
L'AI si sta muovendo così in fretta che a volte sembra che tutti parlino solo della tendenza superficiale. Nuovi agenti, nuovi modelli, inferenza più veloce, dataset più grandi, più automazione, più "tutto alimentato dall'AI". Ma più approfondisco questo settore, più sento che la vera battaglia non riguarda solo chi costruisce l'AI più intelligente.
La vera battaglia riguarda chi possiede il valore creato dall'AI.
Ecco perché OpenLedger ha catturato la mia attenzione. Per me, $OPEN non è solo un altro token AI che cerca di cavalcare la narrativa attuale del mercato. OpenLedger sta cercando di risolvere un problema molto più grande all'interno dell'economia dell'AI: dati, modelli, agenti e contributori umani aiutano tutti a creare valore, ma la maggior parte delle volte le ricompense si spostano solo verso piattaforme centralizzate.
OpenLedger sta costruendo attorno a un'idea molto diversa. Vuole che il valore dell'AI diventi tracciabile, attribuibile e ricompensabile. La sua infrastruttura è basata su Datanets, Proof of Attribution e una blockchain nativa AI in cui i contributori possono fornire dati, i costruttori possono lanciare modelli AI specializzati e la rete può tracciare quali input hanno realmente aiutato a creare un output AI. I documenti di OpenLedger descrivono i Datanets come reti di dati decentralizzate che aggregano, convalidano e distribuiscono set di dati specifici per dominio per la formazione AI.
Perché OpenLedger sembra diverso dalla normale hype dell'AI
Molti progetti crypto-AI parlano di decentralizzazione, ma molti di essi sembrano ancora solo incapsulare token attorno a una tendenza AI esistente. OpenLedger sembra più interessante perché non sta solo chiedendo, “Come possiamo portare l'AI on-chain?” Sta chiedendo qualcosa di più importante:
Come possiamo rendere visibile la proprietà dell'AI?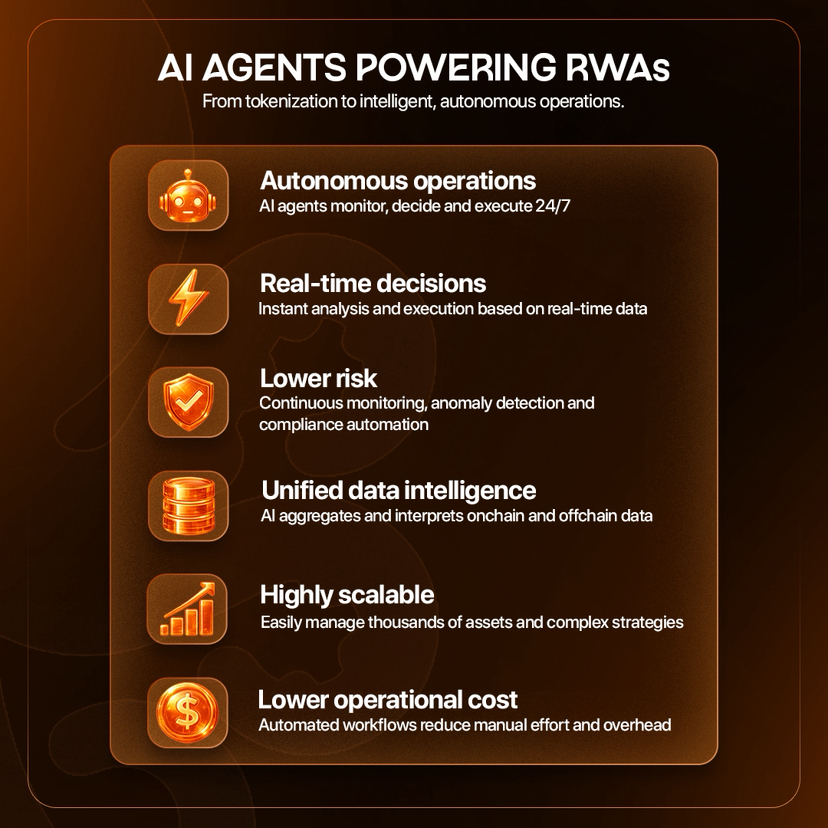
In questo momento, i modelli AI sono addestrati su enormi quantità di dati. Questi dati possono provenire da creatori, comunità, utenti, sviluppatori, ricercatori e informazioni pubbliche. Ma una volta che il modello è addestrato, le persone che hanno aiutato a creare l'intelligenza di solito scompaiono dal ciclo economico.
