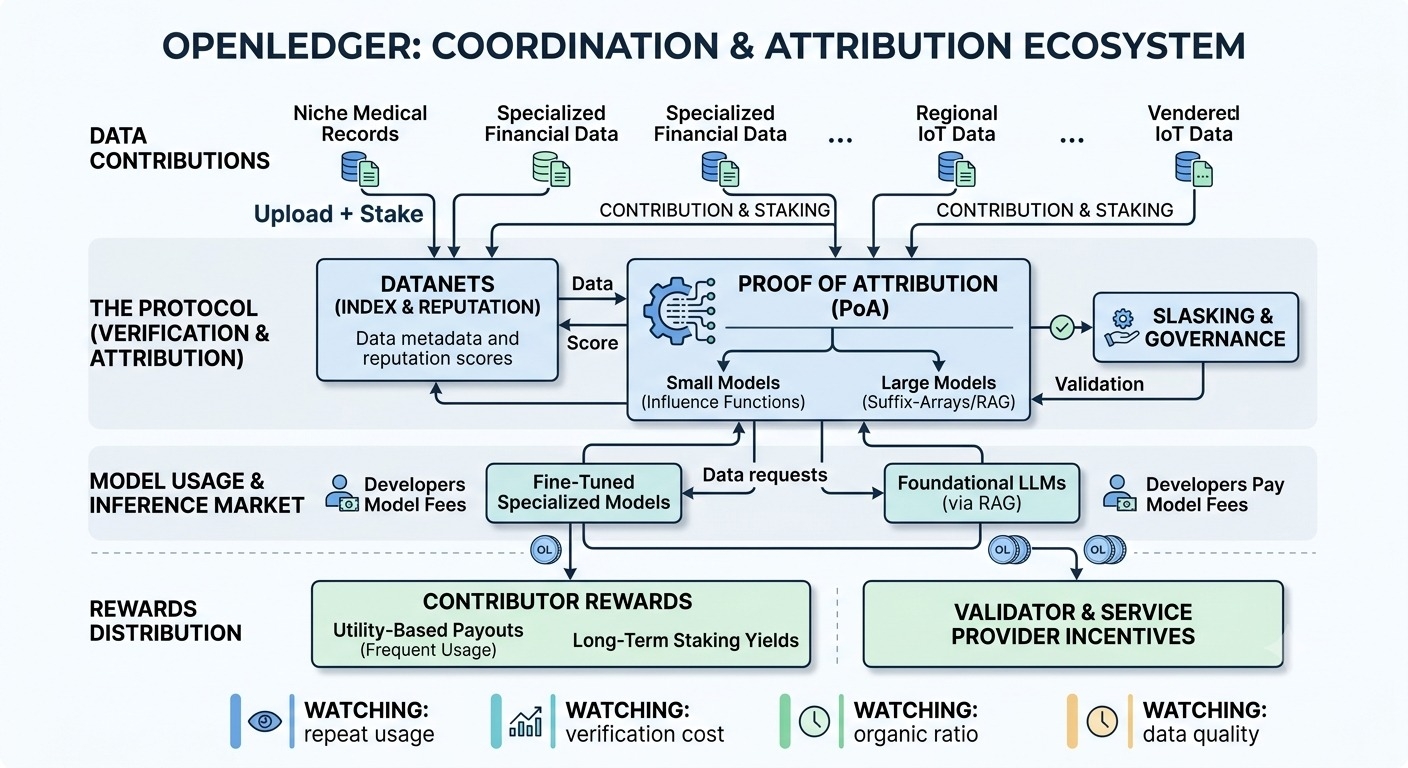
Was digging into how openledger handles data attribution, and i’m still trying to separate the clean architecture story from the messy operational reality. what caught my attention is that openledger isn’t just pitching “put ai data on-chain,” which would be kind of meaningless by itself. the more interesting idea is using on-chain records to coordinate who contributed data, who used it, and how rewards should flow when that data supports models or applications.
most people think openledger is just another ai + crypto token where users upload datasets, earn rewards, and hope model builders show up later. honestly, that might still be the main risk. but the more charitable read is that openledger is trying to build a coordination layer for ai supply chains: contributors, curators, model developers, and applications all interacting through a shared attribution and settlement system.
