality is not influence.
A dataset can be clean and still unused. It can be correct and still unnecessary. It can belong to the right Datanet and still never shape a model response in a meaningful way.
That is the strange pressure inside OpenLedger.
The contributor is not only waiting for acceptance. They are waiting for relevance.
Maybe a builder opens ModelFactory and trains a model using data from one or more Datanets. Maybe the uploaded dataset becomes part of that training path. Maybe it helps a specialized model answer better in a narrow domain. Or maybe the model already had enough similar examples. Maybe other data carried stronger signals. Maybe the uploaded contribution sits inside the available pool but does not become important when inference actually happens.
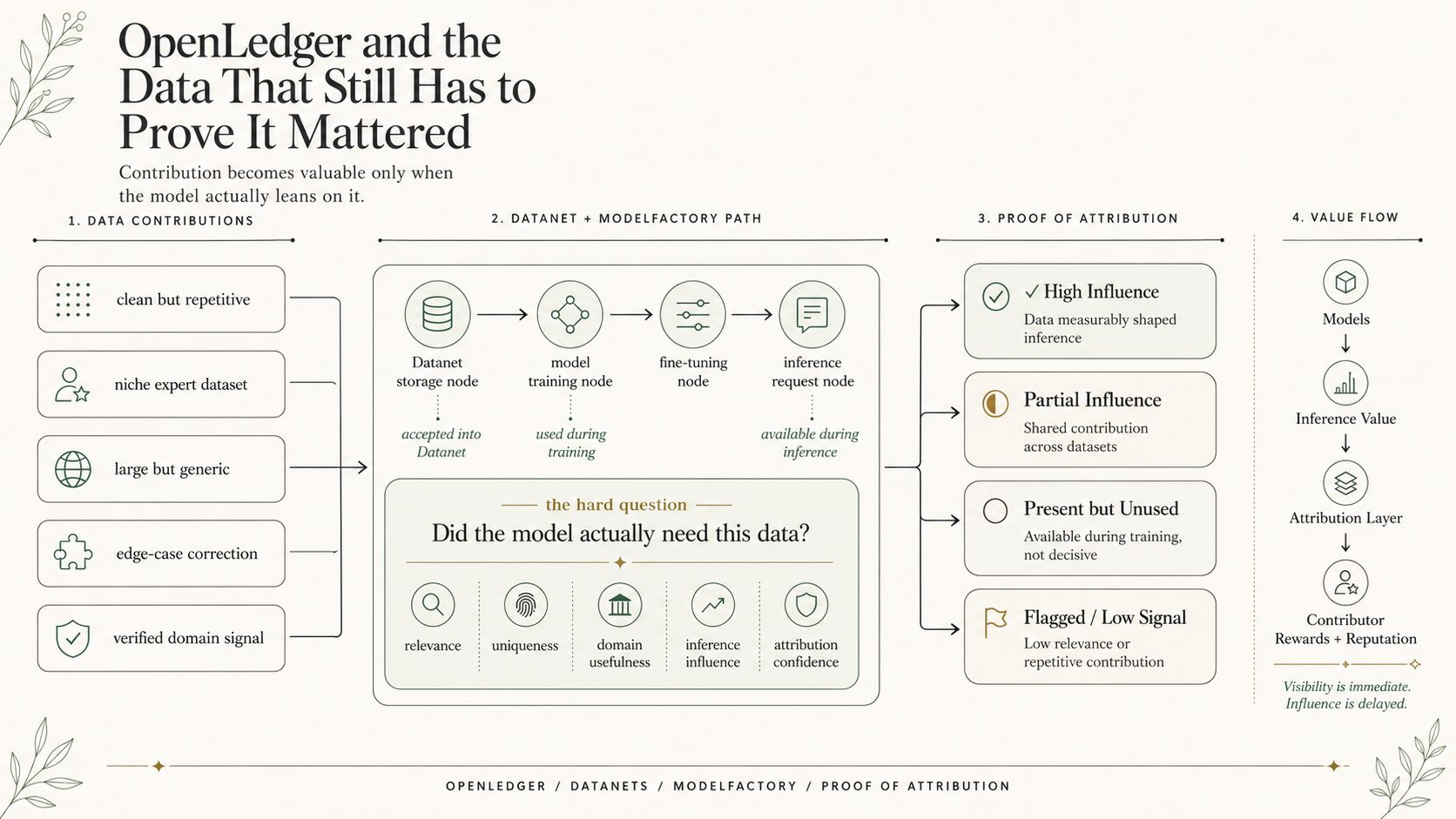
From the outside, those situations can look almost identical.
The data is there.
The contributor is there.
The model is there.
But the reward question is not settled by presence.
That is where Proof of Attribution becomes the harder part of the story. OpenLedger describes Proof of Attribution as a mechanism that identifies which data points influence model outputs and rewards contributors when their data shapes inference. Model Factory described as the place where models and adapters are created, trained or fine-tuned with Datanet data, registered on-chain, and deployed for inference.
That sounds fair.
It is also brutal.
Because it means the system is not supposed to reward a contributor just because they showed up. It has to ask whether the model actually needed their contribution at the moment value was produced.
That changes the emotional shape of uploading data.
The contributor may think they are entering a marketplace.
What they are really entering is a delayed argument.
First, the data has to be accepted into a Datanet. Then it has to be useful enough for training or fine-tuning. Then a model using that influence has to be called. Then inference has to create measurable value. Then attribution logic has to connect the output back to the data that mattered.
Only then does the reward question become real.
This is a very different model from simple “upload and earn” thinking.
And honestly, that is probably the point.