OpenLedger sta cercando di cambiare ciò con il Proof of Attribution, progettato per collegare crittograficamente i contributi di dati agli output del modello AI. Questo è importante perché l'AI senza attribuzione diventa una scatola nera. L'output può essere utile, ma nessuno sa esattamente chi ha contribuito al valore dietro di esso.
E onestamente, penso che qui si svolgerà la prossima grande battaglia dell'AI. Non solo riguardo la velocità. Non solo riguardo la dimensione del modello. Ma riguardo la provenienza, i diritti, la proprietà e le ricompense.
I Datanets Trasformano i Dati in un Bene Economico Vivente
Il concetto di Datanets è una delle parti più forti di OpenLedger per me.
Normalmente, i dati sono trattati come materie prime. Vengono raccolti, utilizzati, addestrati e poi dimenticati. OpenLedger sta cercando di rendere i dati più simili a un bene economico vivente. Attraverso i Datanets, i contributori possono portare dati specifici per dominio nella rete, e quei dati possono essere utilizzati per addestrare modelli AI specializzati.
Questo è importante perché il futuro dell'AI non riguarderà solo un enorme modello generale che risponde a tutto. Penso che stiamo entrando in un mondo di modelli AI specializzati per trading, assistenza sanitaria, giochi, strumenti legali, RWA, DeFi, ricerca, economie dei creatori e flussi di lavoro aziendali.
Un modello costruito per l'analisi del rischio RWA ha bisogno di dati diversi rispetto a un modello costruito per agenti di gioco. Un modello di esecuzione DeFi ha bisogno di segnali diversi rispetto a un modello di raccomandazione di moda. Un motore di previsione della volatilità ha bisogno di comportamento di mercato in tempo reale, cambiamenti di liquidità, condizioni di finanziamento, flusso di ordini, pressione macro e segnali di rischio.
Ecco perché i Datanets di OpenLedger hanno senso. Creano una struttura in cui i dati possono essere raccolti, convalidati, riutilizzati e collegati economicamente agli output dell'AI. La pipeline di attribuzione di OpenLedger afferma anche che i contributori possono ricevere ricompense basate su token in base all'impatto dei loro dati sugli output dei modelli.
Per me, questo è uno dei casi più chiari di come AI e blockchain possano realmente connettersi in modo utile. La blockchain non sta rendendo l'AI magicamente più intelligente. Sta creando uno strato economico trasparente attorno all'intelligenza.
Il Proof of Attribution è l'idea centrale dietro $OPEN
Il vero cuore di OpenLedger è il Proof of Attribution.
In parole semplici, il Proof of Attribution cerca di rispondere: cosa ha effettivamente contribuito a questo risultato AI?
Questo potrebbe sembrare semplice, ma è un problema molto difficile. I modelli AI non sono come il software normale dove ogni output segue un percorso chiaro. I modelli apprendono da molte fonti, i pesi cambiano, i dati vengono incorporati, gli agenti interagiscono e gli output sono influenzati da molti strati diversi.
OpenLedger sta cercando di creare un sistema in cui queste contribuzioni possano essere tracciate e ricompensate. La Fondazione OpenLedger afferma che il Proof of Attribution premia, e quando un modello genera un output, il motore di attribuzione traccia quali punti dati hanno avuto più influenza.
Qui diventa più di un semplice ticker di mercato. Se la rete funziona come previsto, $OPEN è parte del sistema di ricompensa e utilità dietro il contributo, l'inferenza e l'attribuzione dei dati dell'AI. I documenti di tokenomics descrivono $OPEN come il token nativo che alimenta la blockchain di OpenLedger AI e come meccanismo di ricompensa per i contributori di dati attraverso il Proof of Attribution.