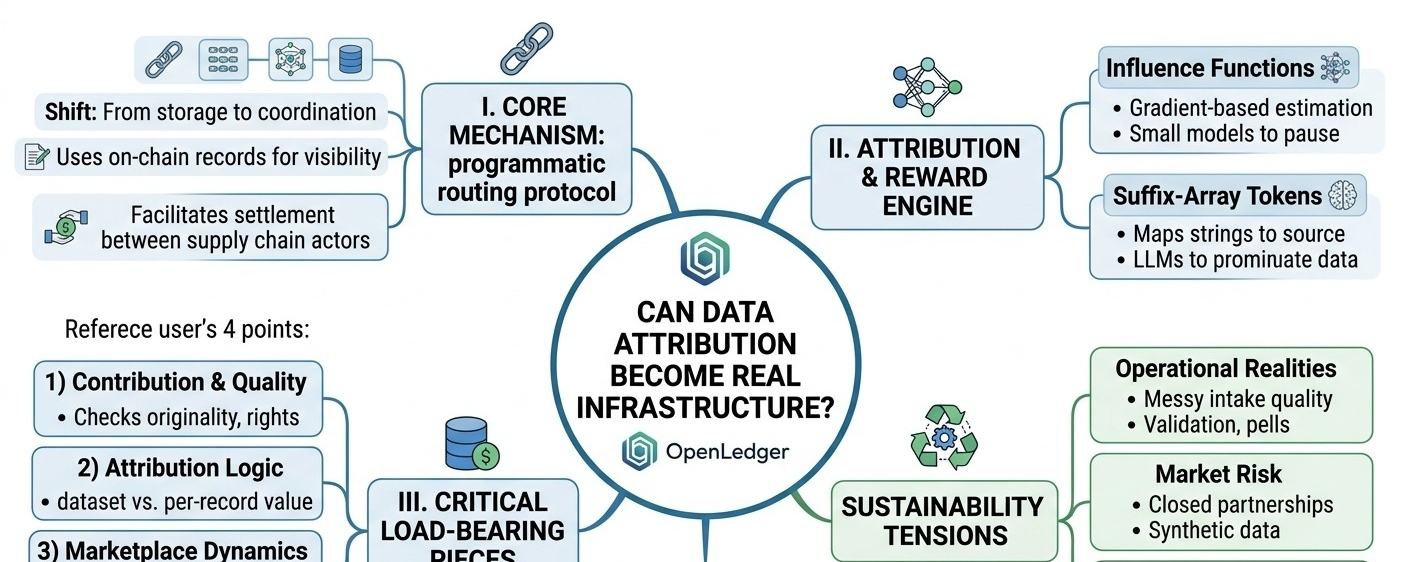
a few pieces seem load-bearing:
1) decentralized data contribution system
the actual data probably cannot live fully on-chain, so the practical setup is off-chain storage with on-chain hashes, metadata, licensing terms, and contributor records. that’s normal. the hard part is not storage, it’s intake quality. who checks whether a dataset is original, correctly labeled, rights-cleared, and not just scraped junk repackaged under a new name? openledger can use validators, staking, reputation, and audits, but those systems have to be strong enough to stop spam without turning into a small group of unofficial gatekeepers.
2) attribution + reward mechanism
and this is the part i keep thinking about. attribution sounds simple until you ask what is actually being attributed. if a model trains on five datasets, filters half the samples, augments the rest, and then fine-tunes again later, how do you assign value? true per-record contribution is very hard. the more realistic version is probably dataset-level or tranche-level attribution: a training run references certain dataset hashes, usage is logged or attested, and rewards are split according to some agreed formula. useful, yes, but not magic. it depends heavily on honest usage reporting, audits, and penalties for under-reporting.
3) ai model / data marketplace dynamics
the marketplace side only works if there is real buyer demand, not just contributor activity. a realistic use case might be a team building a customer-support model for under-served languages. they need consented audio, transcripts, corrections, and domain-specific labels. centralized vendors can provide some of this, but provenance is often opaque and contributors rarely share in downstream value. openledger’s pitch is basically: make the data supply chain visible enough that payments can be routed back when the model is trained or used. that is a coherent idea, but buyers still need to believe the data is better, safer, or cheaper than existing procurement routes.
4) token incentives + verification/scalability
the token seems to be doing several jobs: bootstrapping contributor supply, rewarding validators, coordinating staking/slashing, and possibly settling marketplace payments. i’m a little skeptical when one token has to solve every coordination problem. early emissions can create activity, but they can also attract people optimizing for rewards rather than usefulness. on scalability, model usage happens off-chain, so openledger likely needs batched settlement: signed usage receipts, periodic checkpoints, maybe trusted execution or third-party attestations. if verification is weak, the attribution layer becomes more like accounting etiquette than enforceable infrastructure.
so who actually creates value here? not “anyone uploading data.” value comes from contributors with scarce, legally usable data; curators who keep the corpus clean; validators who make provenance trustworthy; and buyers who bring real fee flow. openledger is making a pretty specific assumption: that ai demand keeps moving toward specialized models that need fresh, traceable, domain-specific data. plausible, but not guaranteed. if model builders rely more on closed partnerships, synthetic data, or internal datasets, the open marketplace demand could be thinner than the incentive design expects.
the tension is sustainability. if contributor payouts are mostly token emissions for too long, the network can look healthy while accumulating low-quality inventory. duplicated datasets, lazy labeling, fake usage, and subtle data poisoning are all rational if rewards are based on shallow metrics. and if attribution only works when a few trusted validators approve everything, then the system may quietly drift back toward the centralized platform model it is trying to avoid.
no perfect conclusion yet. openledger might be building a real ai coordination layer, but it has to prove that attribution can be trusted at scale and that buyers will fund rewards with actual usage, not just future expectations.
watching:
- share of contributor rewards funded by buyer fees vs token emissions
- dataset rejection, deduplication, and label-audit rates
- validator concentration and real dispute outcomes
- repeat buyer activity tied to production training or inference
the question for me is: can openledger make honest attribution the easiest path for model builders, or does it become extra overhead they route around when real money is involved?