My journey with OpenLedger started when I began exploring how artificial intelligence actually learns from data. Most AI platforms talk about powerful models and automation, but very few explain where the data comes from, who contributes it, or how contributors are rewarded. That is what made OpenLedger different for me. Instead of treating data like an invisible resource, OpenLedger builds an ecosystem where every contribution matters and every contributor can be recognized.
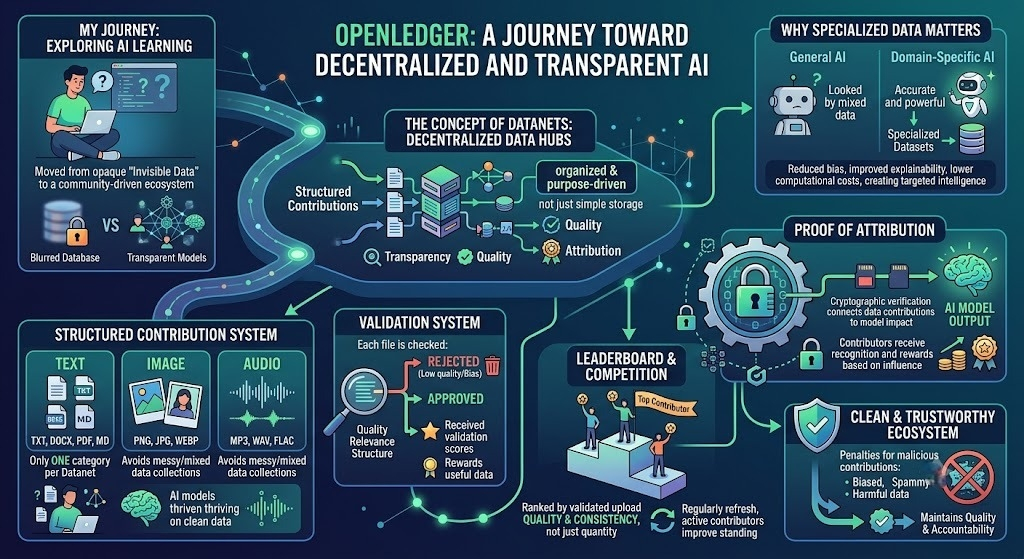
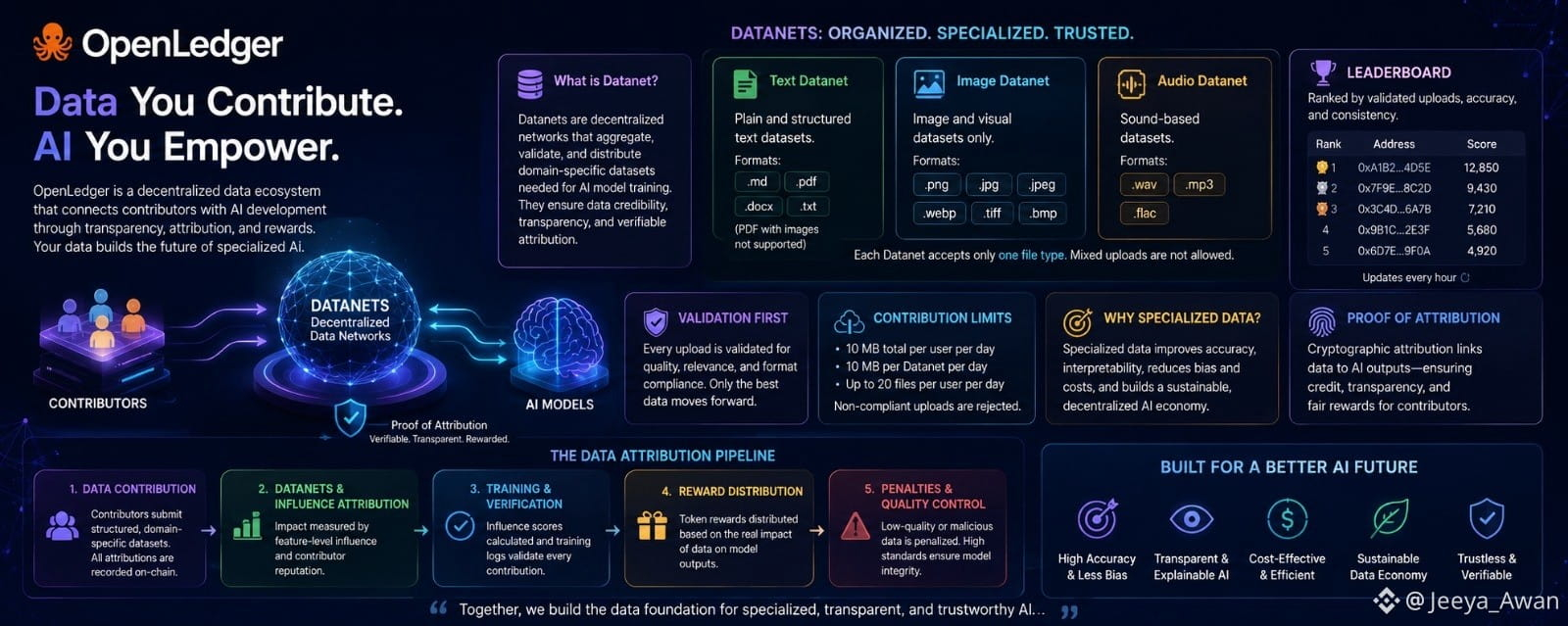
One thing I found especially interesting was the concept of Datanets. At first, I thought they were just simple storage systems for datasets, but after exploring more, I realized they are much more organized and purpose-driven. Datanets work like decentralized data hubs where contributors upload specialized datasets for training AI models. The platform focuses heavily on transparency, quality, and attribution, which creates a more trustworthy environment for AI development.
What impressed me most was how structured the contribution system is. Contributors can upload only one category of data per Datanet: text, image, or audio. This separation keeps datasets organized and useful for training domain-specific AI systems. Text Datanets support files like TXT, DOCX, PDF, and Markdown, while image-based Datanets accept formats such as PNG, JPG, and WEBP. Audio Datanets are designed for sound datasets in formats like MP3, WAV, and FLAC. I personally liked this approach because it avoids messy and mixed data collections that usually reduce AI model quality.
Another feature that stood out during my experience was the validation system. OpenLedger does not simply accept every upload automatically. Each file is checked for quality, relevance, structure, and compliance with the Datanet’s purpose. This creates a filtering mechanism that rewards useful data rather than random uploads. Files that fail the validation process are rejected, while approved contributions receive validation scores. In my opinion, this is one of the strongest parts of the ecosystem because AI models are only as good as the data used to train them.