Questo è importante perché molti token AI lottano con una reale utilità. Sembrano buoni durante un ciclo di hype, ma il token non è sempre all'interno del ciclo del prodotto reale. Con OpenLedger, il token è direttamente legato all'attribuzione, agli incentivi dei contributori e all'uso dell'AI.
Dove si inseriscono i Motori di Previsione della Volatilità in questo
Questo è dove l'idea dei Motori di Previsione della Volatilità diventa molto interessante.
Nei mercati, la volatilità non è solo rumore. È informazione. Un buon sistema di esecuzione non dovrebbe solo chiedere se il prezzo sta salendo o scendendo. Dovrebbe comprendere lo stato attuale del mercato: calmo, instabile, sovraesteso, risk-on, risk-off, compresso o pronto per l'espansione.
I Motori di Previsione della Volatilità funzionano come classificatori dello stato di mercato in tempo reale per i sistemi di esecuzione. Trasformano l'incertezza stessa in un input misurabile per decisioni consapevoli del rischio. Invece di fare affidamento solo su assunzioni storiche statiche, aggiornano continuamente le aspettative di volatilità basate sulle condizioni di mercato in cambiamento.
Questo si collega molto naturalmente con l'idea più ampia dell'infrastruttura AI di OpenLedger.
Immagina modelli AI specializzati addestrati sul comportamento di mercato, cambiamenti di liquidità, regimi di volatilità, movimenti di finanziamento, flussi on-chain e segnali macro. Se quei modelli sono costruiti attraverso Datanets in stile OpenLedger, allora i dati alla base della previsione possono diventare attribuibili. I contributori che hanno fornito dati di mercato preziosi potrebbero essere collegati agli output che quei modelli generano.
Questo cambia l'intera struttura.
Un modello di volatilità non è più solo un algoritmo chiuso all'interno di un sistema di trading privato. Può diventare parte di un'economia AI trasparente dove qualità dei dati, prestazioni del modello e valore del contributore sono tutti connessi. Per i trader, i protocolli e i sistemi di esecuzione automatizzati, questo è importante perché le decisioni di rischio diventano più intelligenti e più spiegabili.
Questo è il tipo di layer AI di cui penso che la crypto abbia davvero bisogno. Non branding AI casuale, ma infrastruttura pratica dove i modelli possono classificare il rischio, aggiornare le assunzioni e supportare l'esecuzione in tempo reale.
Perché gli Agenti AI e le RWA Rendono la Tesi di OpenLedger Più Grande
Le RWA hanno portato beni del mondo reale on-chain. Ma la tokenizzazione da sola non è la destinazione finale.
Mettere un asset on-chain è solo il primo passo. L'opportunità maggiore è rendere quegli asset programmabili, monitorabili e gestiti in modo intelligente. È qui che entrano in gioco gli agenti AI.
Gli agenti AI possono monitorare le condizioni degli asset, tracciare il rischio, aggiornare le strategie, rilevare anomalie, gestire flussi di lavoro per la conformità ed eseguire azioni basate su dati in tempo reale. Invece di osservare manualmente ogni variabile, gli agenti possono operare continuamente.
Quindi, quando le persone dicono che le RWA riguardano la tokenizzazione, penso che sia solo metà della storia.
Il futuro delle RWA va oltre la tokenizzazione. Si tratta di esecuzione potenziata dall'AI su larga scala.
Qui l'architettura di OpenLedger diventa ancora più rilevante. Se i beni del mondo reale saranno gestiti da agenti AI, allora quegli agenti avranno bisogno di dati fidati. Avranno bisogno di input verificati. Avranno bisogno di attribuzione. Avranno bisogno di registri chiari su quali informazioni hanno influenzato una decisione.
Un agente AI che gestisce un tesoro tokenizzato, un bene immobiliare, un pool di fatture, un prodotto di credito o un'esposizione a materie prime non può operare su dati neri e disordinati per sempre. Più soldi sono coinvolti, più importante diventa la provenienza.