If every upload deserved equal reward, the system would be easy to game. Contributors would flood Datanets with low-value or repetitive data and still expect compensation. OpenLedger's economic layer would reward activity, not usefulness. Governance would then be forced to clean up after bad incentives: what counts as eligible data, what counts as spam, what kind of Datanet quality threshold matters, which contributors deserve weight, and how rewards should be distributed when influence is shared across many sources.
OpenLedger’s governance surface matters here because attribution is not only a technical question. It becomes an incentive design problem. OPEN holders participate in governance over protocol direction and upgrades, while the OPEN token is also tied to gas, inference fees, staking, Datanet usage, and contributor rewards.
So the boring upload becomes political.
Not political in the loud way.
Political in the protocol way.
Who decides whether data quality is enough? Who decides whether attribution should reward rare data more than common data? What happens when two datasets influence the same model response but one contributed the obvious answer and the other contributed the edge case that made the answer useful?
That is where the workflow gets weird.
A contributor can be right and still not be rewarded much.
A contributor can upload early and still wait months before the data matters.
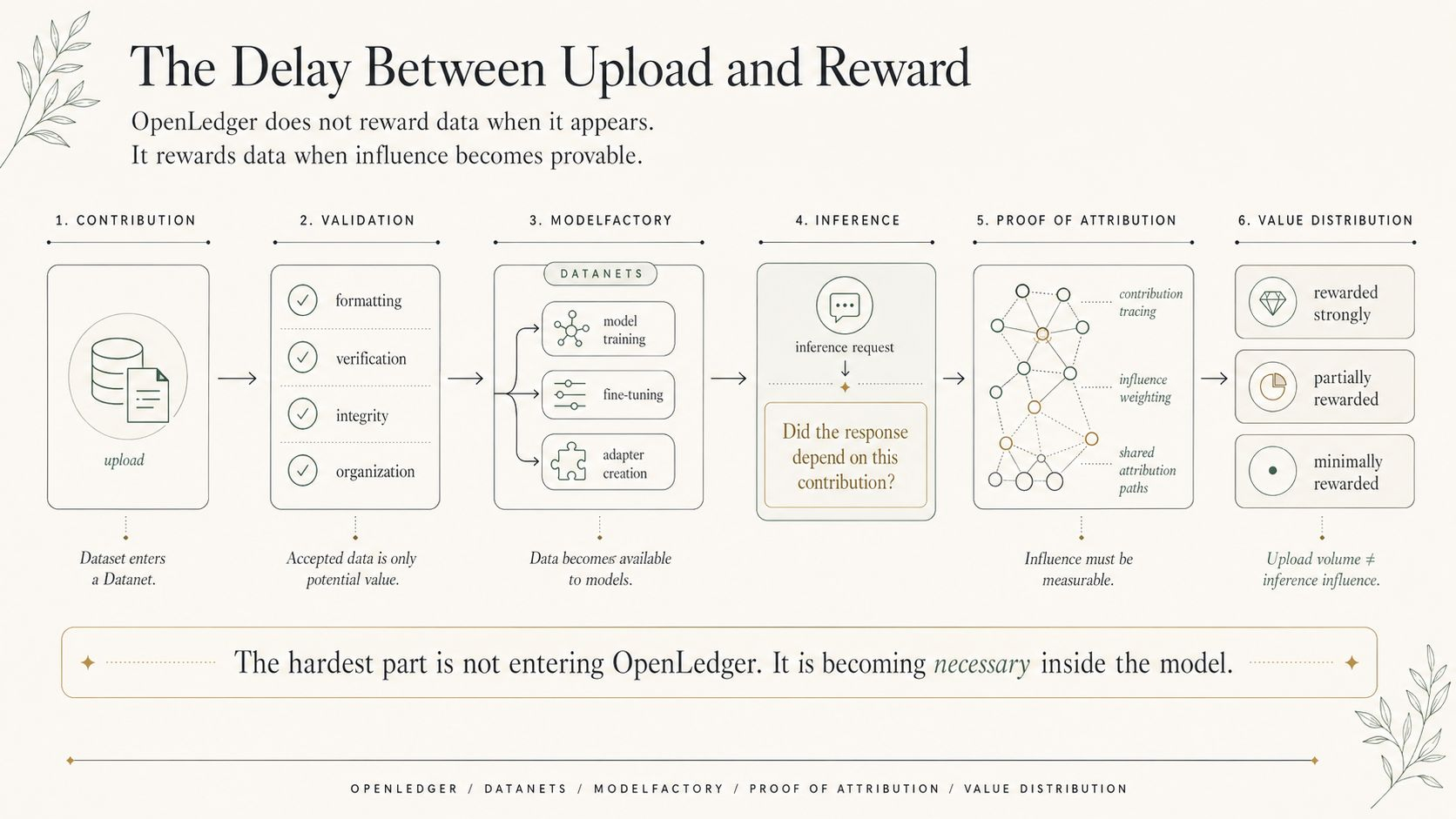
A contributor can add something small, but if that small piece becomes decisive during inference, it may carry more value than a much larger dataset that looked impressive at upload time.
The system starts pushing contributors away from volume and toward usefulness.
Not “how much did you add?”
More like:
Did the model ever lean on it?
That is a harder standard. It is also a cleaner one.
Because the real value of AI data does not appear when data enters storage. It appears when a model performs differently because that data existed. It appears when an answer becomes more accurate, more specific, more domain-aware, or more useful because a contributor added something the model could not easily replace.
That is the part most AI workflows hide.
OpenLedger brings that hidden layer into the economic path.
But it also creates a new discomfort.
If rewards depend on proven influence, then the contributor is no longer just competing to upload. They are competing to matter inside the model’s behavior.
And maybe that is the real pressure.
Not getting data into OpenLedger.
Not joining a Datanet.
Not even seeing the contribution recorded on-chain.
The hardest part may be waiting for the model to prove it ever needed you.

