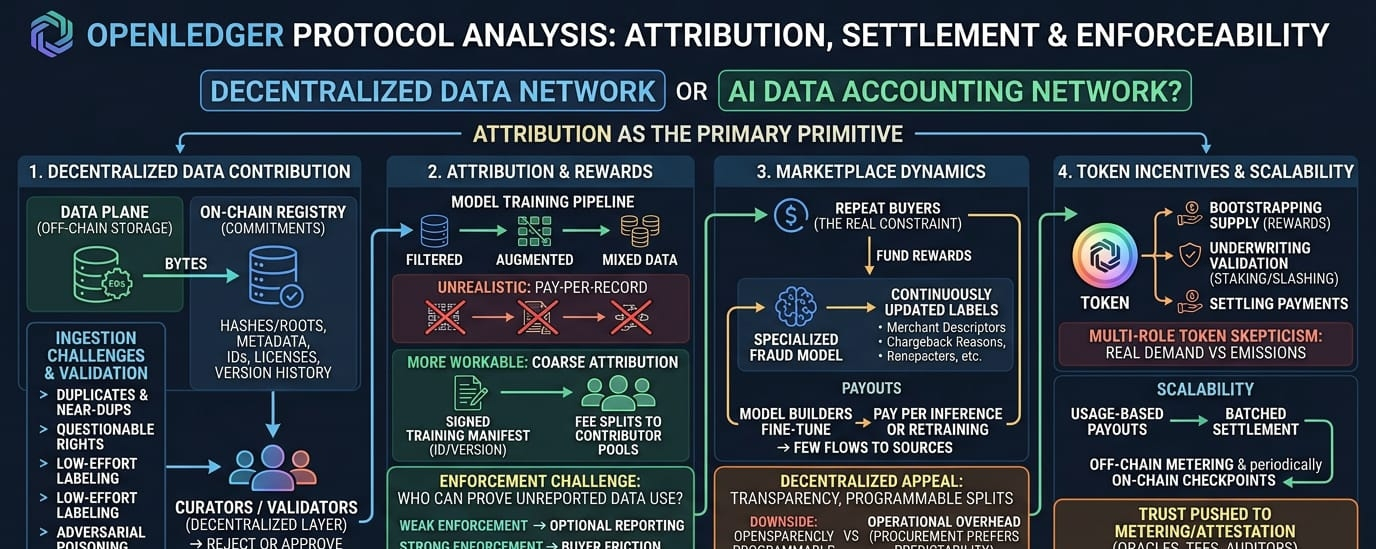
been going through openledger's architecture and incentive writeups and i keep rewriting the same question in different words is this a decentralized data network or is it an accounting network that happens to be about ai data? what caught my attention is that openledger seems to treat attribution as the primary primitive. not we host datasets but we can track who contributed what and route payments when models train / serve. that's a much sharper claim and also where most of the risk sits.
most people think openledger is just another ai + crypto token with a data marketplace glued on. honestly that’s the easiest interpretation, especially early on when demand is fuzzy and emissions are doing most of the work. but if i try to take the long term network design seriously openledger is basically attempting to standardize a workflow that's currently handled by centralized data vendors provenance licensing metering invoicing and disputes just split across a protocol + participants.
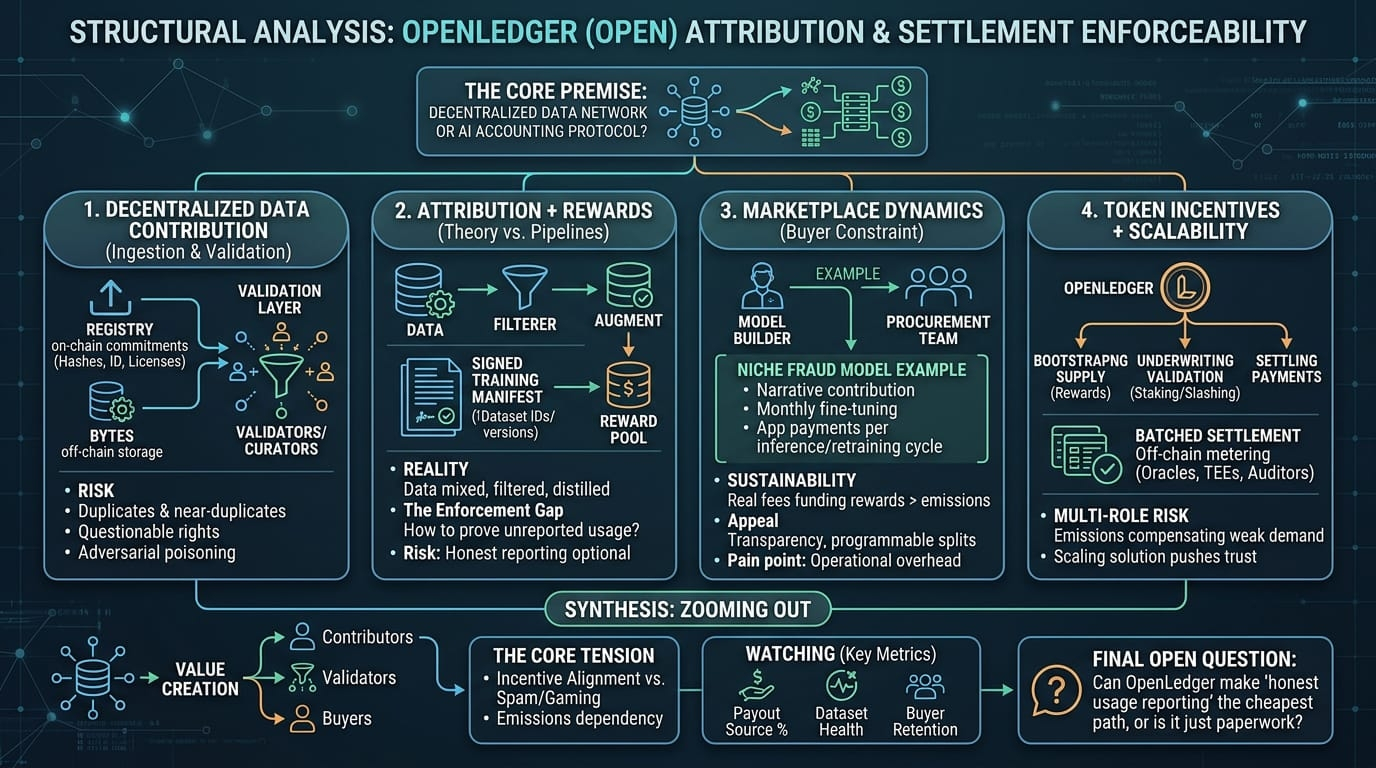
the way i'm breaking down the system right now
1) decentralized data contribution (registry vs bytes)
the data plane is almost certainly off chain storage, while the chain anchors commitments hashes/roots, metadata, contributor ids licenses maybe dataset version history. that part is fine. the uncomfortable bit is ingestion. open contribution is great until you get (a) duplicates and near duplicates, (b) questionable rights (c) low effort labeling, (d) adversarial poisoning. so openledger needs a validation layer that can reject bad submissions without slowing everything to a crawl. which means validators/curators become a key actor even if they re decentralized.
2) attribution + rewards (where theory meets training pipelines)
and this is the part i keep thinking about. in a real training run data is filtered augmented mixed sometimes distilled and often never cleanly referenced again. so pay per record used feels unrealistic. the more workable version is coarse attribution datasets (or tranches) get referenced by id/version in a signed training manifest and fees are split to those datasets contributor pools. maybe there's a challenge window where someone can dispute misreporting. but then who can actually prove a model used unreported data? if the enforcement mechanism is weak honest reporting becomes optional. if enforcement is strong you add friction that buyers may avoid.
3) marketplace dynamics (buyers are the real constraint)