Ecco perché vedo una forte connessione tra OpenLedger e il futuro delle RWA. OpenLedger non è direttamente solo un progetto RWA, ma il suo layer di attribuzione AI potrebbe supportare il tipo di intelligenza di cui le RWA hanno bisogno per scalare in sicurezza.
Architettura Basata su Intenti e DeFAI si Collegano Anche Qui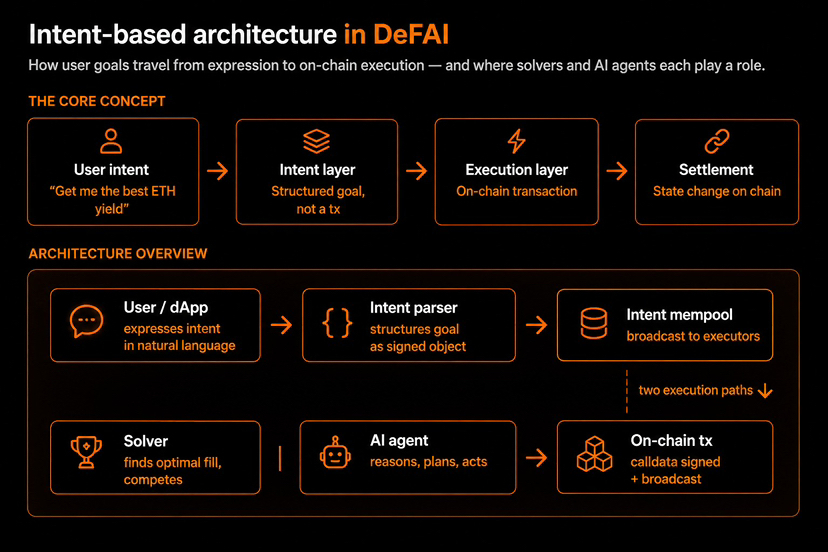
Un altro ambito in cui la tesi di OpenLedger diventa più forte è DeFAI e architettura basata su intenti.
La vecchia esperienza crypto è molto manuale. Gli utenti devono capire ponti, swap, pool di liquidità, gas, slippage, approvazioni, staking, percorsi di rendimento, rischio di liquidazione e impostazioni di transazione. È troppo per gli utenti normali.
I sistemi basati su intenti cambiano l'esperienza. Invece di dire alla blockchain ogni piccola azione, l'utente esprime un obiettivo. Ad esempio, “dammi il miglior rendimento ETH” o “sposta i miei fondi nella strategia stablecoin più sicura.” Poi risolutori o agenti AI gestiscono il percorso di esecuzione.
Qui l'architettura diventa potente: l'intento dell'utente si sposta in un layer di intenti, viene strutturato, passato a risolutori o agenti AI, eseguito on-chain e infine regolato come un cambiamento di stato.
Ma qui c'è la parte importante. Se gli agenti AI stanno prendendo decisioni all'interno di sistemi DeFi e RWA, allora l'attribuzione diventa ancora più importante. Chi ha fornito i dati? Quale modello ha fatto la raccomandazione? Quale agente ha eseguito la transazione? Quale fonte ha influenzato la strategia?
Senza quella trasparenza, DeFAI può diventare pericoloso molto rapidamente. L'automazione senza responsabilità non è un vero progresso. È solo un rischio più veloce.
Il Proof of Attribution di OpenLedger si inserisce in questo futuro perché offre all'economia AI un modo per registrare e ricompensare il contributo. In un mondo in cui gli agenti prendono decisioni finanziarie, questo tipo di infrastruttura potrebbe diventare essenziale.
Perché la connessione con Story Protocol è importante
Un'altra parte recente di OpenLedger che penso meriti attenzione è il suo lavoro con Story Protocol.
Story Protocol e OpenLedger hanno annunciato uno standard di formazione AI con diritti liberati progettato per mostrare come la proprietà intellettuale venga utilizzata nella formazione AI e supportare la compensazione automatica dei creatori. Questo è importante perché i dati dell'AI stanno diventando un problema legale, etico ed economico allo stesso tempo.