The leaderboard system also adds an interesting competitive element. Contributors are ranked based on the quality and consistency of their validated uploads rather than simple quantity alone. I found this motivating because it encourages users to focus on meaningful contributions instead of spamming low-quality data. Since the rankings refresh regularly, active contributors always have a chance to improve their standing.
What truly changed my perspective was learning why specialized data matters so much in AI. General AI models often struggle with precision because they rely on broad datasets. OpenLedger focuses on domain-specific data, which helps AI systems become more accurate, transparent, and efficient. Specialized datasets can reduce bias, improve explainability, and lower computational costs. This approach feels more sustainable because it creates targeted intelligence instead of trying to make one model do everything.
The most innovative concept I discovered was Proof of Attribution. This mechanism connects data contributions directly to AI model outputs using cryptographic verification. In simple words, contributors can receive recognition and rewards based on how much their data influences an AI system. I think this is a powerful step toward fairness in the AI industry because data contributors are often ignored despite being essential to model development.
I also appreciated the way OpenLedger handles malicious or low-quality contributions. The platform includes penalties for biased, spammy, or harmful data. This creates a cleaner ecosystem where trustworthy information is prioritized. From my perspective, systems like this are important for the future of decentralized AI because they help maintain both quality and accountability.
Overall, my experience exploring OpenLedger gave me a different understanding of how AI ecosystems can become more transparent and community-driven. Instead of centralizing data ownership, the platform creates opportunities for contributors to actively participate in building specialized AI systems while being recognized for their role. It feels less like a traditional AI platform and more like a collaborative data economy designed for the future.
As AI continues to evolve, do you think decentralized platforms like OpenLedger could become the new standard for building transparent and trustworthy AI models?