openledger only becomes sustainable if there are repeat buyers funding rewards with real fees. a realistic example: a niche fraud model for a payments app needs continuously updated labeled transaction narratives (merchant descriptors chargeback reasons, language variants). contributors can provide samples + labels over time model builders fine tune monthly the app pays per inference or per retraining cycle some portion flows back to the data sources. compared to a centralized vendor the appeal is transparency and programmable splits. the downside is operational overhead procurement teams like predictability and liability containment not new coordination surfaces.
4) token incentives + network coordination scalability
the token seems to coordinate three things at once: bootstrapping supply (rewards), underwriting validation (staking/slashing), and settling payments. i m mildly skeptical of multi role tokens because when one function is weak (real demand), the others compensate (emissions) and the network can look active while not being economically grounded. on scalability if openledger wants usage based payouts it probably needs batched settlement off chain metering and periodic on chain checkpoints. that pushes trust into whoever runs the metering/attestation infrastructure (oracles tees auditors etc.). i'm not sure which assumption openledger is making here, and it matters.
zooming out who creates value? contributors create value only when their data is scarce clean and rights clear. validators create value if they can keep quality high without centralizing control. buyers create value because they bring external cashflow that can replace emissions. openledger's long term bet is that ai demand fragments into lots of specialized models where data procurement stays painful and continuous. plausible but not guaranteed especially if synthetic data pipelines get better and more teams keep data internal.
the tension is incentive alignment over time. if rewards are mostly emissions you'll attract the usual behaviors spam uploads, relabeled duplicates gaming whatever quality metric exists even wash purchases to farm payouts. and if attribution doesn't hold up at scale the whole on chain coordination story turns into a best effort registry.
no perfect conclusion yet. i can see openledger becoming a real coordination layer, but it has to prove (1) buyers will pay and (2) attribution is enforceable enough to prevent free riding.
watching:
% of payouts funded by buyer fees vs token emissions (trend not snapshot)
validator concentration + dispute frequency/outcomes
dataset health metrics dedup rates rejection rates independent audits
repeat buyer retention tied to production training/inference not pilots
open question i keep coming back to can openledger make honest usage reporting the cheapest path for model builders or does it end up as paperwork that serious teams route around?