I creatori vogliono sapere se il loro lavoro viene utilizzato. Gli sviluppatori vogliono pipeline di formazione più pulite. Le istituzioni vogliono più trasparenza. I regolatori prestano maggiore attenzione a come vengono costruiti i modelli AI. Questo non è più un problema di nicchia.
Se l'AI continua a crescere, la formazione con diritti liberati e l'attribuzione trasparente potrebbero diventare molto più importanti. L'impegno di OpenLedger in quest'area rende il progetto più allineato con dove l'infrastruttura AI potrebbe dirigersi in futuro.
Per me, questo è uno dei motivi per cui vale la pena osservare oltre il normale ciclo di hype. Il progetto non parla solo della domanda di AI. Tocca il layer di proprietà e diritti dietro la domanda di AI.
Il Rischio Che Nessuno Dovrebbe Ignorare
Mi piace la tesi di OpenLedger, ma non penso che questo sia un problema facile.
L'attribuzione su larga scala è estremamente difficile. I modelli AI sono complessi. L'influenza dei dati non è sempre semplice da misurare. I contributori possono cercare di manipolare i sistemi di ricompensa. Dati di bassa qualità o sintetici possono creare rumore. La governance dovrà decidere come giudicare la qualità, come gestire le controversie e come la rete si protegge dalla manipolazione.
Questo è particolarmente importante se OpenLedger si espande in aree come DeFAI, automazione RWA e previsione della volatilità. Quando l'AI sta solo creando contenuti, gli errori possono essere fastidiosi. Ma quando l'AI inizia a influenzare l'esecuzione finanziaria, gli errori diventano costosi.
Ecco perché il valore a lungo termine del progetto dipende da se può costruire fiducia, non solo attività.
Una rete che premia qualsiasi dato non è sufficiente. Deve premiare dati utili. Una rete che supporta agenti AI non è sufficiente. Deve supportare agenti responsabili. Una rete che traccia l'attribuzione non è sufficiente. Deve rendere l'attribuzione affidabile sotto pressione.
Questa è la vera prova per OpenLedger.
La Mia Visione Finale su OpenLedger e $OPEN
Il motivo per cui trovo OpenLedger interessante è perché si trova all'incrocio di tre grandi cambiamenti che stanno accadendo ora.
Prima, l'AI ha bisogno di una migliore proprietà e attribuzione.
In secondo luogo, DeFi e RWA si stanno muovendo verso l'automazione.
In terzo luogo, gli agenti avranno bisogno di dati fidati e registri di esecuzione trasparenti.
OpenLedger sta cercando di costruire un'infrastruttura per quel futuro esatto.
I Datanets possono organizzare e monetizzare dati specializzati. Il Proof of Attribution può collegare i contributi di dati agli output dell'AI. Può alimentare ricompense e utilità all'interno dell'ecosistema. I Motori di Previsione della Volatilità mostrano come i modelli AI specializzati possono supportare un'esecuzione consapevole del rischio in tempo reale. Gli agenti AI mostrano come le RWA possono muoversi dalla semplice tokenizzazione verso operazioni finanziarie autonome.
Ecco perché penso che OpenLedger sia più grande di un semplice altro racconto sull'AI.
Non si tratta solo di costruire AI on-chain. Si tratta di costruire un'economia AI più responsabile in cui dati, modelli, agenti, creatori e contributori possano far parte del flusso di valore.
Certo, l'esecuzione deciderà tutto. L'idea è forte, ma il mercato alla fine giudicherà se OpenLedger può scalare l'attribuzione, mantenere la qualità dei dati, attrarre veri sviluppatori e creare domanda sostenibile per $OPEN.
Ma da una prospettiva narrativa e infrastrutturale, penso che OpenLedger stia lavorando su uno dei layer più importanti che mancano nell'AI.
Perché il futuro dell'AI non riguarderà solo l'intelligenza.
Si tratterà di proprietà.
Si tratterà di attribuzione.
Si tratterà di esecuzione autonoma.
E si tratterà di dimostrare da dove proviene realmente il valore.
Ecco perché tengo @OpenLedger nel mio radar.